{kind=link}
![]()
![]()



scikit-explain is a user-friendly Python module for tabular-style machine learning explainability. Current explainability products includes
-
Feature importance:
- Single- and Multi-pass Permutation Importance (Brieman et al. 2001], Lakshmanan et al. 2015)
- SHAP
- First-order PD/ALE Variance (Greenwell et al. 2018)
- Grouped permutation importance (Au et al. 2021)
- Tree Interpreter (Saabas 2014)
-
Feature Effects/Attributions:
- Partial Dependence (PD),
- Accumulated local effects (ALE),
- Random forest-based feature contributions (treeinterpreter)
- SHAP
- LIME
- Main Effect Complexity (MEC; Molnar et al. 2019)
- Tree Interpreter (Saabas 2014)
-
Feature Interactions:
- Second-order PD/ALE
- Interaction Strength and Main Effect Complexity (IAS; Molnar et al. 2019)
- Second-order PD/ALE Variance (Greenwell et al. 2018)
- Second-order Permutation Importance (Oh et al. 2019)
- Friedman H-statistic (Friedman and Popescu 2008)
- Sobol Indices
These explainability methods are discussed at length in Christoph Molnar's Interpretable Machine Learning. The primary feature of this package is the accompanying built-in plotting methods, which are desgined to be easy to use while producing publication-level quality figures. The computations do leverage parallelization when possible. Documentation for scikit-explain can be found at Read the Docs.
The package is under active development and will likely contain bugs or errors. Feel free to raise issues!
This package is largely original code, but also includes snippets or chunks of code from preexisting packages. Our goal is not take credit from other code authors, but to make a single source for computing several machine learning explanation methods. Here is a list of packages used in scikit-explain: PyALE, PermutationImportance, ALEPython, SHAP, scikit-learn, LIME, Faster-LIME, treeinterpreter
If you employ scikit-explain in your research, please cite this github and the relevant packages listed above.
If you are experiencing issues with loading the tutorial jupyter notebooks, you can enter the URL/location of the notebooks into the following address: https://nbviewer.jupyter.org/.
scikit-explain can be installed through conda-forge or pip.
conda install -c conda-forge scikit-explain
pip install scikit-explain
For the most up-to-date version of scikit-explain, you can install it from the source code. The commands given below are executable from the command line.
git clone https://github.com/monte-flora/scikit-explain/
cd scikit-explain
python setup.py install
scikit-explain is compatible with Python 3.8 or newer. scikit-explain requires the following packages:
numpy
scipy
pandas
scikit-learn
matplotlib
shap>=0.30.0
xarray>=0.16.0
tqdm
statsmodels
seaborn>=0.11.0
Scikit-explain has built-in saving and loading function for pandas dataframes and xarray datasets. Datasets are saved in netCDF4 format. To use this feature, install netCDF4 with one of the following: pip install netCDF4 or conda install -c conda-forge netCDF4
The interface of scikit-explain is ExplainToolkit, which houses all of the explainability methods and their corresponding plotting methods. See the tutorial notebooks for examples.
import skexplain
# Loads three ML models (random forest, gradient-boosted tree, and logistic regression)
# trained on a subset of the road surface temperature data from Handler et al. (2020).
estimators = skexplain.load_models()
X,y = skexplain.load_data()
explainer = skexplain.ExplainToolkit(estimators=estimators,X=X,y=y,)scikit-explain includes both single-pass and multiple-pass permutation importance method (Brieman et al. 2001], Lakshmanan et al. 2015, McGovern et al. 2019). The permutation direction can also be given (i.e., backward or forward). Users can also specify feature groups and compute the grouped permutation feature importance (Au et al. 2021). Scikit-explain has a function that allows for any feature ranking to be converted into a format for using the plotting package (skexplain.common.importance_utils.to_skexplain_importance). In the tutorial, users have flexibility for making publication-quality figures.
perm_results = explainer.permutation_importance(n_vars=10, evaluation_fn='auc')
explainer.plot_importance(data=perm_results)

Sample notebook can be found here: Permutation Importance
To compute the expected functional relationship between a feature and an ML model's prediction, scikit-explain has partial dependence, accumulated local effects, or SHAP dependence. There is also an option for second-order interaction effects. For the choice of feature, you can manually select or can run the permutation importance and a built-in method will retrieve those features. It is also possible to configure the plot for readable feature names.
# Assumes the .permutation_importance has already been run.
important_vars = explainer.get_important_vars(results, multipass=True, nvars=7)
ale = explainer.ale(features=important_vars, n_bins=20)
explainer.plot_ale(ale)

Additionally, you can use the same code snippet to compute the second-order ALE (see the notebook for more details).

Sample notebook can be found here:
To explain individual examples (or set of examples), scikit-explain has model-agnostic methods like SHAP and LIME and model-specific methods like tree interpreter (for decision tree-based model from scikit-learn). For SHAP, scikit-explain uses the shap.Explainer method, which automatically determines the most appropriate Shapley value algorithm (see their docs). For LIME, scikit-explain uses the code from the Faster-LIME method. scikit-explain can create the summary and dependence plots from the shap python package, but is adapted for multiple features and an easier user interface. It is also possible to plot attributions for a single example or summarized by model performance.
import shap
single_example = examples.iloc[[0]]
explainer = skexplain.ExplainToolkit(estimators=estimators[0], X=single_example,)
# For the LIME, we must provide the training dataset. We also denote any categorical features.
lime_kws = {'training_data' : X.values, 'categorical_names' : ['rural', 'urban']}
# The masker handles the missing features. In this case, we are using correlations
# in the dataset to determine the feature groupings. These groups of features are remove or added into
# sets together.
shap_kws={'masker' : shap.maskers.Partition(X, max_samples=100, clustering="correlation"),
'algorithm' : 'permutation'}
# method can be a single str or list of strs.
attr_results = explainer.local_attributions(method=['shap', 'lime', 'tree_interpreter'], shap_kws=shap_kws, lime_kws=lime_kws)
fig = explainer.plot_contributions(results)
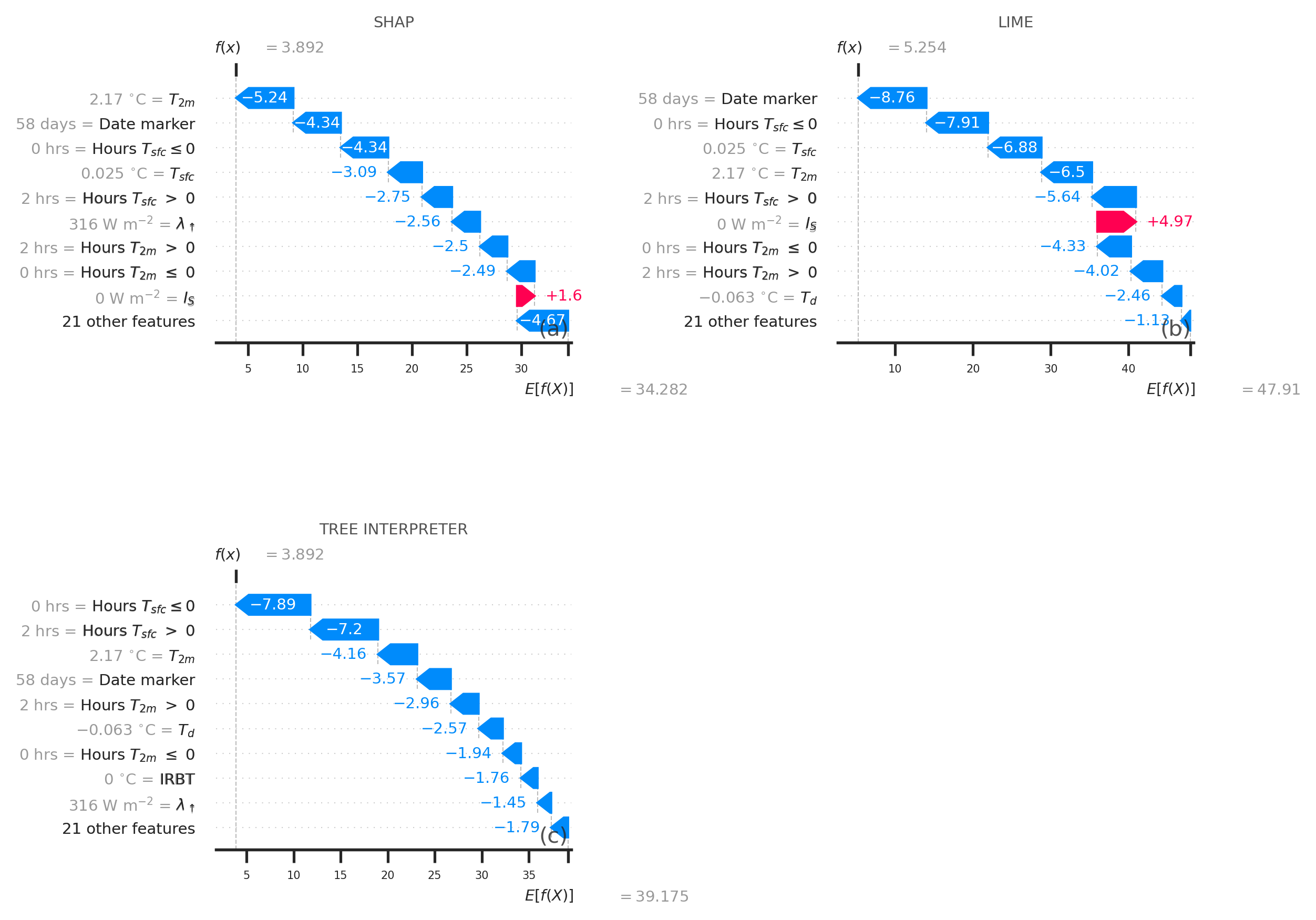
explainer = skexplain.ExplainToolkit(estimators=estimators[0],X=X, y=y)
# average_attributions is used to average feature attributions and their feature values either using a simple mean or the mean based on model performance.
avg_attr_results = explainer.average_attributions(method='shap', shap_kwargs=shap_kwargs, performance_based=True,)
fig = myInterpreter.plot_contributions(avg_attr_results)

explainer = skexplain.ExplainToolkit(estimators=estimators[0],X=X, y=y)
attr_results = explainer.local_attributions(method='lime', lime_kws=lime_kws)
explainer.scatter_plot(plot_type = 'summary', dataset=attr_results)

from skexplain.common import plotting_config
features = ['tmp2m_hrs_bl_frez', 'sat_irbt', 'sfcT_hrs_ab_frez', 'tmp2m_hrs_ab_frez', 'd_rad_d']
explainer.scatter_plot(features=features,
plot_type = 'dependence',
dataset=dataset,
display_feature_names=plotting_config.display_feature_names,
display_units = plotting_config.display_units,
to_probability=True)

Sample notebook can be found here:
The notebooks provides the package documentation and demonstrate scikit-explain API, which was used to create the above figures. If you are experiencing issues with loading the jupyter notebooks, you can enter the URL/location of the notebooks into the following address: https://nbviewer.jupyter.org/.