![]()
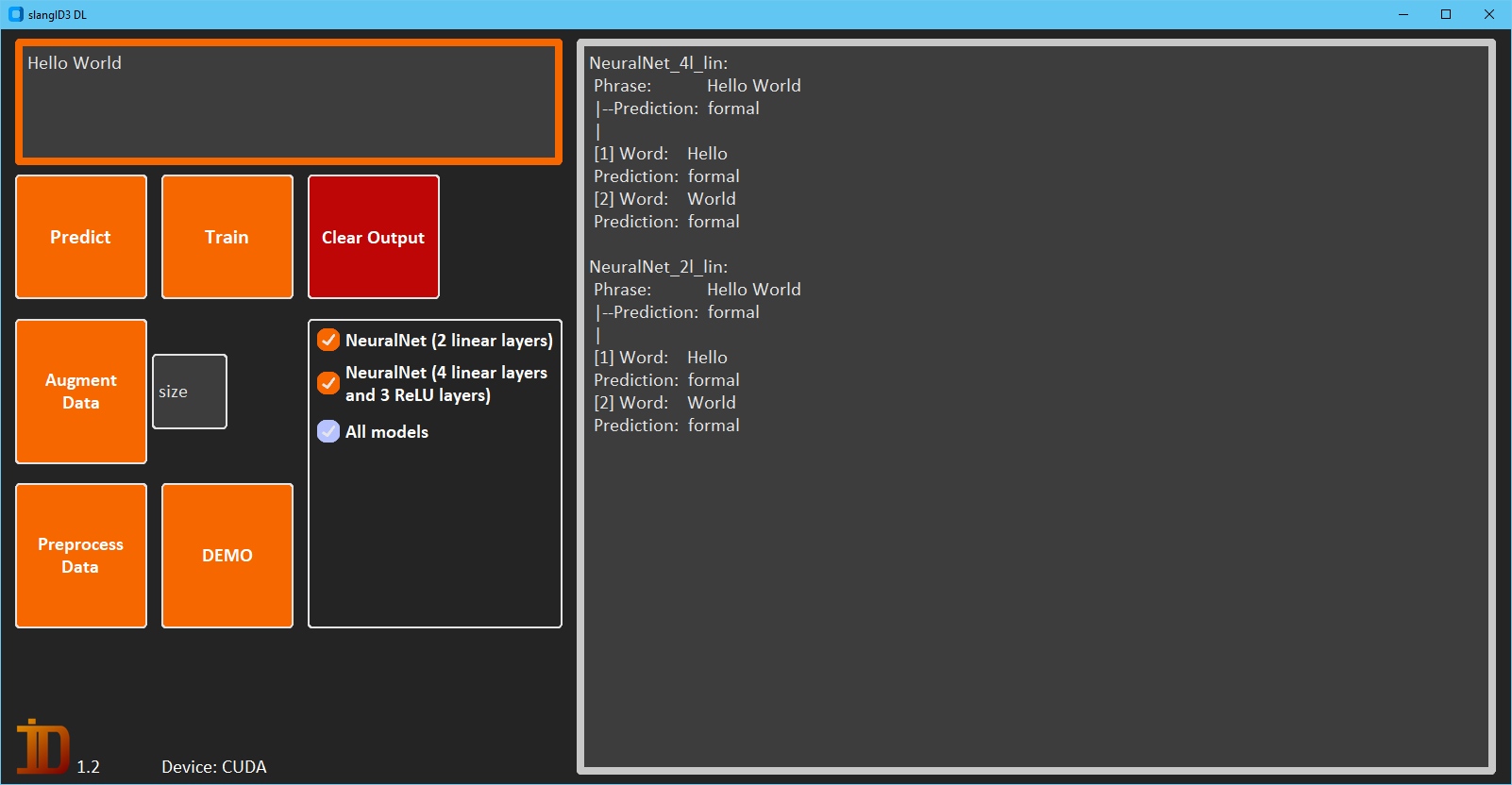
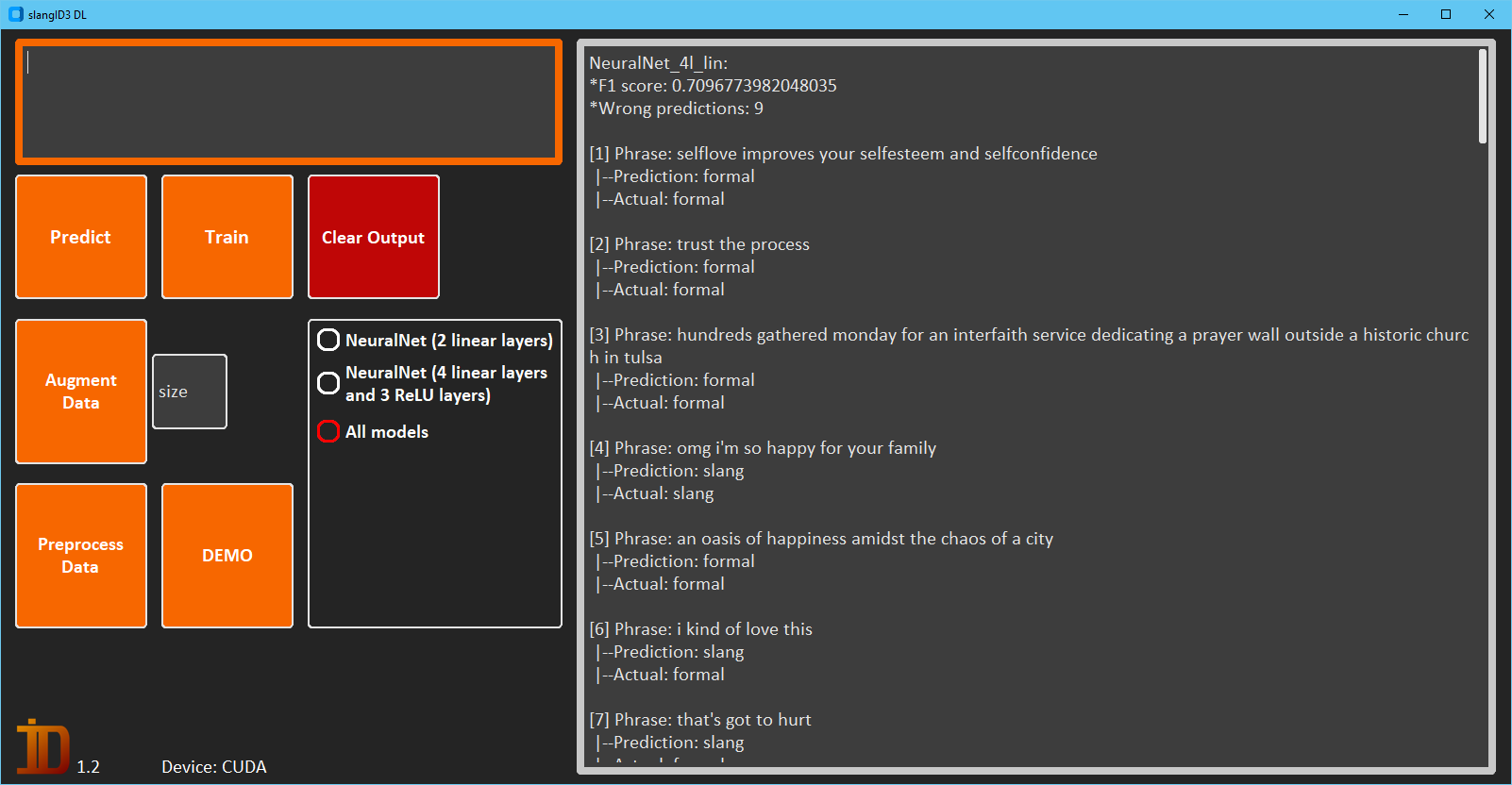
You can train a selection of classifiers, and print out a test set of phrases with the DEMO button.
Or you can pass a phrase and see what type it, and the individual words are identified as. All the available models are pre-trained, but you can re-train if needed.
-
Install Python 3.10 or newer.
-
Clone the repository with
git clone https://github.com/m4cit/slangID3_DL.gitor download the latest source code.
-
Install PyTorch.
3.1 Either with CUDA
- Windows:
pip3 install torch==2.2.2 --index-url https://download.pytorch.org/whl/cu121 - Linux:
pip3 install torch==2.2.2
3.2 Or without CUDA
- Windows:
pip3 install torch==2.2.2 - Linux:
pip3 install torch==2.2.2 --index-url https://download.pytorch.org/whl/cpu
- Windows:
-
Navigate to the slangID3_DL main directory.
cd slangID3_DL -
Install dependencies.
pip install -r requirements.txt -
Run
python slangID3_DL.py
Note: It might take a while to load. Be patient.
You can predict with the included pre-trained models, and re-train if needed.
Preprocessing is the last step before training a model.
If you want to use the original dataset data.csv after some changes, or the augmented dataset augmented_data.csv, use the preprocessing function before training.
There is currently two models available:
- NeuralNet_2l_lin: Neural Network with 2 linear layers
- NeuralNet_4l_relu_lin: Neural Network with 4 linear layers and 3 ReLU layers
The best F1 score is ~71.4% with model NeuralNet_2l_lin
Note: Score on the test set with the best parameters within 100 epochs of training, with the original training data.
- The training dataset is still too small, resulting in overfitting (after augmentation).
- Reproducibility is an issue with regard to training.
The preprocessing script removes the slang tags, brackets, hyphens, and converts everything to lowercase.
I categorized the slang words as:
- <pex> personal expressions
- dude, one and only, bro
- <n> singular nouns
- shit
- <npl> plural nouns
- crybabies
- <shnpl> shortened plural nouns
- ppl
- <mwn> multiword nouns
- certified vaccine freak
- <mwexn> multiword nominal expressions
- a good one
- <en> exaggerated nouns
- guysssss
- <eex> (exaggerated) expressions
- hahaha, aaaaaah, lmao
- <adj> adjectives
- retarded
- <eadj> exaggerated adjectives
- weirdddddd
- <sha> shortened adjectives
- on
- <shmex> shortened (multiword) expressions
- tbh, imo
- <v> infinitive verb
- trigger
(not all tags are available due to the small dataset)
Most of the phrases come from archive.org's Twitter Stream of June 6th.
- PyTorch
- scikit-learn
- customtkinter
- pandas
- numpy
- tqdm