[Doc] Add dataflow document #2403
Conversation
3539902 to
dd1a894
Compare
Codecov ReportBase: 83.33% // Head: 83.33% // No change to project coverage 👍
Additional details and impacted files@@ Coverage Diff @@
## dev-1.x #2403 +/- ##
========================================
Coverage 83.33% 83.33%
========================================
Files 143 143
Lines 8127 8127
Branches 1211 1211
========================================
Hits 6773 6773
Misses 1165 1165
Partials 189 189
Flags with carried forward coverage won't be shown. Click here to find out more. Help us with your feedback. Take ten seconds to tell us how you rate us. Have a feature suggestion? Share it here. ☔ View full report at Codecov. |
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| ### Data Preprocessor to Model | ||
|
|
||
| Though drawn separately in the diagram [above](#overview-of-dataflow), data_preprocessor is a part of the model and thus can be found in [Model tutorial](./models.md) at Seg DataPreprocessor chapter. |
There was a problem hiding this comment.
Add specific http link of models.md.
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| The same as Data Preprocessor, loss function is also a part of the model, it's a property of [decode head](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py#L142). | ||
|
|
||
| In MMSegmentation, the method [loss_by_feat](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py#L291) of `decode_head` is a unify interface used to compute loss. |
There was a problem hiding this comment.
| In MMSegmentation, the method [loss_by_feat](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py#L291) of `decode_head` is a unify interface used to compute loss. | |
| In MMSegmentation, the method [loss_by_feat](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py#L291) of `decode_head` is an unified interface used to compute loss. |
docs/en/advanced_guides/data_flow.md
Outdated
| As illustrated in the [Runner document of MMEngine](https://mmengine.readthedocs.io/en/latest/tutorials/runner.html), the following diagram shows the basic dataflow. | ||
|
|
||
|  | ||
|
|
||
| The dashed border, gray filled shapes represent different data formats, while solid boxes represent modules/methods. Due to the great flexibility and extensibility of MMEngine, you can always inherit some key base classes and override their methods, so the above diagram doesn’t always hold. It only holds when you are not customizing your own `Runner` or `TrainLoop`, and you are not overriding `train_step`, `val_step` or `test_step` method in your custom model. |
There was a problem hiding this comment.
It should emphasize that Runner controls the dataflow, and add examples of train_cfg, test_cfg and val_cfg in mmseg. might also attach the link for runner design documentation https://github.com/open-mmlab/mmengine/blob/main/docs/en/design/runner.md
it is necessary to explain the train_step, val_step or test_step work for each iteration for training and testing and add links https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step, https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#val_step and https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#test_step
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| The dashed border, gray filled shapes represent different data formats, while solid boxes represent modules/methods. Due to the great flexibility and extensibility of MMEngine, you can always inherit some key base classes and override their methods, so the above diagram doesn’t always hold. It only holds when you are not customizing your own `Runner` or `TrainLoop`, and you are not overriding `train_step`, `val_step` or `test_step` method in your custom model. | ||
|
|
||
| ## Format convention |
There was a problem hiding this comment.
| ## Format convention | |
| ## Dataflow convention in MMSegmentation |
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| The return value is the same as `PackSegInputs` except the `inputs` would be transferred to GPU and some additional metainfo like `pad_shape` and `padding_size` would be added to the `data_samples`. | ||
|
|
||
| ### Model to Evaluator |
There was a problem hiding this comment.
| ### Model to Evaluator | |
| ### Model output | |
| #### To Evaluator | |
| #### Optim Wrapper | |
| #### |
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| The return value is the same as `PackSegInputs` except the `inputs` would be transferred to GPU and some additional metainfo like `pad_shape` and `padding_size` would be added to the `data_samples`. | ||
|
|
||
| ### Model to Evaluator |
There was a problem hiding this comment.
we can add some explanation about the control flow of runner when training and testing, like call train_step: model.forward-> evaluator, call test_step: model.forward -> optim wrapper refer, and attach the link https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md
and highlight the input and output of model and other modules
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| MMSegmentation defines the default data format at [PackSegInputs](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/datasets/transforms/formatting.py#L12), it's the last component of `train_pipeline` and `test_pipeline`. Please refer to [data transform documentation](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/transforms.html) for more information about data transform `pipeline`. | ||
|
|
||
| Without any modifications, the return value of PackSegInputs is usually a `dict` and has only two keys, `inputs` and `data_samples`. The following pseudo-code shows the data types of the data loader output, `inputs` is the list of input tensors to the model and `data_samples` contains a list of input images' meta information and corresponding ground truth. |
There was a problem hiding this comment.
| Without any modifications, the return value of PackSegInputs is usually a `dict` and has only two keys, `inputs` and `data_samples`. The following pseudo-code shows the data types of the data loader output, `inputs` is the list of input tensors to the model and `data_samples` contains a list of input images' meta information and corresponding ground truth. | |
| Without any modifications, the return value of PackSegInputs is usually a `dict` and has only two keys, `inputs` and `data_samples`. The following pseudo-code shows the data types of the data loader output in mmseg, which is a batch of fetched data samples from the dataset, and data loader packs them into a dictionary of the list. `inputs` is the list of input tensors to the model and `data_samples` contains a list of input images' meta information and corresponding ground truth. |
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| ### Data Preprocessor to Model | ||
|
|
||
| Though drawn separately in the diagram [above](#overview-of-dataflow), data_preprocessor is a part of the model and thus can be found in [Model tutorial](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/models.html) at Seg DataPreprocessor chapter. |
There was a problem hiding this comment.
| Though drawn separately in the diagram [above](#overview-of-dataflow), data_preprocessor is a part of the model and thus can be found in [Model tutorial](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/models.html) at Seg DataPreprocessor chapter. | |
| Though drawn separately in the diagram [above](#overview-of-dataflow), data_preprocessor is a part of the model and thus can be found in [Model tutorial](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/models.html) at data preprocessor chapter. |
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| Though drawn separately in the diagram [above](#overview-of-dataflow), data_preprocessor is a part of the model and thus can be found in [Model tutorial](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/models.html) at Seg DataPreprocessor chapter. | ||
|
|
||
| The return value of Data Preprocessor is a dict, contains `inputs` and `data_samples`, `inputs` would be transferred to GPU and some additional metainfo like `pad_shape` and `padding_size` would be added to the `data_samples`. When transfer to the network, the dict would be unpacked to two values. The following pseudo-codes show the return value of data preprocessor and the input values of model. |
There was a problem hiding this comment.
| The return value of Data Preprocessor is a dict, contains `inputs` and `data_samples`, `inputs` would be transferred to GPU and some additional metainfo like `pad_shape` and `padding_size` would be added to the `data_samples`. When transfer to the network, the dict would be unpacked to two values. The following pseudo-codes show the return value of data preprocessor and the input values of model. | |
| The return value of data preprocessor is a dictionary, containing `inputs` and `data_samples`, `inputs` is batched images, a 4D tensor, and some additional meta info used in data preprocesses would be added to the `data_samples`. When transferred to the network, the dictionary would be unpacked to two values. The following pseudo-codes show the return value of the data preprocessor and the input values of model. |
docs/en/advanced_guides/data_flow.md
Outdated
| ```python | ||
| dict( | ||
| inputs=torch.Tensor, | ||
| data_samples=Optional[List[SegDataSample], None] | ||
| ) | ||
| ``` |
There was a problem hiding this comment.
| ```python | |
| dict( | |
| inputs=torch.Tensor, | |
| data_samples=Optional[List[SegDataSample], None] | |
| ) | |
| ``` | |
| ```python | |
| dict( | |
| inputs=torch.Tensor, | |
| data_samples=List[SegDataSample] | |
| ) |
I think this tutorial is about data flow under runner control, which contains gt always
docs/en/advanced_guides/data_flow.md
Outdated
| test_cfg = dict(type='TestLoop') | ||
| ``` | ||
|
|
||
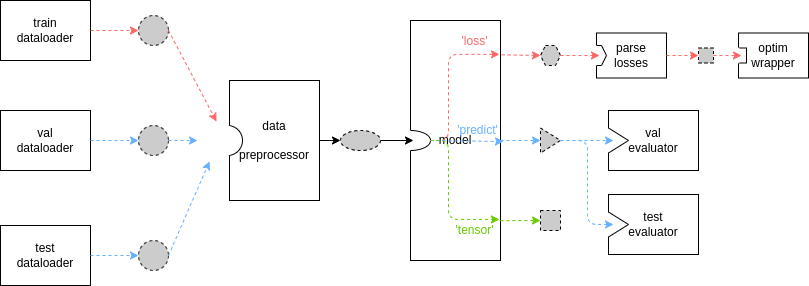
| In the above diagram, the red line indicates the [train_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step). At each training iteration, dataloader loads images from storage and transfer to data preprocessor, data preprocessor would put images to GPU device and stack data to batch, then model accept the batch data as inputs, finally the outputs of the model would be sent to optimizer. The blue line indicates [val_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#val_step) and [test_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#test_step). The dataflow of these two process is similar to the `train_step` except the outputs of model, since model parameters are freezed when doing evaluation, the model output would be transferred to [Evaluator](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/evaluation.md#ioumetric) to compute metrics. |
There was a problem hiding this comment.
| In the above diagram, the red line indicates the [train_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step). At each training iteration, dataloader loads images from storage and transfer to data preprocessor, data preprocessor would put images to GPU device and stack data to batch, then model accept the batch data as inputs, finally the outputs of the model would be sent to optimizer. The blue line indicates [val_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#val_step) and [test_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#test_step). The dataflow of these two process is similar to the `train_step` except the outputs of model, since model parameters are freezed when doing evaluation, the model output would be transferred to [Evaluator](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/evaluation.md#ioumetric) to compute metrics. | |
| In the above diagram, the red line indicates the [train_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step). At each training iteration, dataloader loads images from storage and transfer to data preprocessor, data preprocessor would put images to the specific device and stack data to batch, then model accepts the batch data as inputs, finally the outputs of the model would be sent to optimizer. The blue line indicates [val_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#val_step) and [test_step](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#test_step). The dataflow of these two process is similar to the `train_step` except the outputs of model, since model parameters are freezed when doing evaluation, the model output would be transferred to [Evaluator](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/evaluation.md#ioumetric) to compute metrics. |
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| ### Model output | ||
|
|
||
| #### To Evaluator |
There was a problem hiding this comment.
| #### To Evaluator | |
| As [model tutorial](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#forward) mentioned 3 kinds of mode forward with 3 kinds of output. `train_step`and `test_step`(or `val_step`) correspond to `'loss'` and `'predict'` respectively. |
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
| #### To Evaluator | ||
|
|
||
| At the evaluation procedure, the inference results would be transferred to `Evaluator`. You might read the [evaluation document](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/evaluation.html) for more information about `Evaluator`. |
There was a problem hiding this comment.
| At the evaluation procedure, the inference results would be transferred to `Evaluator`. You might read the [evaluation document](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/evaluation.html) for more information about `Evaluator`. | |
| In `test_step` or `val_step`, the inference results would be transferred to `Evaluator`. You might read the [evaluation document](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/evaluation.html) for more information about `Evaluator`. |
docs/en/advanced_guides/data_flow.md
Outdated
|
|
||
|  | ||
|
|
||
| #### Optim Wrapper |
There was a problem hiding this comment.
| #### Optim Wrapper |
* draft * update loss * update * add runner * add steps * update
* draft * update loss * update * add runner * add steps * update
* draft * update loss * update * add runner * add steps * update
* draft * update loss * update * add runner * add steps * update
* draft * update loss * update * add runner * add steps * update
* draft * update loss * update * add runner * add steps * update
* add lora convertor * Update convert_lora_safetensor_to_diffusers.py * Update README.md * Update convert_lora_safetensor_to_diffusers.py
* draft * update loss * update * add runner * add steps * update
Motivation
Add dataflow doc
Modification