
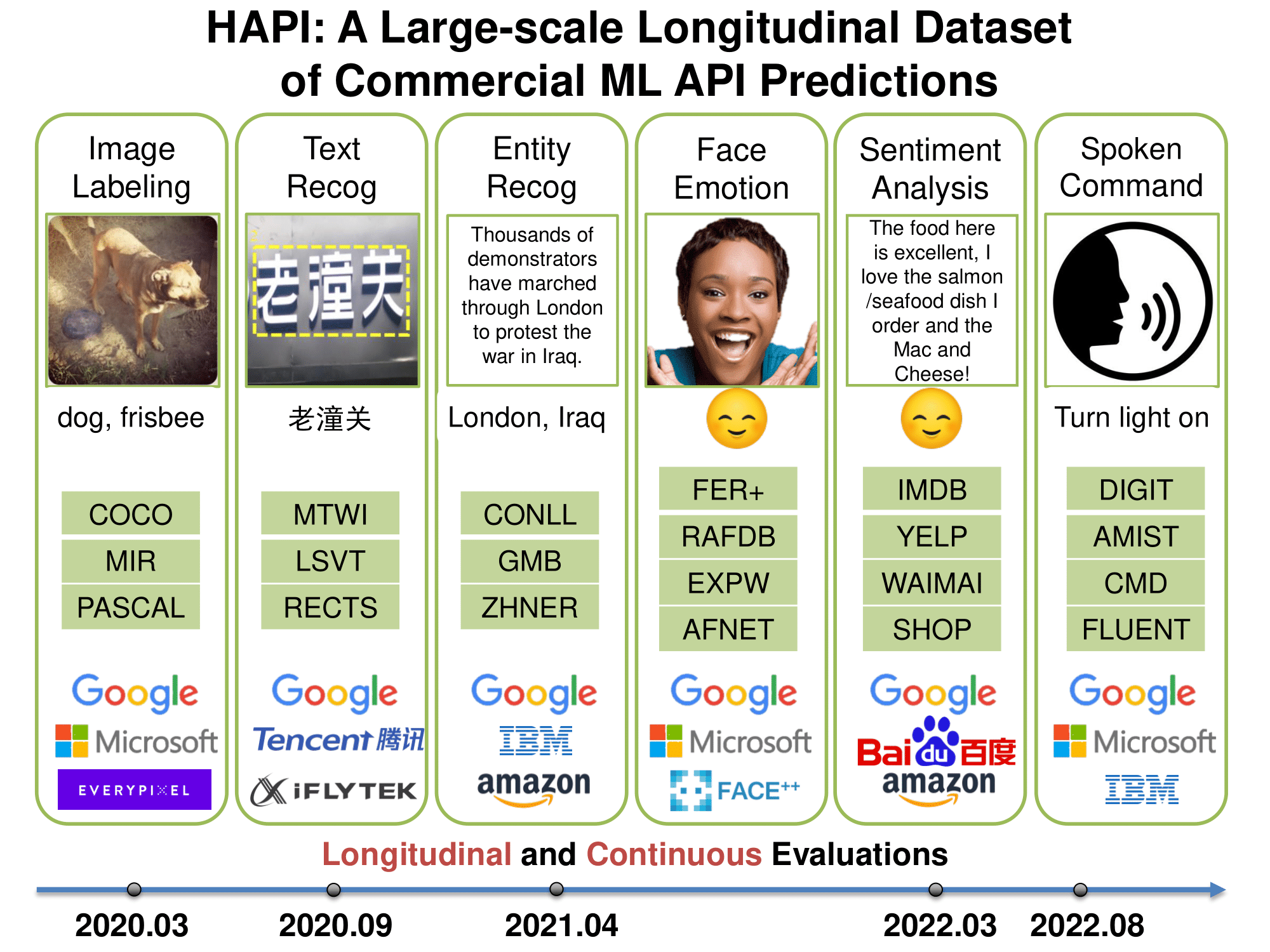
History of APIs (HAPI) is a large-scale, longitudinal database of commercial ML API predictions. It contains 1.7 million predictions collected from 2020 to 2022 and spanning APIs from Amazon, Google, IBM, and Microsoft. The database include diverse machine learning tasks including image tagging, speech recognition and text mining.
We provide a lightweight python package for getting started with HAPI.
Read the guide below or follow along in Google Colab:
pip install "hapi @ git+https://github.com/lchen001/hapi@main"Import the library and download the data, optionally specifying the directory for the
the download. If the directory is not specified, the data will be downloaded to ~/.hapi.
>> import hapi
>> hapi.config.data_dir = "/path/to/data/dir"
>> hapi.download()You can permanently set the data directory by adding the variable
HAPI_DATA_DIRto your environment.
Once we've downloaded the database, we can list the available APIs, datasets, and tasks with hapi.summary(). This returns a Pandas DataFrame with columns task, dataset, api, date, path, cost_per_10k.
>> df = hapi.summary()To load the predictions into memory we use hapi.get_predictions(). The keyword arguments allow us to load predictions for a subset of tasks, datasets, apis and/or dates.
>> predictions = hapi.get_predictions(task="mic", dataset="pascal", api=["google_mic", "ibm_mic"])The predictions are returned as a dictionary mapping from "{task}/{dataset}/{api}/{date}" to lists of dictionaries, each with keys "example_id", "predicted_label", and "confidence". For example:
{
"mic/pascal/google_mic/20-10-28": [
{
'confidence': 0.9798267782,
'example_id': '2011_000494',
'predicted_label': ['bird', 'bird']
},
...
],
"mic/pascal/microsoft_mic/20-10-28": [...],
...
}To load the labels into memory we use hapi.get_labels(). The keyword arguments allow us to load labels for a subset of tasks and datasets.
>> labels = hapi.get_labels(task="mic", dataset="pascal")The labels are returned as a dictionary mapping from "{task}/{dataset}" to lists of dictionaries, each with keys "example_id" and "true_label".
In this section, we discuss how to download the database without the HAPI Python API.
The database is stored in a GCP bucket named hapi-data. All model predictions are stored in hapi.tar.gz (Compressed size: 205.3MB, Full size: 1.2GB).
From the command line, you can download and extract the predictions with:
wget https://storage.googleapis.com/hapi-data/hapi.tar.gz && tar -xzvf hapi.tar.gz However, we recommend downloading using the Python API as described above.
In this section, we discuss how to download the benchmark datasets used in HAPI.
The predictions in HAPI are made on benchmark datasets from across the machine learning community. For example, HAPI includes predictions on PASCAL, a popular object detection dataset. Unfortunately, we lack the permissions required to redistribute these datasets, so we do not include the raw data in the download described above.
We provide instructions on how to download each of the datasets and, for a growing number of them, we provide automated scripts that can download the dataset. These scripts are implemented in the Meerkat Dataset Registry – a registry of machine learning datasets (similar to Torchvision Datasets).
To download a dataset and load it into memory, use hapi.get_dataset():
>> import hapi
>> dp = hapi.get_dataset("pascal")This returns a Meerkat DataPanel – a DataFrame-like object that houses the dataset. See the Meerkat User Guide for more information. The DataPanel will have an "example_id" column that corresponds to the "example_id" key in the outputs of hapi.get_predictions() and hapi.get_labels().
If the dataset is not yet available through the Meerkat Dataset Registry, a ValueError will be raised containing instructions for manually downloading the dataset. For example:
>> dp = hapi.get_dataset("cmd")
ValueError: Data download for 'cmd' not yet available for download through the HAPI Python API. Please download manually following the instructions below:
CMD is a spoken command recognition dataset.
It can be downloaded here: https://pyroomacoustics.readthedocs.io/en/pypi-release/pyroomacoustics.datasets.google_speech_commands.html.HAPI was developed at Stanford in the Zou Group. Reach out to Lingjiao Chen (lingjiao [at] stanford [dot] edu) and Sabri Eyuboglu (eyuboglu [at] stanford [dot] edu) if you would like to get involved!