Designing RESTful API with Python-Flask and posgres using survey response dataset
This example project demonstrate reading data stored in S3, storing it in local DB for analysis, return the analysis via RESTful API with Python-Flask,
- Creating DB tables needed for the project
- Reading survey response loaded in CSV format from AWS S3 and incrementally ingesting to local database postgresDB (skipping the data injestion, if the file is already in DB)
- Analysing the data in postgres to find, average score, benchmark and the score distribution
- Creating an API that provides access to the data analysis results, (average score, benchmark and the score distribution)
- Dockering the application
configuration.env --> For storing environment variables needed for the project (configuration.bat if the application is run via conda environment)
- config.py --> Centralized configuration to inialize DB connection, logging which will be imported by other python classes
- CreateTables.py --> Creating the DB tables need for the project
- ReadS3AndPopulateDB.py --> ingest the csv files from S3 and store relevant data in the Postgres database
- SurveyAnalysis.py --> computiing the average score and the score distribution, benchmark and Creation of Flask API for the same
You can download this project by cloning the repository:
git clone https://github.com/padmapria/Survey_Data_Analysis_Python.git
NOTE: While working with Python, its recommended to use virtual environment to keep all the project's dependencies isolated from other projects.
-
Clone this git repository in a folder, for example to the folder, C:/Survey_Data_Analysis_Python
-
Edit the startup.bat located in the scripts folder of this git project. Modify the venv_root_dir
set venv_root_dir="D:\Survey_Data_Analysis_Python\scripts"
to
set venv_root_dir="C:\Survey_Data_Analysis_Python\scripts"save the changes
-
Edit the start_app.bat located in the scripts folder of this git project. Modify the path pointing to the python file.
python D:\Survey_Data_Analysis_Python\src\config.py
python D:\Survey_Data_Analysis_Python\src\CreateTables.py
python D:\Survey_Data_Analysis_Python\src\ReadS3AndPopulateDB.py
python D:\Survey_Data_Analysis_Python\src\SurveyAnalysis.pyto
python C:\Survey_Data_Analysis_Python\src\config.py
python C:\Survey_Data_Analysis_Python\src\CreateTables.py
python C:\Survey_Data_Analysis_Python\src\ReadS3AndPopulateDB.py
python C:\Survey_Data_Analysis_Python\src\SurveyAnalysis.pysave the changes
-
Run the startup.bat located in the scripts folder
The above steps will automatically
1) create a local conda environment
2) installing the dependencies given in the requirements.txt located in the scipts folder
3) Injesting data from s3 to postgresDB
4) Starting the application
Once the application is started, go to localhost on Postman to test the API.
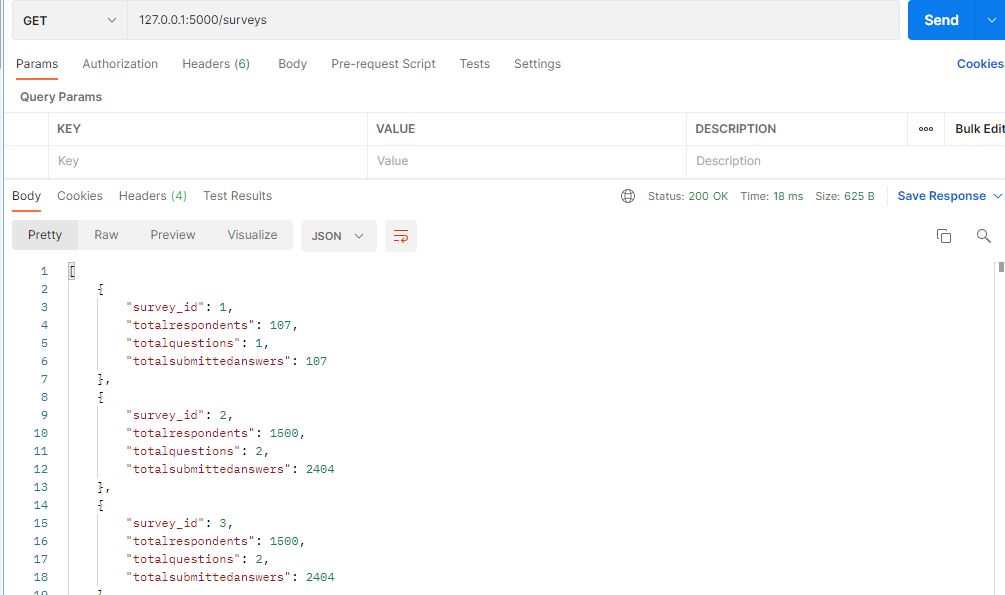
127.0.0.1:5000/surveys
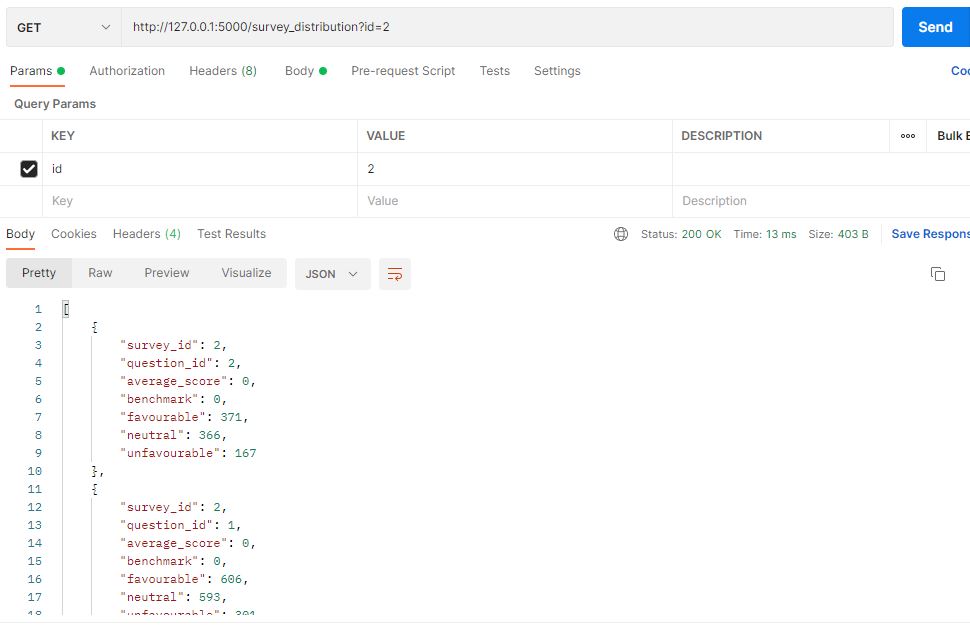
http://127.0.0.1:5000/survey_distribution?id=2
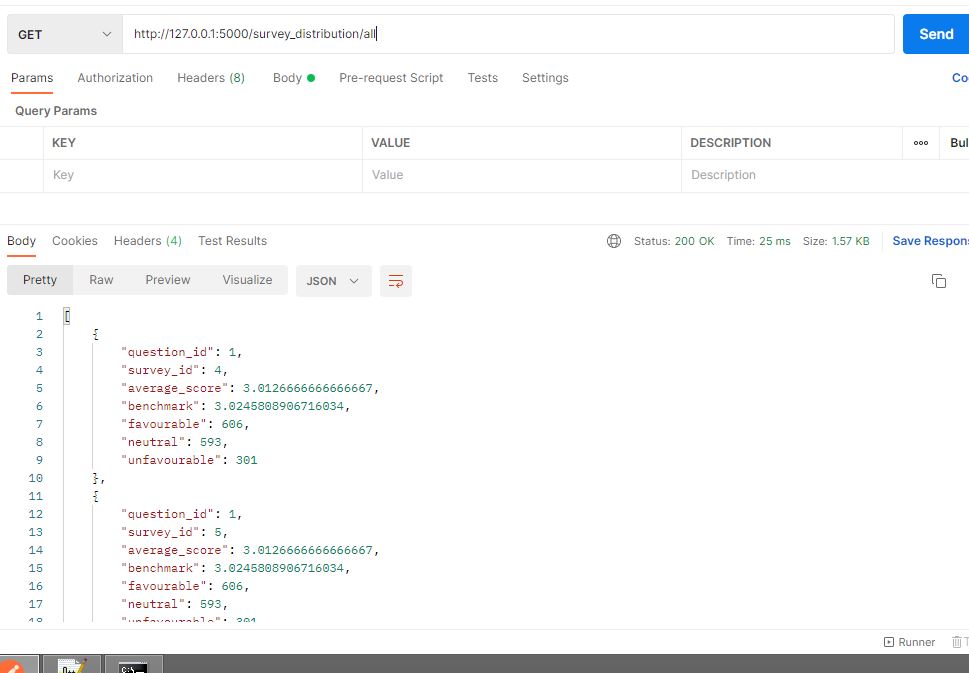
http://127.0.0.1:5000/survey_distribution/all
conda init
conda create -n Survey_Data_Analysis_Python python=3.7 anaconda # To create the environment
activate Survey_Data_Analysis_Python # To activate the environment
pip install -r requirements.txt
Start posgres Server
Change the DBNAME in the config file (configuration.env/configuration.bat) according to the database name you are using.
Start the application to test locally using the below command
python config.py
Once the application is started, go to localhost on Postman to test the API, using the endpoint given above.