HER does not converge on simple envs that adhere to GoalEnv interface #428
Comments
ContinuousGoalOrientedMoveToPoint-v0 EnvironmentEnv Summary:The goal of this environment is to move the agent (a red dot) to touch the goal (a greev dot). The agent has momentum and will bounce off of walls if it touches one. Gif of EnvironmentPlease excuse the inconsistent frame rate, I was controlling the agent with a keyboard and did not hit the keys at a constant frequency. Env DetailsState Space: Positions in a unit square, velocities between -0.05 and +0.05. Source codecontinuous_goal_oriented_particle.py.gz |

|
@mandrychowicz and/or other developers I would love to use HER and continue to build on it at my company. Unfortunately this simple environment which was meant to be used for unit tests does not want to solve. |
|
Update: My coworker was able to solve the ContinuousGoalOrientedMoveToPoint environment with 100% success rate with TDM, which makes me more confident that this is a problem with Baselines HER and not the environment. |
|
I was unable to get HER to solve the ContinuousMoveToPointEnvironment with hyper-parameter tuning. I manually varied the following one at a time to no effect:
Here you can see a graph of the runs which are all noisy measurements with mean ~0.25 |

|
@avaziri I also have some problems solving my environments with HER, but still I'm not sure if it's the HER's implementation fault, or mine. Did you have any progress with identifying the problem with your environment? |
|
Did you try to use -1 reward for not reaching a goal and 0 reward for reaching it? Also, your environment seems easier then FetchPush - maybe try to use 1 hidden layer network with 20-50 hidden neurons and batch size of 8, maybe 16? Try to run this with HER probability 0.0 as well. I am very interested what will happen. Did you inspect how the agent moves around the env after several epochs of learning? I would be interested what is his behaviour - is it totally random, does it have any kind of pattern etc. |
* Update dependencies * Fix for numpy v1.17.0 * Downgrade pytest version for travis * Update .travis.yml * Rollback to previous docker image * Update .travis.yml * Trying to upgrade pytest * Try to ignore pytest warning * Update setup.cfg * Use full name to ignore pytest warning * Correct import * Remove gym and tf warnings * Add TD3 to tensorboard tests * Ignore additional gym warning * Get rid of additional tf warning * Re-enable new docker image * Test with different tf version * Upgrade pytest * Upgrade tf to 1.13.2 * Try downgrading tf * Move Travis CI test to separate bash file * Try splitting up test suite * Diagnostic: echo test glob * Avoid unintended wildcard * Upgrade TF to 1.13.2, move scripts to subdirectory * Split up tests to keep them <20m long * Try thread-safe SubprocVecEnv * Disable non-thread safe start methods in tests; document default change * Rebalance tests * Rebalance some more * Rebalance, hopefully for the last time * Fix globs * Update docker cpu image: add coverage reporter for travis * Codacy partial upload * Bump Docker image version * Make Travis read environment variable * Pass project token in * Remove pip install and fix coverage final report
System information
Describe the problem
I have not been able to get HER to converge on any environment other than the Mujoco environments. I have concerns about the robustness and reproducibility of the algorithm. Even with hyperparameter tuning HER fails to converge on all the simple environments I have tried.
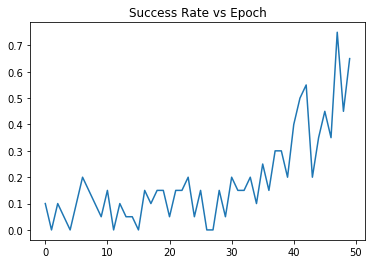
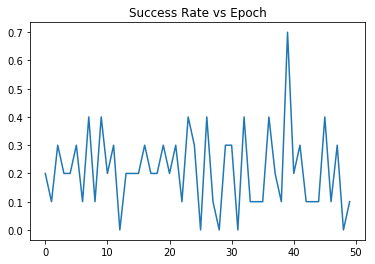
Here is a graph of test progress on FetchPush-v1 with command
python -m baselines.her.experiment.train --env_name=FetchPush-v1:Here is a graph of test progress on the much more simple environment I made. I will give the source, and a description of the environment in a follow up post. It was run with command
python -m baselines.her.experiment.train --env_name ContinuousGoalOrientedMoveToPoint-v0:Result: Over 50 epochs it seems any learning is negligible. I am confident the environment is functioning properly. I have confirmed that DDPG can solve this environment very well with less than 20 epochs of training. I have also made a keyboard agent and played this environment myself; observing that everything works as expected.
Hypothesis About Cause of Problem
The text was updated successfully, but these errors were encountered: