Schedoscope at a Glance
Schedoscope is a scheduling framework for painfree agile development, testing, (re)loading, and monitoring of your Hadoop data warehouse.
Schedoscope makes the headache go away you are certainly going to get when having to frequently rollout and retroactively apply changes to computation logic and data structures in your datahub with traditional ETL job schedulers such as Oozie.
With Schedoscope,
- you never have to create DDL and schema migration scripts;
- you do not have to manually determine which data must be deleted and recomputed in face of retroactive changes to logic or data structures;
- you specify Hive table structures (called "views"), partitioning schemes, storage formats, dependent views, as well as transformation logic in a concise Scala DSL;
- you have a wide range of options for expressing data transformations - from file operations and MapReduce jobs to Pig scripts, Hive queries, Spark jobs, and Oozie workflows;
- you benefit from Scala's static type system and your IDE's code completion to make less typos that hit you late during deployment or runtime;
- you can easily write unit tests for your transformation logic in ScalaTest and run them quickly right out of your IDE;
- you schedule jobs by expressing the views you need - Schedoscope takes care that all required dependencies - and only those- are computed as well;
- you can easily and efficiently export view data in parallel to external systems such as Redis caches, JDBC, or Kafka topics;
- you have Metascope - a nice metadata management and data lineage tracing tool - at your disposal;
- you achieve a higher utilization of your YARN cluster's resources because job launchers are not YARN applications themselves that consume cluster capacitity.
Based on Schedoscope's DSL,
-
defining a monthly partitioned Hive table (called "view") is as simple as:
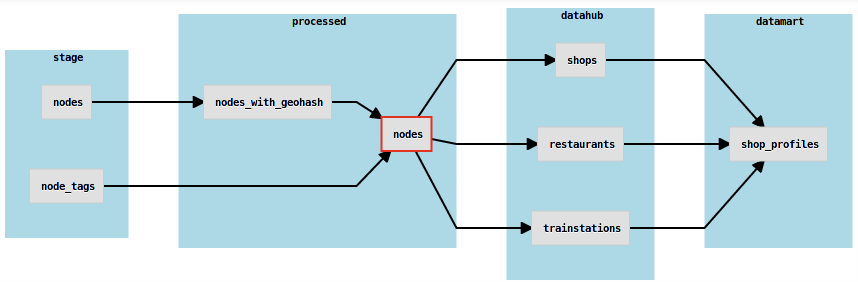
case class Nodes( year: Parameter[String], month: Parameter[String]) extends View with MonthlyParameterization with Id with PointOccurrence with JobMetadata { val version = fieldOf[Int] val user_id = fieldOf[Int] val longitude = fieldOf[Double] val latitude = fieldOf[Double] val geohash = fieldOf[String] val tags = fieldOf[Map[String, String]] comment("View of nodes partitioned by year and month with tags and geohash") storedAs(Parquet()) } -
defining its dependencies on other views is as simple as:
case class Nodes( year: Parameter[String], month: Parameter[String]) extends View with MonthlyParameterization with Id with PointOccurrence with JobMetadata { val version = fieldOf[Int] val user_id = fieldOf[Int] val longitude = fieldOf[Double] val latitude = fieldOf[Double] val geohash = fieldOf[String] val tags = fieldOf[Map[String, String]] dependsOn(() => NodesWithGeohash(p(year), p(month))) dependsOn(() => NodeTags(p(year), p(month))) comment("View of nodes partitioned by year and month with tags and geohash") storedAs(Parquet()) } -
specifying the logic how to compute the view out of its dependencies is as simple as:
case class Nodes( year: Parameter[String], month: Parameter[String]) extends View with MonthlyParameterization with Id with PointOccurrence with JobMetadata { val version = fieldOf[Int] val user_id = fieldOf[Int] val longitude = fieldOf[Double] val latitude = fieldOf[Double] val geohash = fieldOf[String] val tags = fieldOf[Map[String, String]] dependsOn(() => NodesWithGeohash(p(year), p(month))) dependsOn(() => NodeTags(p(year), p(month))) transformVia(() => HiveTransformation( insertInto( this, queryFromResource("hiveql/processed/insert_nodes.sql"))) .configureWith(Map( "year" -> year.v.get, "month" -> month.v.get))) comment("View of nodes partitioned by year and month with tags and geohash") storedAs(Parquet()) } -
efficiently exporting view data in parallel to an external database such as MySQL is as simple as:
case class Nodes( year: Parameter[String], month: Parameter[String]) extends View with MonthlyParameterization with Id with PointOccurrence with JobMetadata { val version = fieldOf[Int] val user_id = fieldOf[Int] val longitude = fieldOf[Double] val latitude = fieldOf[Double] val geohash = fieldOf[String] val tags = fieldOf[Map[String, String]] dependsOn(() => NodesWithGeohash(p(year), p(month))) dependsOn(() => NodeTags(p(year), p(month))) transformVia(() => HiveTransformation( insertInto( this, queryFromResource("hiveql/processed/insert_nodes.sql"))) .configureWith(Map( "year" -> year.v.get, "month" -> month.v.get))) comment("View of nodes partitioned by year and month with tags and geohash") storedAs(Parquet()) exportTo(() => Jdbc(this, "jdbc:mysql://mysqlhost:3306/somedatabase", "someuser", "somepassword"))) } -
testing the view logic is as simple as:
"processed.Nodes" should "load correctly from processed.nodes_with_geohash and stage.node_tags" in { new Nodes(p("2013"), p("06")) with test { basedOn(nodeTags, nodes) then() numRows shouldBe 1 row(v(id) shouldBe "122318", v(occurredAt) shouldBe "2013-06-17 15:49:26Z", v(version) shouldBe 6, v(user_id) shouldBe 50299, v(tags) shouldBe Map( "TMC:cid_58:tabcd_1:Direction" -> "positive", "TMC:cid_58:tabcd_1:LCLversion" -> "8.00", "TMC:cid_58:tabcd_1:LocationCode" -> "10696")) } }
Running the Schedoscope shell,
-
loading the view is as simple as:
materialize -v schedoscope.example.osm.processed/Nodes/2013/06 -
reloading the view in case its dependencies, structure, or logic have changed is just the same (there is no difference between loading and reloading):
materialize -v schedoscope.example.osm.processed/Nodes/2013/06In case they haven't changed, nothing will be reloaded and data will stay as they are.
-
monitoring a view's load state is as simple as:
views -v schedoscope.example.osm.processed/Nodes/2013/06 -d RESULTS ======= Details: +------------------------------------------------------------+--------------+-------+ | VIEW | STATUS | PROPS | +------------------------------------------------------------+--------------+-------+ | schedoscope.example.osm.processed/Nodes/2013/06 | waiting | | | schedoscope.example.osm.processed/NodesWithGeohash/2013/06 | materialized | | | schedoscope.example.osm.stage/NodeTags/2013/06 | transforming | | +------------------------------------------------------------+--------------+-------+ Total: 3 materialized: 1 waiting: 1 transforming: 1
Using [Metascope](Metascope Primer)
- metadata management, data discovery and exploration, and data lineage tracing is as easy as