Update _sha512.py #477
Update _sha512.py #477
Conversation
refactoring code with var unpack which is more pythonic, concise, readable and efficient
|
Unpacking args requires extra memory allocation behind the scenes, which can be undesirable in some cases (e.g. can lead to memory fragmentation). |
|
Thank you @dlech. I am not very clear about the extra memory allocation. Would you like to explain why there is extra memory allocation? Is it slice or something?
|
|
It creates a tuple object. |
|
Thank you. Yes, however, when I test it, the print is weird, it shows no difference about memory usage. The output is: |
|
It looks like you performed the test using Python, not MicroPython. CPython uses reference counting, so all of the implicit tuple and slice objects are most likely freed by the time the method returns. Also you would have to allocate at least 100KiB in order for anything to show up when the memory is being measured in MiB with one decimal place. |
|
Thank you. However, I am a little confused because when I set breakpoints for the two lines of code ( |
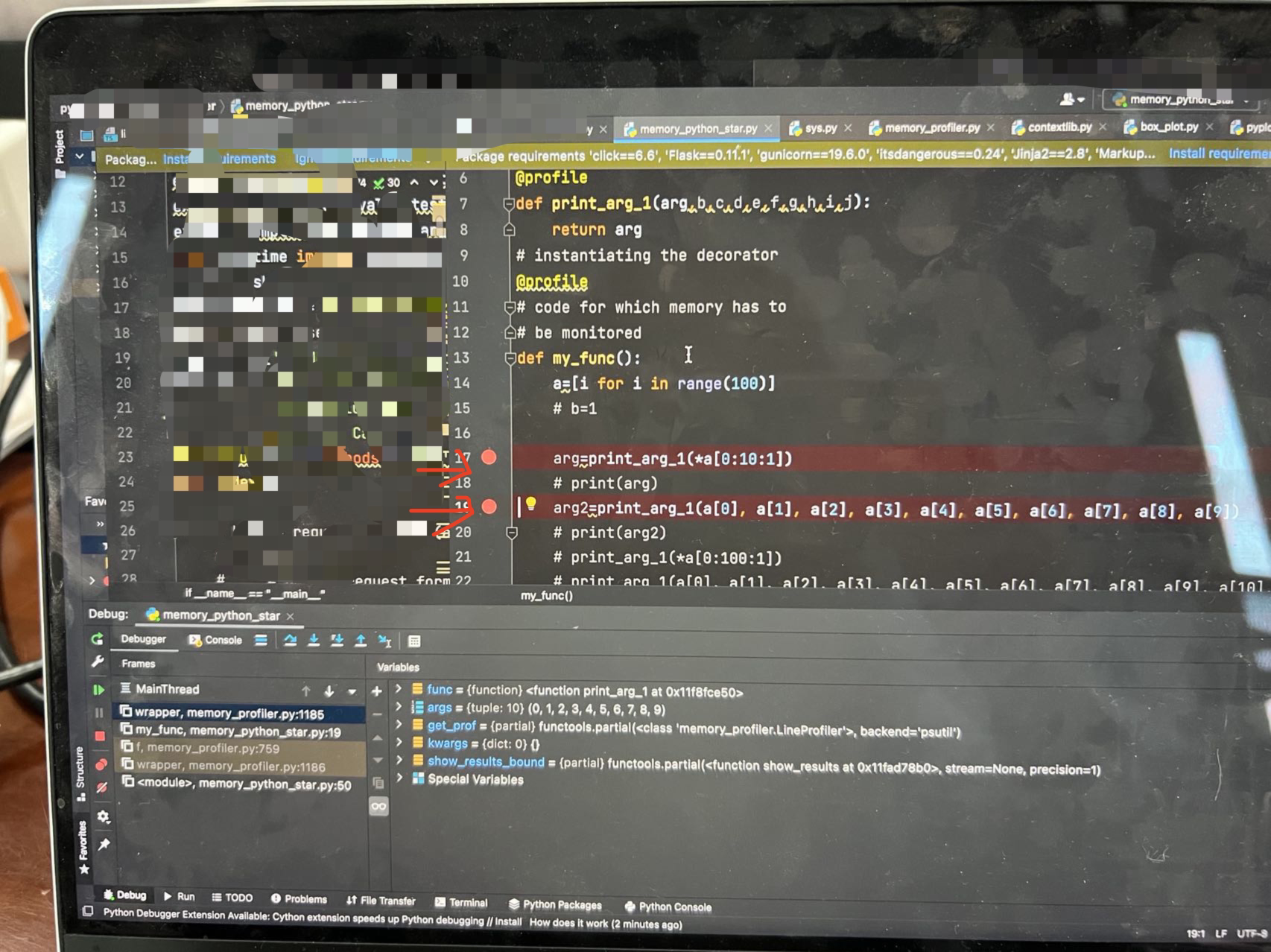
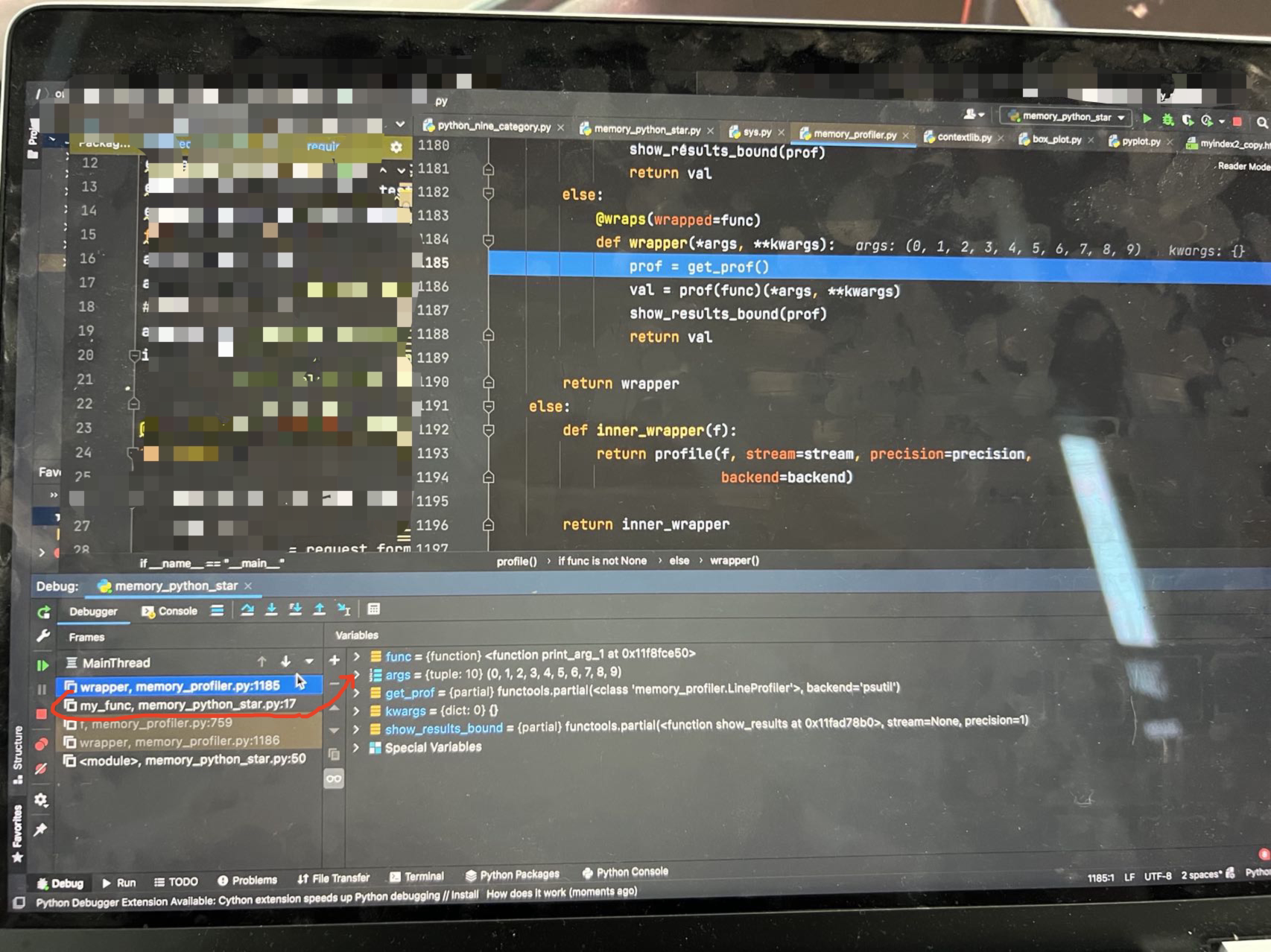
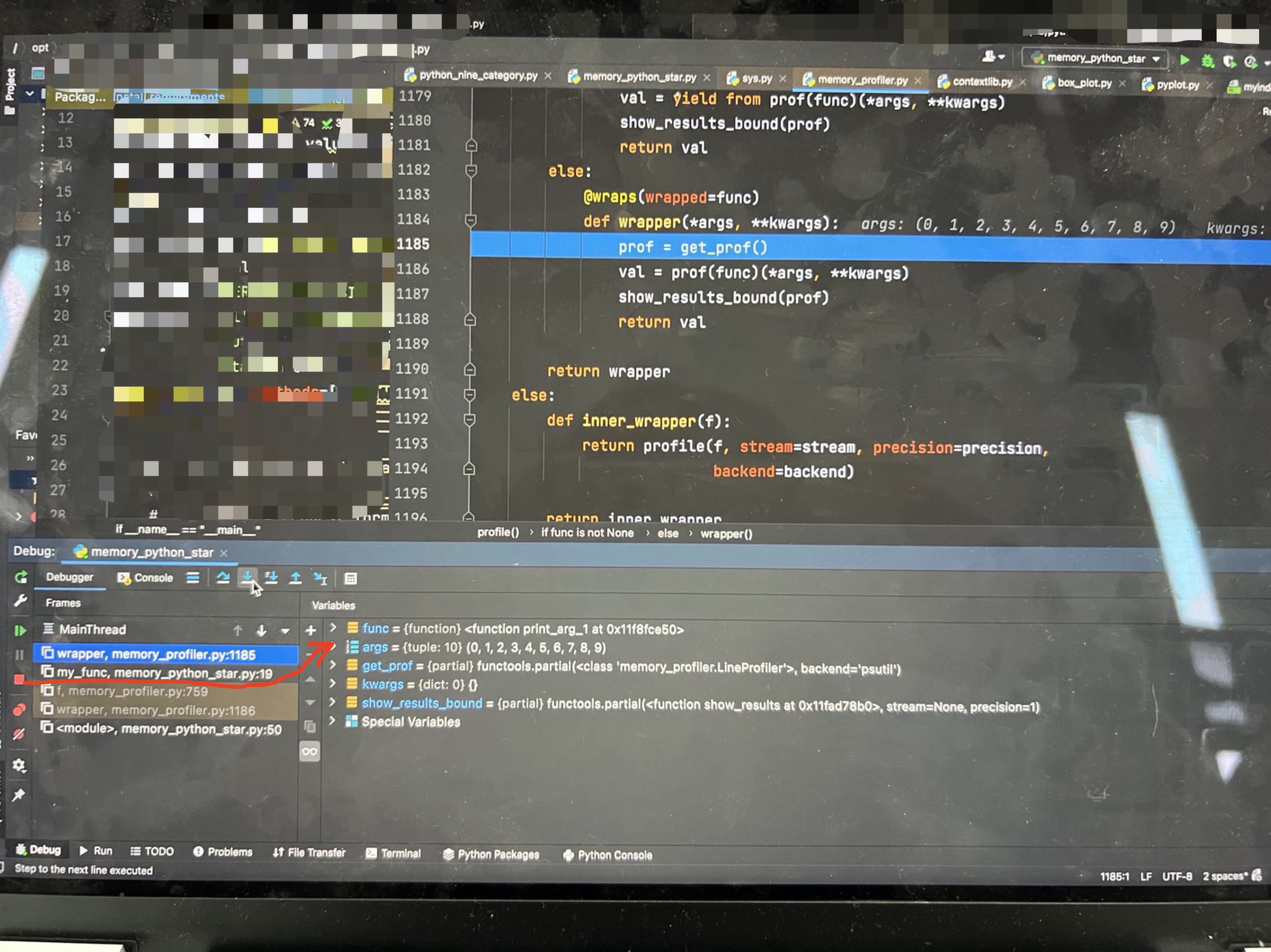
|
Doing a slice like |
refactoring code with var unpack which is more pythonic, concise, readable and efficient; how do think this change which has practical value?