These data sets are constructed to use with COREML 2 tools.
It consists of data from the two infamous data sets:
- 1-training.1600000.processed.noemoticon.csv via https://www.kaggle.com/datasets/kazanova/sentiment140
- 2-judge_1377884607_tweet_product_company via https://github.com/lspope/vader_textblob_experiment/find/main
Labels and quantities:
- Neg 4154
- Pos 4154
- Neutral 4153
It is constructed using the same stated datasets
Labels and quantities:
- Neg 1000
- Pos 1000
- Neutral 1000
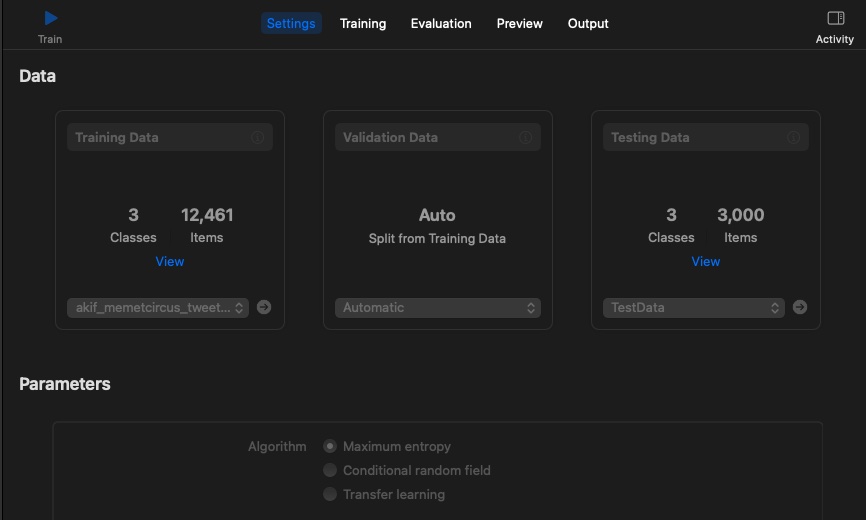
- Trained using maximum-entropy
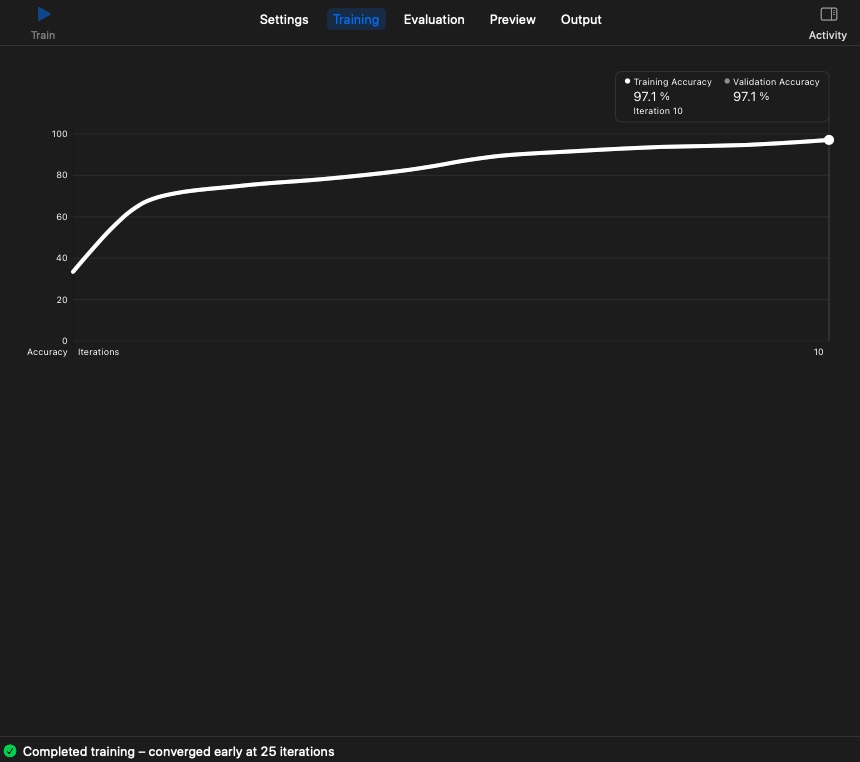
- Completed Training
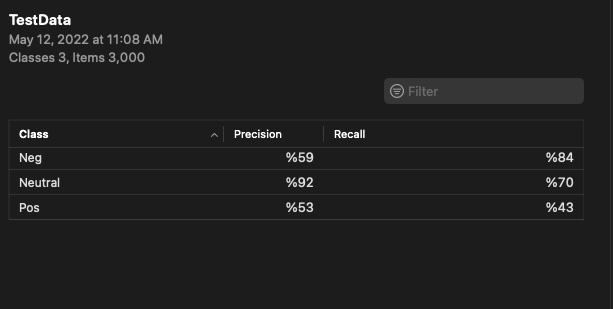
- The Results