{kind=link}
{kind=link}
{kind=link}
{kind=link}
What is an optimal pricing strategy for Uber?
By analyzing Uber's ride data, we can gain insights into the relationship between factors such as time of day, location, and customer demographics, and the demand for rides. This information can be used to develop dynamic pricing models that adjust prices in real-time based on current demand and supply. By implementing an optimal pricing strategy, Uber can maximize its revenue generation while maintaining a balance between affordability and profitability. Additionally, the company can use the insights to offer personalized promotions and discounts to specific customer segments, further enhancing customer satisfaction and loyalty.
How can Uber forecase demand and resource allocation?
Utilizing historical ride data and other external factors like weather, events, and public holidays, we can develop advanced demand forecasting models to predict future ride demand patterns. This predictive analysis will enable the company to allocate resources, such as drivers and vehicles, more effectively across different times and locations. Proper resource allocation ensures that the supply of rides meets the demand, reducing wait times for customers and minimizing idle time for drivers. As a result, operational efficiency improves, leading to reduced costs and increased customer satisfaction.
- Database Schema Design - https://lucid.co/
- Google Cloud Platform Services - Google Storage , Google Compute Engine, Google BigQuery
- Data Pipeline Tool - https://www.mage.ai/
- Data Visualization Tool - Looker Studio
- Python
- SQL
Website : https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
Data Dictionary : https://www.nyc.gov/assets/tlc/downloads/pdf/data_dictionary_trip_records_yellow.pdf
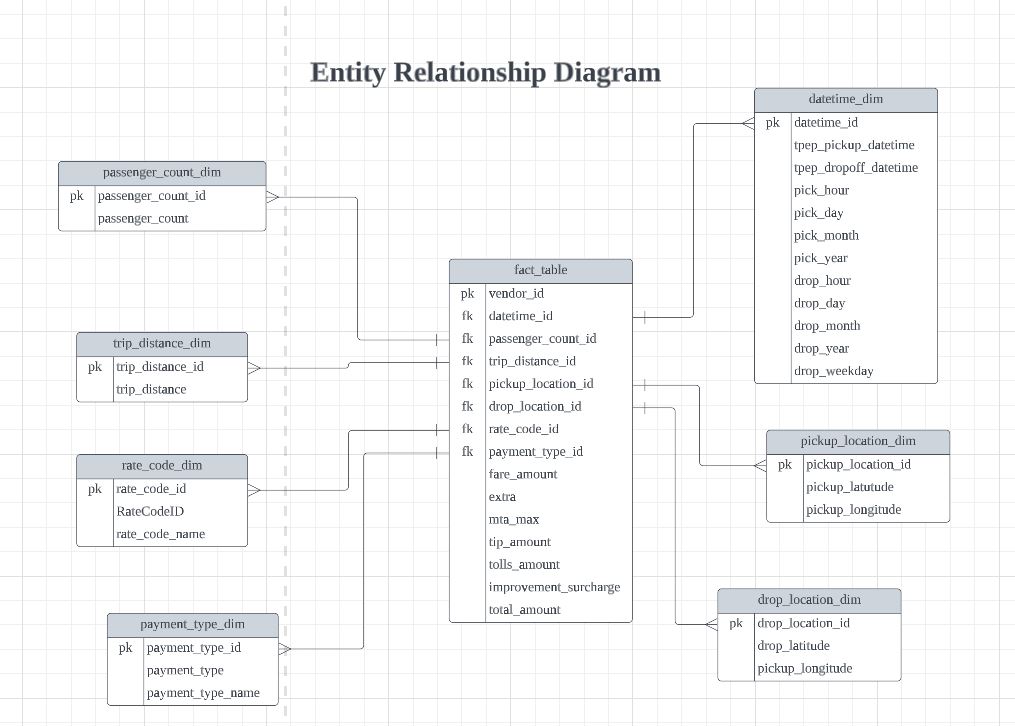
We will be utilizing Lucid to create a entity relationship diagram, to help us visualize and design the schema of the database by representing tables, columns, and relationships between the tables.
Afterwards, We will leverage google cloud tools to perform Data Warehousing, Data Analysis and also MAGE to perform ETL and Looker Studio to visaulize the data.
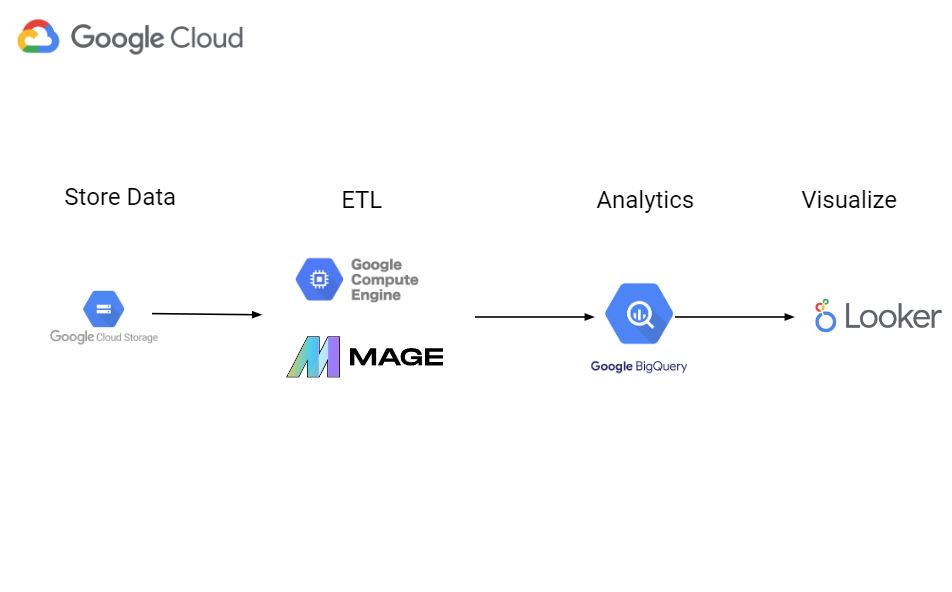
The project workflow can be summarized as follows:
- Store the raw Uber data files in Google Cloud Storage.
- Create a Compute Instance to run Python scripts or Jupyter Notebooks for data exploration and processing.
- Use the Mage Data Pipeline Tool to create data pipelines that extract data from Cloud Storage, transform it using Python scripts, and load the transformed data into BigQuery.
- Analyze and visualize the data in BigQuery using SQL queries and Looker Studio to create interactive dashboards and reports.
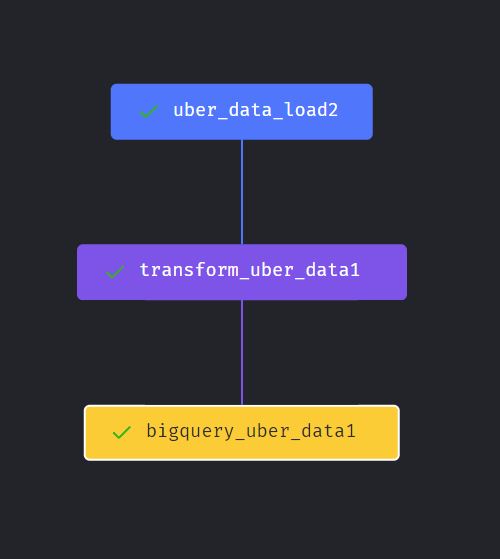
I will be performing data analytics on Uber's ride data using various tools and technologies, including Google Cloud Platform (GCP) services, Python, and external tools like Mage Data Pipeline Tool and Looker Studio. The goal of this project is to gain insights into the ride data to improve operational efficiency, customer satisfaction, and strategic decision-making.
The architecture of the project consists of several components, each serving a specific purpose in the data analytics process. The components include GCP Storage, Compute Engine, BigQuery, Looker Studio, Mage Data Pipeline Tool, and the usage of APIs for data ingestion.
To obtain Uber's ride data, we can utilize Google Storage's API to fetch ride details, such as timestamps, location coordinates, and ride status. This data can be ingested periodically and stored in Google Cloud Storage as raw files. Cloud Storage provides a scalable, durable, and cost-effective solution for storing and retrieving data in various file formats (CSV, JSON, Avro, Parquet, etc.).
Google Compute Engine offers advanced virtual machines that can be used for running Python scripts or Jupyter Notebooks for data exploration, processing, and transformation. In this project, a Compute Instance is used to interact with the raw data stored in Cloud Storage and perform initial analysis and processing using Python libraries like Pandas and NumPy.
Mage is a data pipeline tool that can be employed for data extraction, transformation, and loading (ETL) tasks. It automates the process of extracting data from sources like Cloud Storage, transforming it using Python scripts, and loading it into BigQuery for further analysis. In this project, Mage is used to create data pipelines that run on a Compute Instance to process the Uber ride data and load the transformed data into BigQuery.
BigQuery is a fully-managed, serverless data warehouse that enables users to analyze large datasets in real-time using SQL. The transformed Uber ride data is stored in BigQuery, where complex queries can be performed for data analysis and visualization.
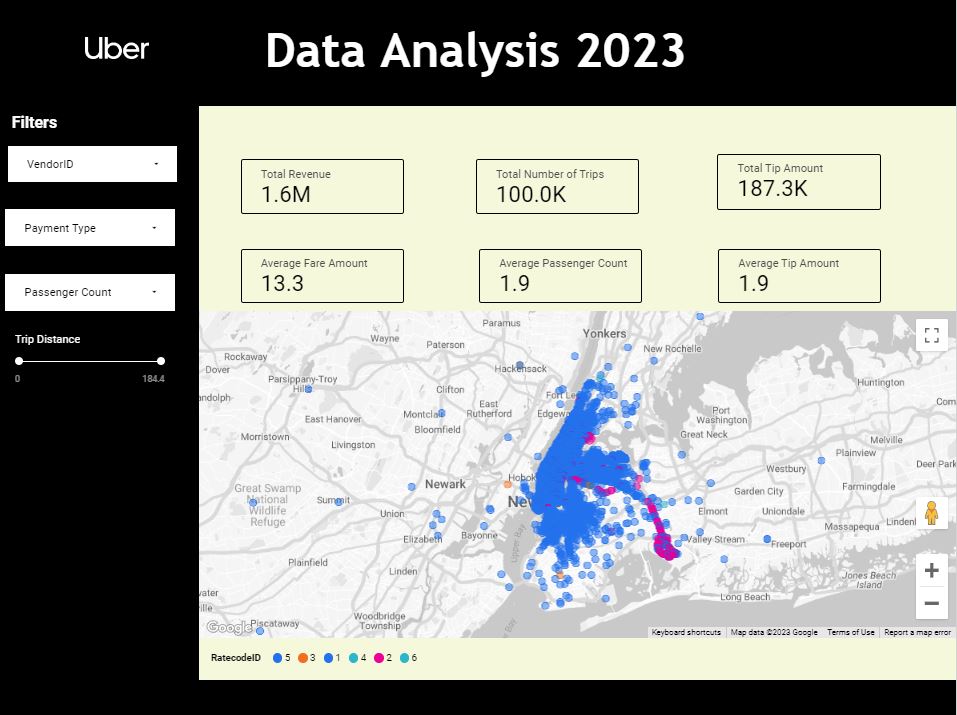
Looker Studio is a powerful data analytics and visualization tool that integrates with BigQuery. It allows users to create interactive dashboards and reports to gain insights from the data stored in BigQuery, enabling data-driven decision-making at Uber.
By leveraging modern data engineering techniques and Google Cloud Platform services, we have built a scalable and robust data analytics solution for Uber's ride data. This solution allows us to extract valuable insights and make informed decisions to improve operational efficiency, customer satisfaction, and strategic planning at Uber. The use of API for data ingestion, combined with Cloud Storage, Compute Engine, Mage Data Pipeline Tool, BigQuery, and Looker Studio, provides a comprehensive and flexible approach to data engineering and analytics in a cloud-native environment.