Scheduling
Scheduling with Schedoscope is based on three principles:
-
Goal orientation: with Schedoscope, you specify the views you want and the scheduler takes care that the corresponding data are materialized.
-
Self-sufficiency: Schedoscope has all information about views available: structure, dependencies, transformation logic. The scheduler thus can start out from an empty metastore and create all tables and partitions as data are materialized.
-
Reloading is loading: Schedoscope implements measures to automatically detect changes to view structure and computation logic; as it is self-sufficient, it can then automatically rematerialize potentially outdated views.
Loading views is called materialization. Materialization is triggered with the materialize command via either the [REST API](Schedoscope REST API), the [command client](Command Reference) or the [shell](Command Reference). The views to materialize are addressed using a [pattern syntax](View Pattern Reference), which also allows for addressing multiple views.
For example:
materialize -v app.eci.datamart/SearchExport/SHOP10/2015/05
Materialization proceeds in two phases:
Before materialization itself is started, all views impacted by a materialization command are instantiated. These are the views addressed by the materialization command plus their dependencies, recursively.
Instantiation comprises the following steps:
- instantiating an Akka actor for managing the view's state;
- creating the table for the view if it does not exist;
- create a partition for the view if it does not exist;
- pull transformation timestamp and version information out of the Hive Metastore.
Once Schedoscope has instantiated a view, it remains instantiated. Thus, effectively, less and less views will be initialized during materialization requests after a warmup period.
Once all required views are initialized, materialization itself starts. During that process, essentially, each view (actor) impacted by materialization:
- sends a materialization request to the views (i.e., the view actors) it depends on;
- waits until the dependencies have materialized;
- triggers the execution of its own transformation by passing an appropriate transformation action to the actions manager;
- waits until its transformation has successfully executed;
- stores transformation version and timestamp in the Metastore;
- enters materialized state and notifies any dependent views about its state change.
Schedoscope attempts to automatically detect changes to data, data structure, and application logic and reschedule computation of views accordingly. Change detection is again spread across the phases view instantiation and materialization proper and is based on
-
view DDL checksums: a checksum on a view's
CREATE TABLEDDL statement; -
transformation version checksums: a transformation type-specific checksum on the
transformViaclause of the view (see the respective transformation reference documentation sections in this wiki). One can override a version checksum for a transformation using [defineVersion](Schedoscope View DSL Primer#defining-transformation-versions); - transformation timestamps: timestamp of the last materialization of the view.
During a view's instantiation, Schedoscope checks for the existence of a table for the view in the metastore:
-
In case the table exists, the current view DDL checksum is compared with the checksum of stored with the table in the metastore;
-
If the checksums differ - i.e., if the table structure has changed in any way - the table and all its partitions are dropped and the current
CREATE TABLEstatement is executed. The new view DDL checksum is stored with the table in the metastore.
Moreover, view instantiation also takes care that a table partition is available for each view. Missing partitions are created; for partitions that already exist, view instantiation loads the
- transformation version checksums and
- transformation timestamps
into the respective view actors for use during the following materialization proper phase.
During materialization proper, transformation version checksums and transformation timestamps are used for change detection:
-
when the dependencies of a view have been materialized, the most recent transformation timestamp of the dependencies is compared to the transformation timestamp of the view. If that timestamp is newer, the current view is materialized again because input data might have changed;
-
if the current view's transformation version checksum differs from the one previously stored, the view is rematerialized because transformation logic might have changed;
After rematerialization, transformation version checksum and timestamp are updated in the Hive metastore.
Note that rematerialization of a view results in a new transformation timestamp, which might affect the views depending on that view and trigger their rematerialization.
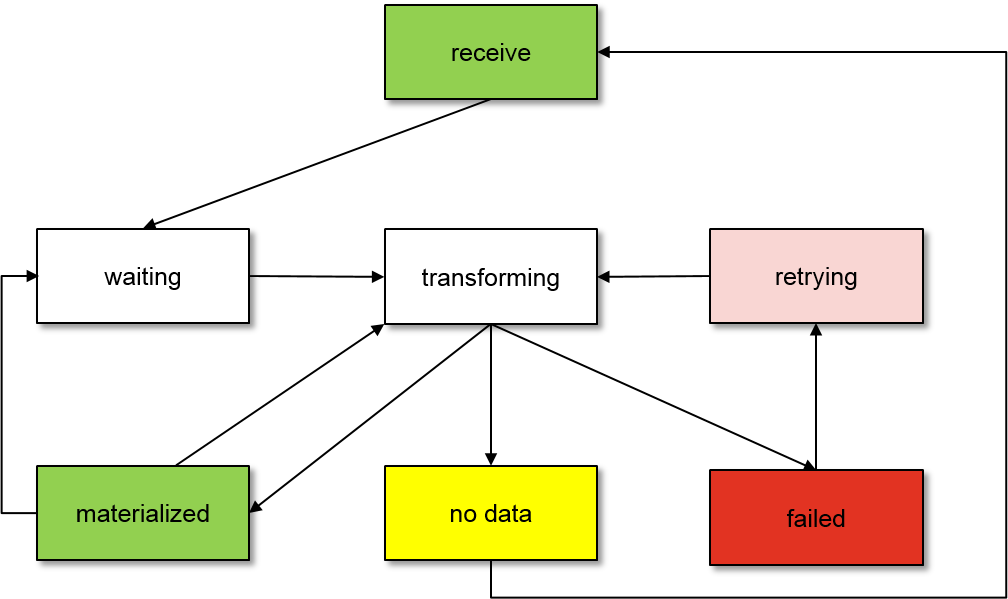
On the way its materialization, a view can go through the following states (see picture above):
| State | Description |
|---|---|
receive |
After initialization, a view enters the receive state. |
no-data |
no-dataindicates that there is no data available for the view. A view enters no-data state upon a materialization request if (a) it has a NoOp transformation and there is no _SUCCESS flag in its fullPath or (b) all its dependencies have entered no-data state. That means if only one dependency has data, the view will not enter no-data state but instead be materialized based on incomplete information. Should data for one dependency appear later, the view will be rematerialized because of the dependency's new transformation timestamp. |
waiting |
A view has received a materialization request, passed it on to its dependencies, and waits for the materialization of its dependencies. If all dependencies have finished their processing or if a view does not have any dependencies, it will enter transforming state |
transforming |
If a view has a NoOp transformation it immediately moves on to no-data state or materialized, depending on whether there is a _SUCCESS_FLAG in its fullPath or not. For other transformation types, the transformation is executed. Depending on the result of the transformation, the view enters materialized, retrying, or failed. |
materialized |
View data has been successfully materialized. Transformation version checksum and timestamp have been recorded with the Hive metastore. If the view receives another materialization request, it will enter waiting state again. |
retrying |
There was an irrecoverable problem during transformation execution but the numbers of retries configured in the schedoscope.action.retry property has not yet been reached. The view will enter transforming state again. Note that network errors will be caught by the actions manager and retried indefinitely. Errors that result in retrying would be OutOfMemoryExceptions and similar problems. |
failed |
A view's transformation has failed even after retrying. Views depending on that view will nevertheless try to materialize themselves even with the view's data missing. Should the view receive a another materialization request, it will enter waiting state again. Should it then succeed with its transformation, depending views will be rematerialized because of view's new transformation timestamp. |
While the default behavior of materialization and rematerialization based on transformation version checksums and timestamps usually should be what you want, there are nevertheless situations in which one would like to bypass this process.
You can force the rematerialization of a view by sending it the invalidate command (see also [Command Reference](Command Reference)). The view will then enter the receive state again; upon receiving a subsequent materialize command, it will consequently be recomputed.
Example:
invalidate -v app.eci.datamart/SearchExport/SHOP10/2015/05
This is generally useful in combination with NoOp stage views. If those receive new or corrected data by an external ETL process, an invalidate will trigger all necessary recomputations of dependant views.
The way how Schedoscope computes transformation version checksums depends on the transformation type. In case of [Hive transformations](Hive Transformations), for instance, a checksum of the query is created (ignoring whitespace, line breaks, SETs, and comments) and combined with the file names of any external UDF library jars.
There may be cases where automatic detection of changes triggers too many false alarms for a given business logic resulting in unnecessary recomputations. In such a situation, one can manually define a version ID for the transformation with defineVersion. Checksums are then computed using the version ID only; consequently, only manual changes to the ID result in a transformation version checksum change.
For example:
transformVia (() =>
HiveQl(
insertInto(this,
queryFromResource("/productWithBrand.sql")
)))
.defineVersion("1.0.0")
.configureWith(Map(
"env" -> this.env,
"shopCode" -> this.shopCode.v.get,
"year" -> this.year.v.get,
"month" -> this.month.v.get,
"day" -> this.day.v.get,
"dateId" -> s"${this.year.v.get}${this.month.v.get}${this.day.v.get}"
))
Changes to transformations might change the transformation version checksum, but the ouput of the computation might not change. For example, one might use a new version of an external UDF library jar file for a Hive transformation, but the UDF called has not changed. In this case, adding the passing the mode RESET_TRANSFORMATION_CHECKSUMS to the materialize command will avoid triggering of rematerializations based on transformation version checksums and update all changed transformation version checksums in the Hive Metastore (see also [Command Reference](Command Reference)).
Example:
materialize -v app.eci.datamart/SearchExport/SHOP10/2015/05 --mode RESET_TRANSFORMATION_CHECKSUMS
It is always possible to bring the whole dependency hierarchy of a view into a stable state. The materialization mode RESET_TRANSFORMATION_CHECKSUMS_AND_TIMESTAMPS performs a "dry run" where transformation checksums and timestamps are computed and set along the usual rules, however with no actual transformations taking place. As a result, all checksums in the metastore should be current and transformation timestamps should be consistent, such that no materialization will take place upon subsequent normal materializations.
Example:
materialize -v app.eci.datamart/SearchExport/SHOP10/2015/05 --mode RESET_TRANSFORMATION_CHECKSUMS_AND_TIMESTAMPS
One can transform an individual view without checking its dependencies using the materialization mode TRANSFORM_ONLY. This is useful when a transformation higher up in the dependency lattice has failed and you want to retry it without potentially rematerializing any dependencies.
Example:
materialize -v app.eci.datamart/SearchExport/SHOP10/2015/05 --mode TRANSFORM_ONLY
Note, however, that the view will get a new transformation timestamp and potentially update its transformation version checksum. If TRANSFORM_ONLY is not applied to top-level views, any dependant views will be transformed upon the next materialization command. So it may be wise to follow up TRANSFORM_ONLY with a RESET_TRANSFORMATION_CHECKSUMS_AND_TIMESTAMPS of dependant views.
You can force a view into the state materialized without performing a transformation using the materialization mode SET_ONLY.
Example:
materialize -v app.eci.datamart/SearchExport/SHOP10/2015/05 --mode SET_ONLY
Again note, that the view will get a new transformation timestamp and potentially update its transformation version checksum. If not applied to top-level views, any dependant views will be transformed upon the next materialization command. So it may be wise to follow up SET_ONLY with a RESET_TRANSFORMATION_CHECKSUMS_AND_TIMESTAMPS of dependant views.
Schedoscope provides a way to gather statistics and monitor view scheduling state-related events throughout time. One can do so by plugging one or more external custom listener classes.
You start by creating a class that implements the trait org.schedoscope.scheduler.listeners.ViewSchedulingListener and override the method viewSchedulingEvent as shown in the following example:
package com.mycompany.datalake.monitoring
class MyViewSchedulingMonitor extends ViewSchedulingListener {
val log = LoggerFactory.getLogger(getClass)
override def viewSchedulingEvent(event: ViewSchedulingEvent): Unit = {
if (event.prevState.label != event.newState.label)
log.info(getMonitInit(event.prevState.view) + getViewStateChangeInfo(event))
}
}
Next, edit the Schedoscope configuration file (for example, in the schedoscope-tutorial it would be the file resources/schedoscope.conf), and add your class to the already existing listeners:
schedoscope {
scheduler {
viewSchedulingListeners = ["org.schedoscope.scheduler.listeners.ViewSchedulingMonitor", "com.mycompany.datalake.monitoring.MyViewSchedulingMonitor"]
}
}
Please note that you probably do not want to remove the default listener org.schedoscope.scheduler.listeners.ViewSchedulingMonitor from the list. Otherwise, you will disable Schedoscope's state change logging.
Upon initialization, Schedoscope attempts to instantiate all classes provided in the configuration file's viewSchedulingListeners list. Non-instantiatable classes or classes throwing an exception upon instantiation are ignored.
While monitoring a view, custom logic contained in a scheduling state listener's viewSchedulingEvent method could fail and throw an exception. The default behavior is to simply restart the listener and drop the view scheduling event that caused the failure.
If the desired behavior is to retry to process the same event, Schedoscope provides a custom exception for it:
package com.mycompany.datalake.monitoring
import org.schedoscope.scheduler.listeners.RetryableViewSchedulingListenerException
class MyViewSchedulingMonitor extends ViewSchedulingListener {
val log = LoggerFactory.getLogger(getClass)
override def viewSchedulingEvent(event: ViewSchedulingEvent): Unit = {
try {
// dangerous block
} catch {
case err: IllegalStateException =>
throw new RetryableViewSchedulingListenerException(err.getMessage, err.getCause)
}
}
}
This informs Schedoscope that, besides restarting the listener, it should resend the last event that occurred for each existing view to the restarted listener.
Schedoscope uses a view scheduling listener manager Akka actor to propagate view scheduling events to their respective listeners. This actor acts as a supervisor and instantiates one child actor for each listener class. To limit the maximum number a listener should be restarted in case of errors, one can define a maximum retry value in the configuration file, as shown in the following example:
akka {
actor {
view-scheduling-listener-actor {
maxRetries = 10
}
}
}
By default this value is set to "-1", which corresponds to infinite.