Upgrade to Lezer system 1.0.0 #18
Conversation
|
If I move conflicting prefixed terms out of the then inconsistency moves around the ignore next form: If I remove |
|
Notes on a minimal grammar which reproduces issue #16. Build with but not building in @lezer/generator 1.0.0 with error where the offending expression is |
|
Asked in Lezer-discussion. |
|
Given @marijnh's answer, I think maybe we shouldn't handle reader tags as expressions (
which doesn't seem right. Maybe we should introduce a compound seem to comply with latest lezer |
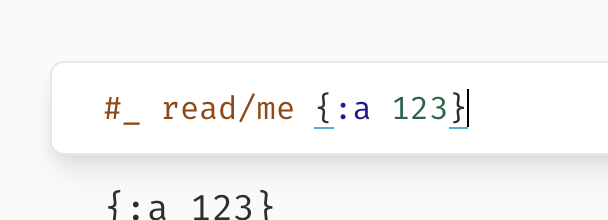
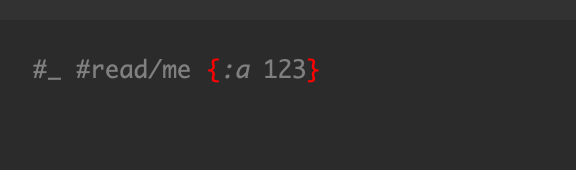
This upgrades to lezer to 1.0.0.
We also move the package name to
@lezer/clojureto be consistent with how other grammars are now published.Remove the constructor call syntax to work around the
Inconsistent skip sets after "#" identerror.Closes #13, closes #14 and closes #15. Fixes #16.