图3-1 用户用例图
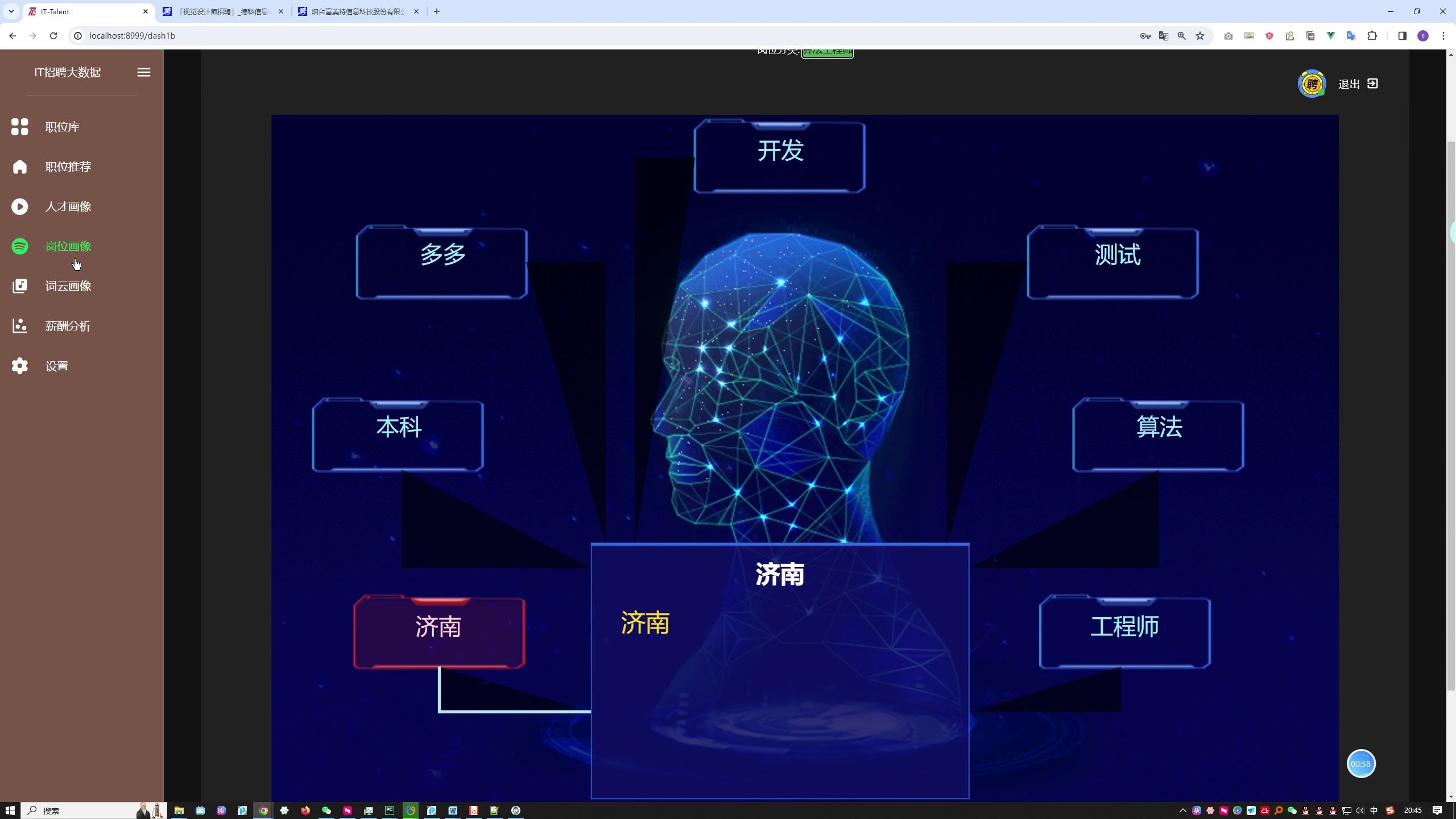
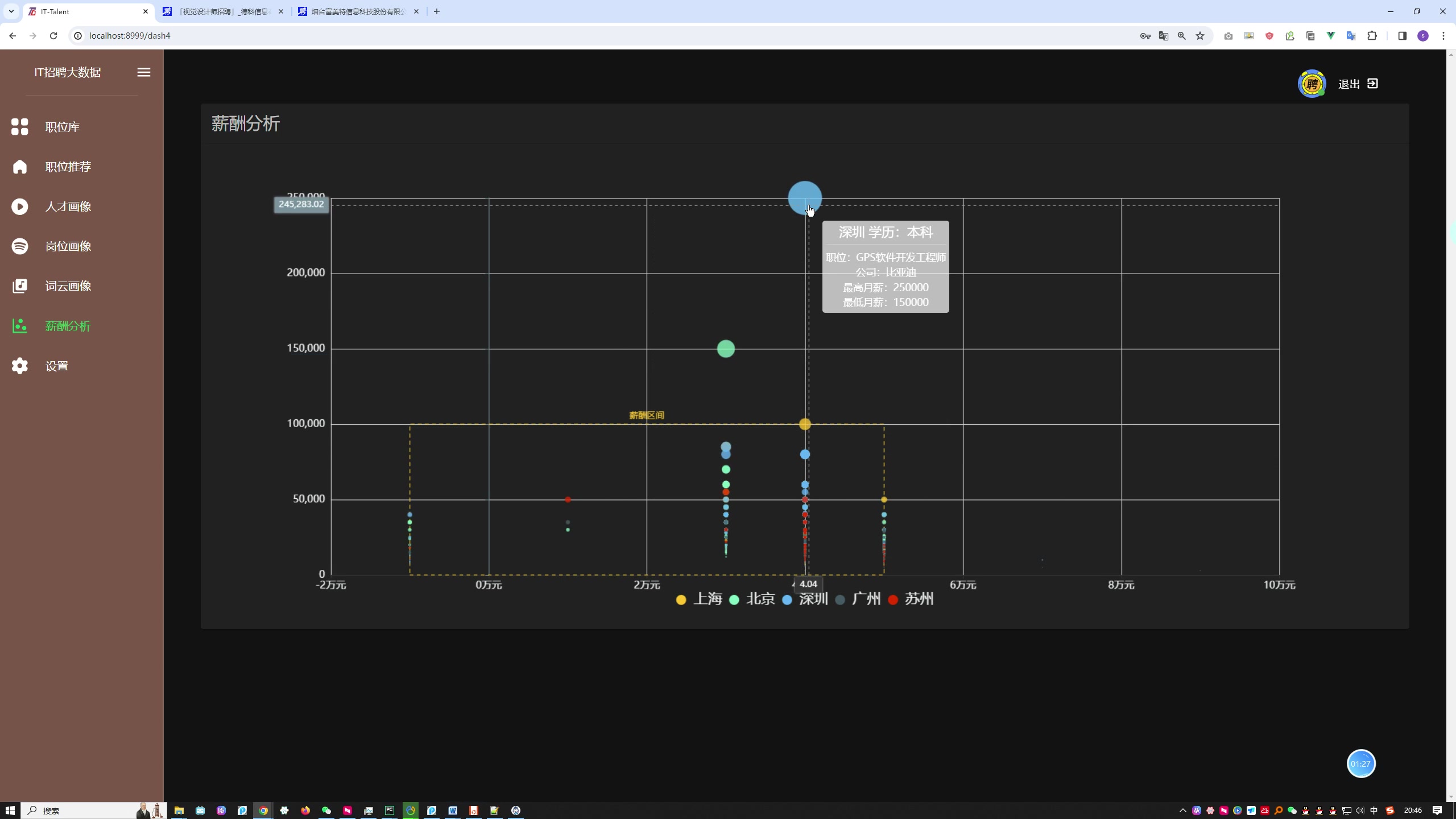
系统智联招聘数据爬取功能旨在从智联招聘网站上获取招聘信息,并将这些信息用于后续的数据分析、可视化等用途。以下是对该功能的分析:- 爬取目标网站:系统需要爬取智联招聘网站上的招聘信息,这些信息包括职位名称、公司名称、工作城市、薪资范围、学历要求、公司类型、公司规模、工作经验、福利待遇等。
- 数据请求与响应: 系统通过发送 HTTP 请求到智联招聘网站的特定页面,获取招聘信息的 JSON 数据格式的响应。响应中包含了所需的招聘信息。
- 数据解析与提取: 系统需要对获取到的 JSON 数据进行解析和提取,从中提取出需要的招聘信息字段,如职位名称、公司名称、薪资范围等。
- 多页处理: 由于招聘信息可能分布在多个页面上,系统需要实现对多页数据的处理。可能需要根据页面的分页信息动态地生成多个请求,获取所有页面的招聘信息。
- 参数化配置: 系统可能需要支持对爬取的参数进行配置,如城市、工作经验要求、学历要求等,以便用户可以灵活地定制爬取条件。
- 异常处理: 在爬取过程中,可能会遇到各种异常情况,如网络异常、页面结构变化等。系统需要实现相应的异常处理机制,保证爬取的稳定性和健壮性。
- 数据存储: 爬取到的招聘信息需要进行有效的存储,以便后续的数据分析和应用。存储可以采用数据库、文件等形式进行。
- 定时任务: 系统可能需要实现定时任务的功能,定期自动执行爬取任务,保持招聘信息的更新和及时性。