Small example scripts for working with Japanese texts in Python.
Copyright (c) 2014-2016, Mads Sørensen Ølsgaard, olsgaard.dk All rights reserved. Released under BSD3 License, see http://opensource.org/licenses/BSD-3-Clause or license.txt
This is a library of functions and variables that are helpful to have handy when manipulating Japanese text in python. This is optimized for Python 3.x, and takes advantage of the fact that all strings are unicode.
It mainly stores regexes to find hiragana, katakana, kanji and other types of characters in a string, as well as some easy to use shortcut functions.
Regular expression unicode blocks collected from Mark Rogoyski.
hiragana_full = r'[ぁ-ゟ]'
katakana_full = r'[゠-ヿ]'
kanji = r'[㐀-䶵一-鿋豈-頻]'
radicals = r'[⺀-⿕]'
katakana_half_width = r'[⦅-゚]'
alphanum_full = r'[!-~]'
symbols_punct = r'[、-〿]'
misc_symbols = r'[ㇰ-ㇿ㈠-㉃㊀-㋾㌀-㍿]'
ascii_char = r'[ -~]'
This is a quick script to make good hiragana <-> katakana transliteration in just 4 lines of Python.
If you don't need romaji translitteration and want to lower your scripts dependencies you can forgo pip installing some surprisingly large libraries just to convert from hiraganan to katakana and simply copy paste the below 4 lines (and preferrably a link to my homepage or github) and you are good to go.
Tested in Python 3.x, doesn't seem to work in Python 2.7 download it off my github here
I use the builtin string function translate which converts characters to corrosponding characters in a translations table, easily created with another string function, maketrans. See documentation here
We simply create our hiragana and katakana translation tables and use the str.translate() function to do the heavy lifting.
I've used Mark Rogoyski list of hiragana and katakana unicode codepoints and removed characters I don't want transliterated. For example, I want to be able to convert コーヒ to hiragana and back. If I had naively used the table, then ー would be converted into ゜, which wouldn't make any sense.
The magic happens in these 4 lines of code:
katakana_chart = "ァアィイゥウェエォオカガキギクグケゲコゴサザシジスズセゼソゾタダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤュユョヨラリルレロヮワヰヱヲンヴヵヶヽヾ"
hiragana_chart = "ぁあぃいぅうぇえぉおかがきぎくぐけげこごさざしじすずせぜそぞただちぢっつづてでとどなにぬねのはばぱひびぴふぶぷへべぺほぼぽまみむめもゃやゅゆょよらりるれろゎわゐゑをんゔゕゖゝゞ"
hir2kat = str.maketrans(hiragana_chart, katakana_chart)
kat2hir =str.maketrans(katakana_chart, hiragana_chart)
And it is used like so:
mixed = 'きゃりーぱみゅぱみゅは日本の歌手です。'
print(mixed.translate(hir2kat))
# out: キャリーパミュパミュハ日本ノ歌手デス。
# transliterate back and forth
print(mixed.translate(hir2kat).translate(kat2hir))
# out: きゃりーぱみゅぱみゅは日本の歌手です。
Notice how kanji and special characters are left alone.
Function to determine the character class of a single character in a Japanes text. Distinguishes between 6 classes, OTHER, ROMAJI, HIRAGANA, KATAKANA, DIGIT, KANJI
These classes can be useful as features in a machine learning classifier.
If you are working with any kind of NLP in Python that involves Japanese, it is paramount to be able to view summary statics in the form of graphs that in one way or another includes Japanese characters.
On most systems the default font won't be able to show both kanji, kana and ascii and many fonts (at least on ubuntu) will only be able to show CJK script or alphabet, which is a real pain in the ass.
This script helps you to figure out which font to use.
On ubuntu the output to STDOUT should be the following:
Droid Sans /usr/share/fonts/truetype/droid/DroidSans.ttf
Vera /home/supermads/anaconda3/lib/python3.4/site-packages/matplotlib/mpl-data/fonts/ttf/Vera.ttf
TakaoGothic /usr/share/fonts/truetype/takao-gothic/TakaoGothic.ttf
TakaoPGothic /usr/share/fonts/truetype/takao-gothic/TakaoPGothic.ttf
Liberation Sans /usr/share/fonts/truetype/liberation/LiberationSans-Regular.ttf
ubuntu /usr/share/fonts/truetype/ubuntu-font-family/Ubuntu-R.ttf
FreeSans /usr/share/fonts/truetype/freefont/FreeSans.ttf
Droid Sans Japanese /usr/share/fonts/truetype/droid/DroidSansJapanese.ttf
DejaVu Sans /usr/share/fonts/truetype/dejavu/DejaVuSans.ttf
As you can see, I’m running Anaconda Python 3, and if Anaconda can’t find a font it will fallback into it’s own folder to load the Vera font.
It will also draw a plot in matplotlib, where you can see how the different fonts handle CJK-characters and alphabet.
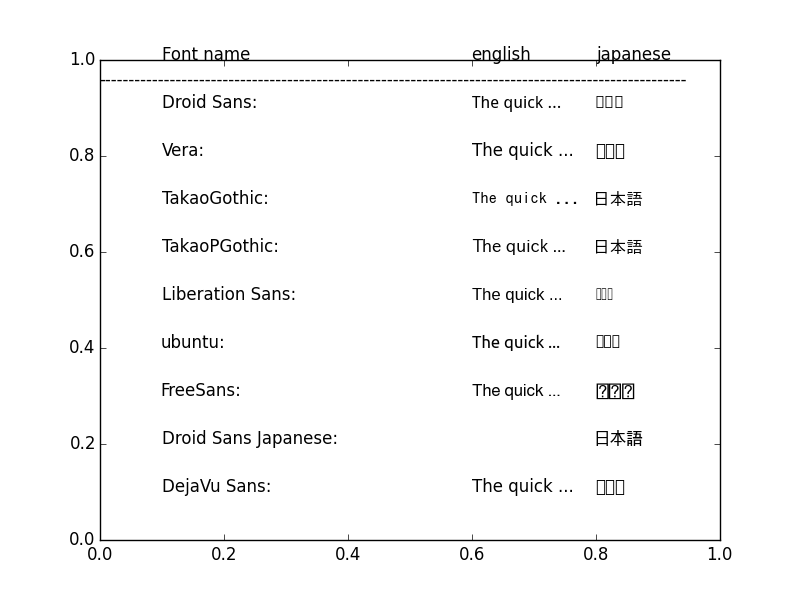
I’ve found the simplest way of changing fonts in matplotlib to simply be using matplotlib.rc
import matplotlib
matplotlib.rc('font', family='Monospace')