![]()
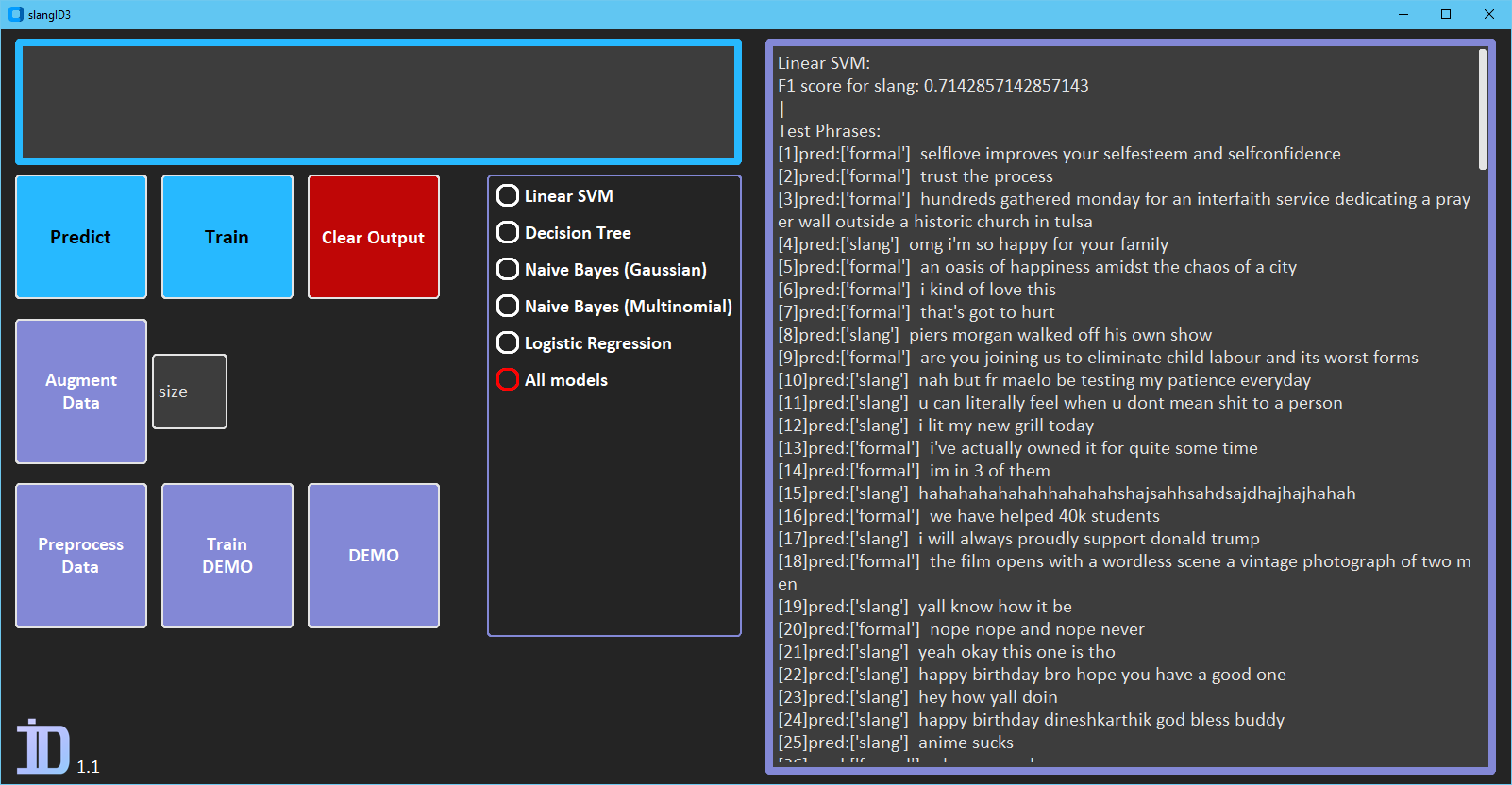
You can train a selection of classifiers, and print out a test set of phrases with the DEMO button.
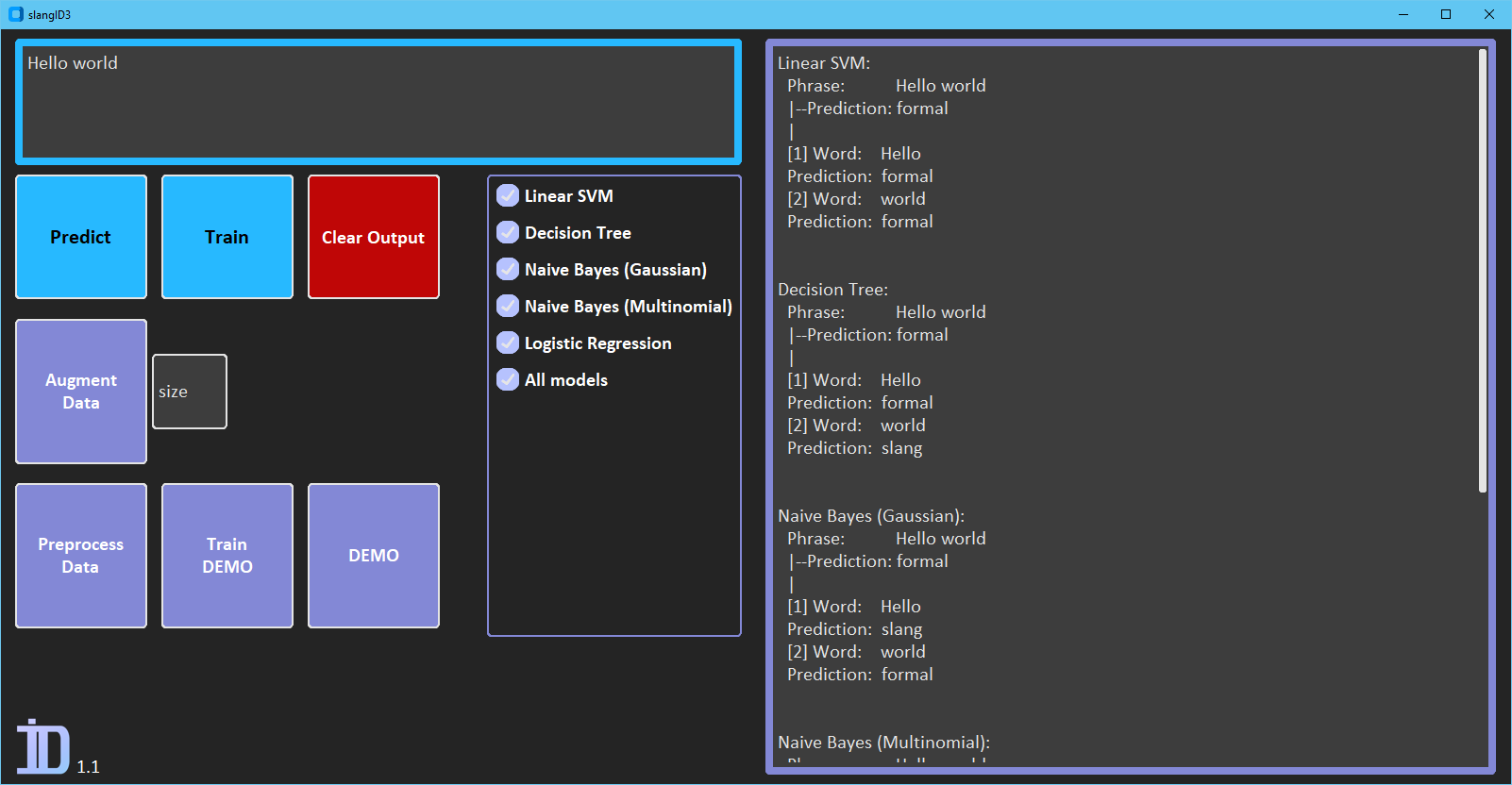
Or you can pass a phrase and see what type it, and the individual words are identified as. All the models are pre-trained, but you can re-train if needed.
- New GUI with a modern look
- Integrated output window
- Data Augmentation to obtain larger data artificially (currently very limited)
- Individual word evaluation
- New data formatting
- New preprocessing
-
Download the latest slangID3.exe and the source code files in releases.
-
Unzip the source code file.
-
Move slangID3.exe to the unzipped folder.
or
-
Install Python 3.10 or newer.
-
Install the required packages by running
pip install -r requirements.txtin your shell of choice. Make sure you are in the project directory.
-
Run
python slangID3.py
Note: It might take a while to load. Be patient.
You can predict with the included pre-trained models, and re-train if needed.
Preprocessing is the last step before training a model.
If you want to use the original dataset data.csv or the augmented dataset augmented_data.csv, use the preprocessing function before training.
In total, there are five models you can choose from (for now):
- Linear SVM (SVC with linear Kernel)
- Decision Tree
- Gaussian Naive Bayes
- Multinomial Naive Bayes
- Logistic Regression
Currently the best performer is the Linear SVM model with an F1 score of 71.4% (on the test set, with the original training data)
The training dataset is still too small, resulting in overfitting (after augmentation).
I categorized the slang words as:
- <pex> personal expressions
- dude, one and only, bro
- <n> singular nouns
- shit
- <npl> plural nouns
- crybabies
- <shnpl> shortened plural nouns
- ppl
- <mwn> multiword nouns
- certified vaccine freak
- <mwexn> multiword nominal expressions
- a good one
- <en> exaggerated nouns
- guysssss
- <eex> (exaggerated) expressions
- hahaha, aaaaaah, lmao
- <adj> adjectives
- retarded
- <eadj> exaggerated adjectives
- weirdddddd
- <sha> shortened adjectives
- on
- <shmex> shortened (multiword) expressions
- tbh, imo
- <v> infinitive verb
- trigger
(not all tags are available due to the small dataset)
The preprocessing script removes the slang tags, brackets, hyphens, and converts everything to lowercase.
Most of the phrases come from archive.org's Twitter Stream of June 6th.
- scikit-learn
- customtkinter
- pandas
- tqdm
- pyinstaller