Improve Consistency of Logging and Actions in peerTerminationWatcher #433
Conversation
c020dce to
a20ab99
Compare
|
@cfromknecht I am seeing an issue where my nodes peer count eventually goes to zero. When this happens it stops receiving updates and I have to restart the lnd process to get peers again. Will this PR solve this loss of peers issue? I will pull from you and test. |
|
@bajohns is the node you're testing on persistent? Is it listening on a publicly reachable interface? Also, what do you mean by "stops receiving updates"? Does the node have any active channels, or is it just bootstrapping to new peers? Finally, what commit are you on? |
|
@Roasbeef the node I am using is persistent - I run it 24/7. If persistent is a setting then see my cli options below. It is not on a publicly reachable interface nor does it have active channels. Unfortunately, I just pulled/rebased onto master yesterday in hope that the issue would resolve. Now I am running off of 7016f5b. Re "Stops receiving updates": The daemon appears to take in two streams of info. Lightning P2P and Bitcoin chain info from Neutrino. I have not had any issues with Neutrino. However, over the course of 24-32 hours I hit 0 lightning peers Now I am running off 7016f5b with this PR merged to see if the situation improves. However, test net seems to have re-org'd in the last 24 hours and that causes some instability (Maybe faucet.lightning.community was down?). Regardless, I will test another 24 hours and report back. |
|
The last twenty-four hours of testing are unclear and different from prior experience. Before, the daemon appeared to be disconnected from Lightning P2P and received block updates but not channel updates. After applying this PR the node appears to stay connected to Lightning P2P but become disconnected from the remote neutrino. I am not sure if this related to the PR or is separate. @Roasbeef Perhaps I should make an issue to discuss further? Short summary: To generate this graph I created a branch of LND that outputs and event log and piped this to an ELK stack instance. My next step will be to move LND to an IP that is publicly reachable and run a local btcd to attempt to eliminate that as a factor.
|
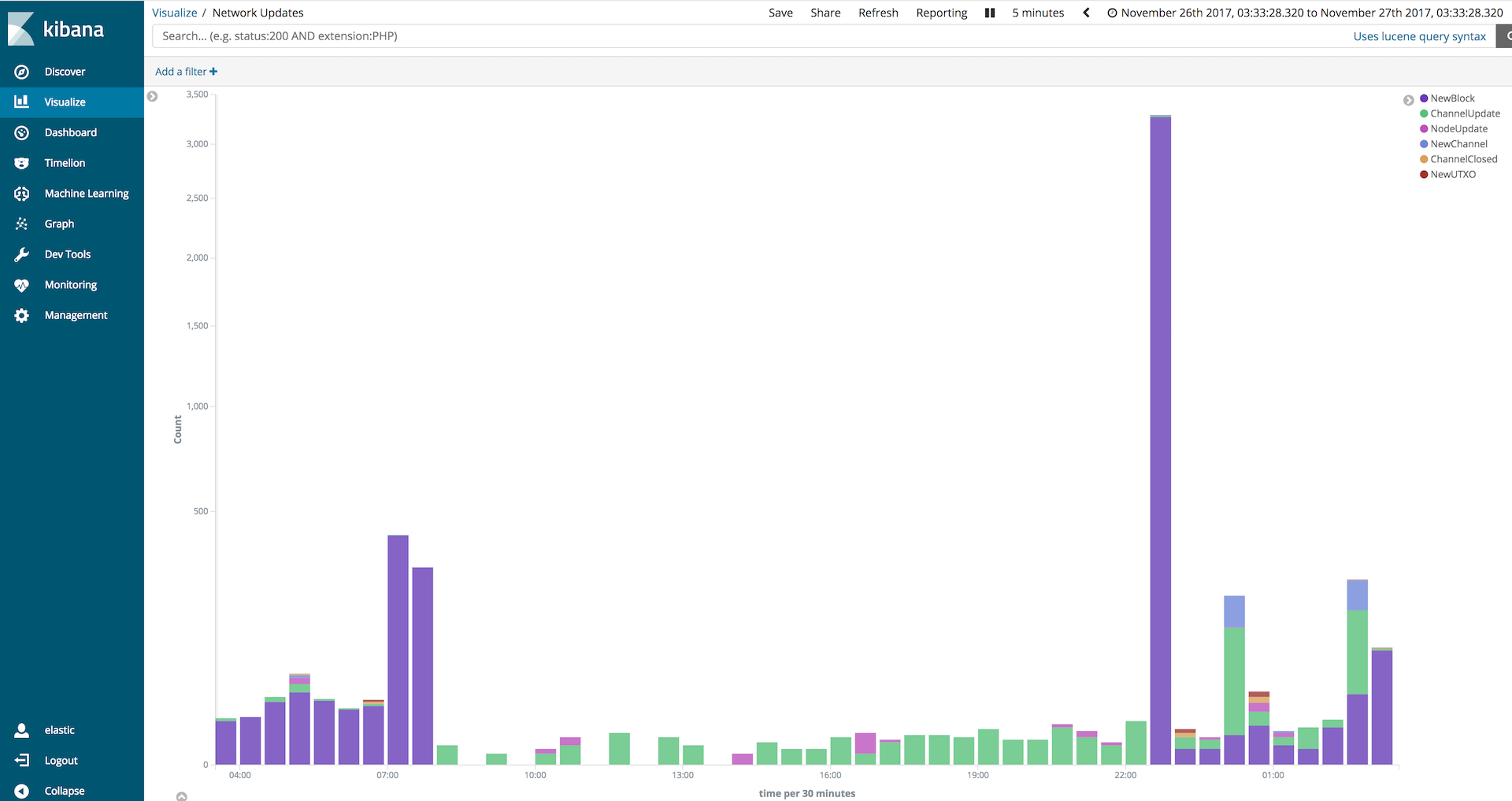
|
@bajohns thanks for your thorough investigation on this! This PR should only affect the connections maintained in the Lightning P2P network, and should have no effect on neutrino (that I'm aware of). There might be certain conditions under which this PR helped the connectivity with the P2P network in your most recent test, though @Roasbeef has some other hunches about what may have caused this. Primarily, the connections made by the DNS bootstrapper are not registered as persistent. In this case, persistent means that lnd will try to reestablish them if they fail, not necessarily that they will be persisted to disk or anything. In order to prevent what happened on day one, the best two solutions seem to be:
In regards to day 2, it seems more likely that this was caused by a reorg or huge increase in hash rate. You can see the number of new blocks increases sharply, just before stopping all together, and the number of new blocks accepted after restarting would give an average rate of ~200 blocks/hr while the node wasn't receiving updates. In fact, I just checked yesterday's blocks and that seems to be the case 😊 By the way, really cool work in getting this graph generated! Will have to check this out 😎 |
a20ab99 to
8298aa0
Compare
pconn/connmanager.go
Outdated
There was a problem hiding this comment.
On second thought, perhaps we can just apply the OG patch (the one I started, but you fixed) to my fork, which will then eventually be submitted back upstream to btcd. This way, it will actually also be possible to review the added diff. As currently presented, it's difficult to see exactly how the original connmgr package was modified.
There was a problem hiding this comment.
It would also significantly shrink the size of this diff!
There was a problem hiding this comment.
Bulk of the PR has been moved to Roasbeef/btcd#10, thinking this PR will just become the glide update/minor fixes?
|
@cfromknecht I am interested to work on the solution 2 you presented above. If you can create an issue with instructions I will get started. The graph you saw is from a hobby project of mine; I will send you a link once I launch it. |
38f59f4 to
4604b87
Compare
glide.yaml
Outdated
There was a problem hiding this comment.
temporary redirection until merged into roasbeef/btcd
There was a problem hiding this comment.
was hoping this would work on travis, but it only works locally due to the btcd setup done by gotest.sh
4604b87 to
ea3f65b
Compare
ea3f65b to
516c3be
Compare
This commit reorders logic in the peer termination watcher such that we short circuit earlier if we already have pending persistent connection requests. Before, the debug statement may have indicated that a reconnection was being attempted, even though it may have exited before submitting the request to the connection manager.
516c3be to
9713cd8
Compare
This PR reorders logic in the peer termination watcher such that we short circuit earlier if we already have pending persistent connection requests. Before, the debug statement may have indicated that a reconnection was being attempted, even though it may have exited before submitting the request to the connection manager.