QLearning
Q-learning (section 21.2.3 of AIMA) is a type of temporal difference Reinforcement Learning that uses a value function to pick the best action. In this demo, a Q-Learning agent leans to navigate the maze from experience: It learns how likely each possible move (north, south, west, east) at each location of the maze is to lead to the goal. The video below shows how it works; you can also run OpenNERO yourself to test it interactively.
To run the demo,
- start OpenNERO
- Start the Reinforcement Learning Experiment
- Select the method you want to run from the pull-down menu: 1. Q-learning (Coarse) runs the coarse-grained (easy) version 1. Q-learning (Fine) runs the fine-grained (more difficult) version 1. First Person Coarse/Fine allows you to solve the maze yourself
- Click on the Start button to start the demo
You can also
- Click Pause to temporarily suspend the method
- Click Reset to terminate the method
- Click New Maze to try again with a different maze
- Use the Explore-Exploit slider (that appears once you start the Q-learning agent) to adjust the fraction of the actions taken to explore the environment (i.e. randomly selected actions) vs. actions taken greedily (i.e. those with the best Q-values.)
- Use the Speedup slider to run the visualization faster or slower
- Use the Starting Offset slider to control the spawn location of the agent at the beginning of new episodes.
- Use the keyboard controls described in the Running OpenNERO page to move around in the environment.
The details of each method are described below.
In the coarse-grained version, the maze consists of 8x8 discrete locations. At each location, the agent can select from four actions: North, south, west, and east. The agent receives a reward of 100 on the final move when it reaches the goal and a reward of -1 when it moves from a cell to another cell that is not the goal. This reward structure encourages reaching the goal with the minimum number of moves (each subtracting -1). Also, if the agent takes an action that hits a wall, it receives a reward of -100.
The learning consists of learning Q-values for each action at each location. The Q-learner uses a tabular representation, which is appropriate and effective for such a small state and action space.
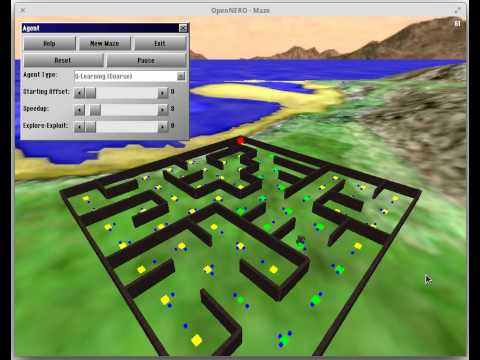
The visited tiles are marked by yellow or green markers, and the Q-values by blue squares in the four directions around the central markers. The distance of each blue square from the yellow/green tile indicates how large the Q-value is. Also, the size of the central yellow/green marker in each maze tile corresponds to the highest Q-value in that tile. The values are initially small, and you can see how they gradually change as a result of learning. The central marker turns green when the value of the tile is above 0, which means the agent has discovered some action in that tile which can eventually take it to the goal.
As soon as the agent reaches the goal for the first time, you should see that the values near the goal start to point in the right direction, and the learning proceeds gradually towards the start location. After learning, the pattern of blue squares at each location thus forms an arrow pointing at the best direction of movement.
Based on this observation, you can use the learning parameters that are available on the user interface (Explore-Exploit (epsilon), and Starting Offset) to speed up the learning process. The Explore-Exploit slider controls the probability of taking random exploratory moves vs. moves based on which action has the highest Q-value at the moment. Starting Offset controls the spawn location of the agent: The agent starts at a cell whose Manhattan distance from the source is equal to the value of the slider.
Start with very high values for Starting Offset so the agent starts very close to the goal. Also set the value of epsilon relatively high so that the agent can explore different actions. Learning progresses particularly when the agent is exploring a yellow tile and suddenly discovers an action that takes it to an adjacent green tile. At that point in time, the yellow marker becomes green, indicating that Steve can reach the goal from that tile by following the highest Q values. In other words, to increase the learning speed you should make Steve explore the boundary between the the two green and yellow regions so that more yellow cells can become green. When enough tiles turn green in the vicinity of the spawn location, gradually lower the value of Starting Offset so that the agent starts farther from the goal and explores more of the maze. Also, gradually lower the value of epsilon so that the agent tries to reach the goal from those farther locations. In the end, the agent should be able to reach the goal starting from the source (Starting Offset = 0.)
In the fine-grained version, the maze has 64x64 locations, and there are the same four actions (north, south, west, each) at each location. As a result, the agent moves much more continuously within the maze; on the other hand, the space is much larger and more difficult to learn. Because the state and action space is still represented as a table, it takes a very long time for the agent to explore all states and eventually learn Q-values for them (probably too long for you to watch).
To overcome the state explosion problem, Q-learning agents typically use a function approximator such as a neural network to represent the fine grained space with a smaller Q-value table. Constructing such an approximator is left as an exercise for the reader.
The locations and Q-values are represented as before as yellow and blue squares, however you may need to move closer to the maze to see them. The agent's movement is also slowed down so that it is easier to see the progress of the algorithm.
The Coarse version of first person control is the same as in the Search demos: you can use the arrow keys to move forward and backward and to turn left and right, or the keys w (forward), a (left), d (right), s (back). Each move forward and backward gets you to one 8x8 grid location to the next, and each turn is 90 degrees. In this manner, the coarse first-person control corresponds to the task that the coarse Q-learner faces.
The Fine version is similar, but moves from one 64x64 location to the next, corresponding to the Fine version of the Q-learner. As you can see, you can move around the space in a more continuous and natural fashion, but it also takes many more actions to get to the goal.
An important next step is to implement a function approximator that allows learning more fine-grained behavior. There are many varieties of such approximators: a simple example is a linear approximator in the Q-learning exercise page. A neural network can also be trained to approximate a continuous space based on a discrete Q-table. Coming up with better function approximators is an active area of reinforcement learning research.
An interesting and fun exercise is to train agents for the NERO game using reinforcement learning.
Other reinforcement learning methods are possible to implement in OpenNERO as well, such as Sarsa, policy iteration, etc.; see e.g. Chapter 21 in AIMA for details.