



By using Amazon Scraper, you agree to comply with all applicable local and international laws related to data scraping, copyright, and privacy. The developers of Amazon Scraper will not be held liable for any misuse of this software. It is the user's sole responsibility to ensure adherence to all relevant laws regarding data scraping, copyright, and privacy, and to use Amazon Scraper in an ethical and legal manner, in line with both local and international regulations.
We take concerns related to the Amazon Scraper Project very seriously. If you have any inquiries or issues, please contact Chetan Jain at chetan@omkar.cloud. We will take prompt and necessary action in response to your emails.
- ✅ Botasaurus: The All-in-One Web Scraping Framework with Anti-Detection, Parallelization, Asynchronous, and Caching Superpowers.
Amazon Scraper helps you collect Amazon product data.
1️⃣ Clone the Magic 🧙♀:
git clone https://github.com/omkarcloud/amazon-scraper
cd amazon-scraper2️⃣ Install Dependencies 📦:
python -m pip install -r requirements.txt3️⃣ Let the Scraping Begin 😎:
python main.pyFind your data in the output directory.
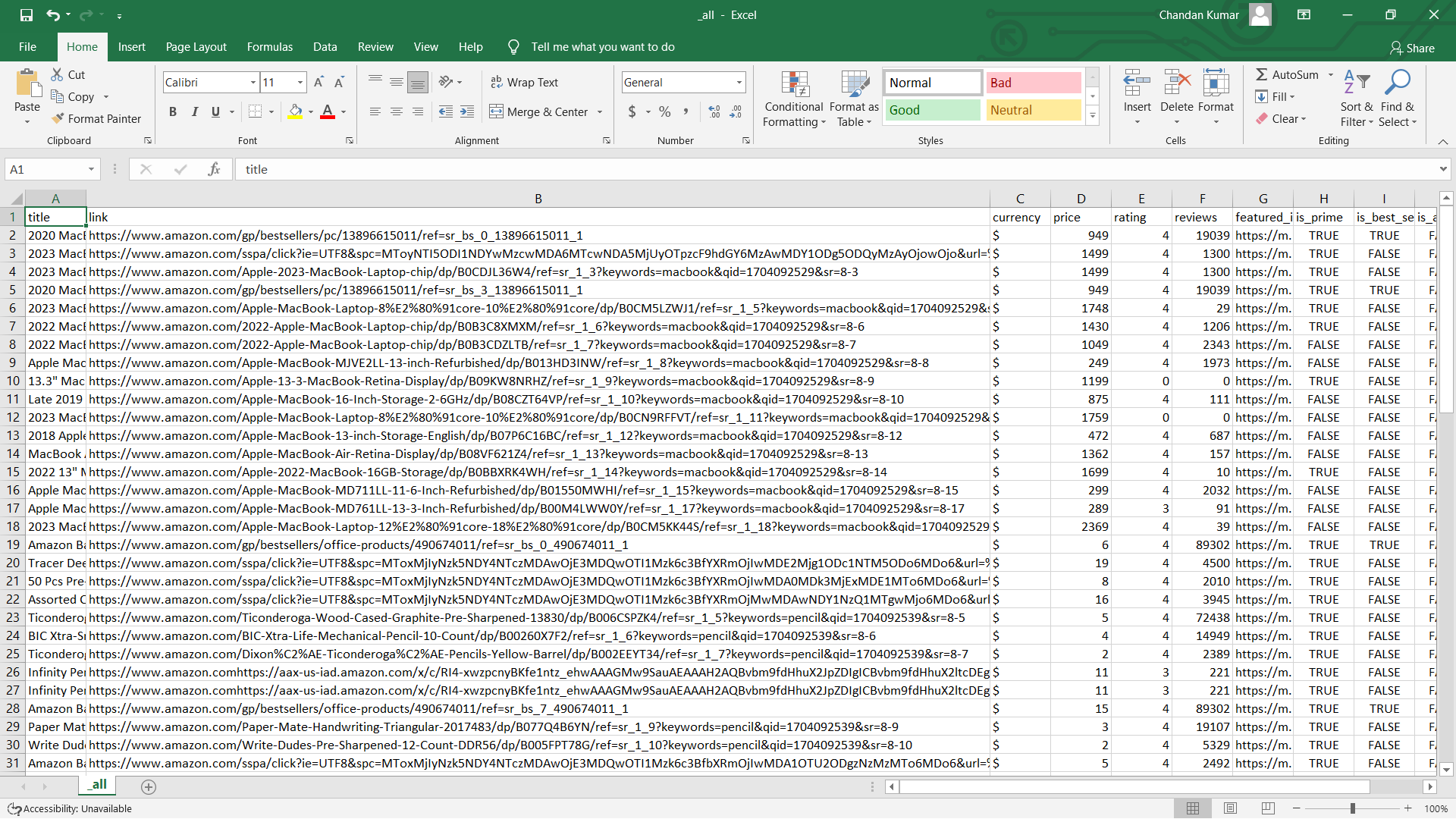
Note: If you don't have Python installed. Follow this Simple FAQ here and you will have your Amazon data in next 5 Minutes
- Open the
main.pyfile. - Update the
querieslist with the locations you are interested in. For example:
queries = [
"Macbook",
]
Amazon.search(queries)- Run it.
python main.pyThen find your data in the output directory.
Use the following code to scrape Amazon products based on their ASINs:
asins = [
"B08CZT64VP",
]
Amazon.get_products(asins)To scrape additional data, follow these steps to use our Amazon API. You can make 50 requests for free:
- Sign up on RapidAPI by visiting this link.
- Then, subscribe to our Free Plan by visiting this link.
- Now, copy the API key.
- Use it in the scraper as follows:
queries = [
"watch",
]
Amazon.search(queries, key="YOUR_API_KEY")- Run the script, and you'll find your data in the
outputfolder.
python main.pyThe first 50 requests are free. After that, you can upgrade to the Pro Plan, which will get you 1000 requests for just $9.
We used Botasaurus, It's an All-in-One Web Scraping Framework with Anti-Detection, Parallelization, Asynchronous, and Caching Superpowers.
Botasaurus helped us cut down the development time by 50% and helped us focus only on the core extraction logic of the scraper.
If you are a Web Scraper, you should learn about Botasaurus here, because Botasaurus will save you countless hours in your life as a Web Scraper.

For further help, contact us on WhatsApp. We'll be happy to help you out.
