The goal of this project is to build a data processing pipeline that extracts information about new users every minute from an API, transforms the data and stores it in a Postgres database.
- Understand how to use python libraries (Psycopg2) to interact with databases;
- Understand how to use JSON schema validation in order to perform data quality checks;
- Build an Airflow DAG and understand how to orchestrate a batch processing pipeline and connect to external sources;
- Setup a docker container that contains all dependencies needed for the project (Airflow webserver, scheduler, worker, Postgres DB etc);
- Understand how to use unittesting python libraries (Unittest) to perform automated testing;
The data used in this project is pulled from the following API: https://randomuser.me/. This is a free, open-source API for generating random user data.

The source data for the processing pipeline is pulled from the following API: https://randomuser.me/ in .json format. The .json data will be read by the local python script and validated using a standard JSON schema. Afterwards, the data will be written to a .csv file.
Postgres is an open source object-relational database system that acts as an OLTP database in this project. Data from the .csv file is loaded in Postgres using a 'COPY' command.
Apache Airflow is used to orchestrate this data pipeline.

The Airflow DAG is tested using the following unittests:
- Check the name and the number of tasks;
- Check the default args used in the DAG;
- Check the schedule interval;
- Check the start date;
Data is pulled from an API every minute in a .json format. After the JSON schema is validated, the data is written to a .csv file which is then copied to a Postgres database. This DAG is scheduled using Airflow and tested using automated unittests.
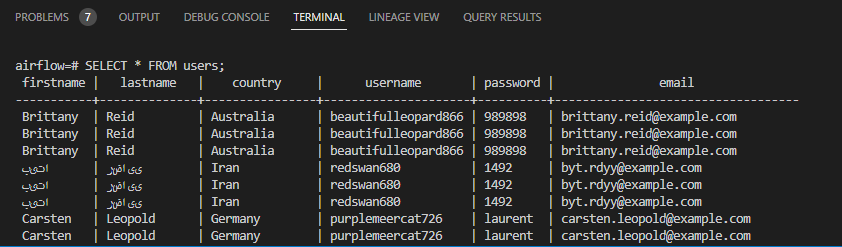
Through the completion of this project, I have gained experience in processing .json files, performing JSON schema validations and using Airflow & Docker. This hands-on experience has enabled me to develop a deeper understanding of Airflow and its capabilities for scheduling data pipelines. As a result of this project, I have gained the confidence and competence to effectively schedule DAGs using Airlfow, as well as interacting with databases using python libraries.