Tokenizers do not handle accented characters correctly #10
Description
I'm using diffx to diff XML, and the tokenizers are splitting words when they contain accented characters.
This was reported in tuskyapp/Tusky#3314, which has this screenshot:
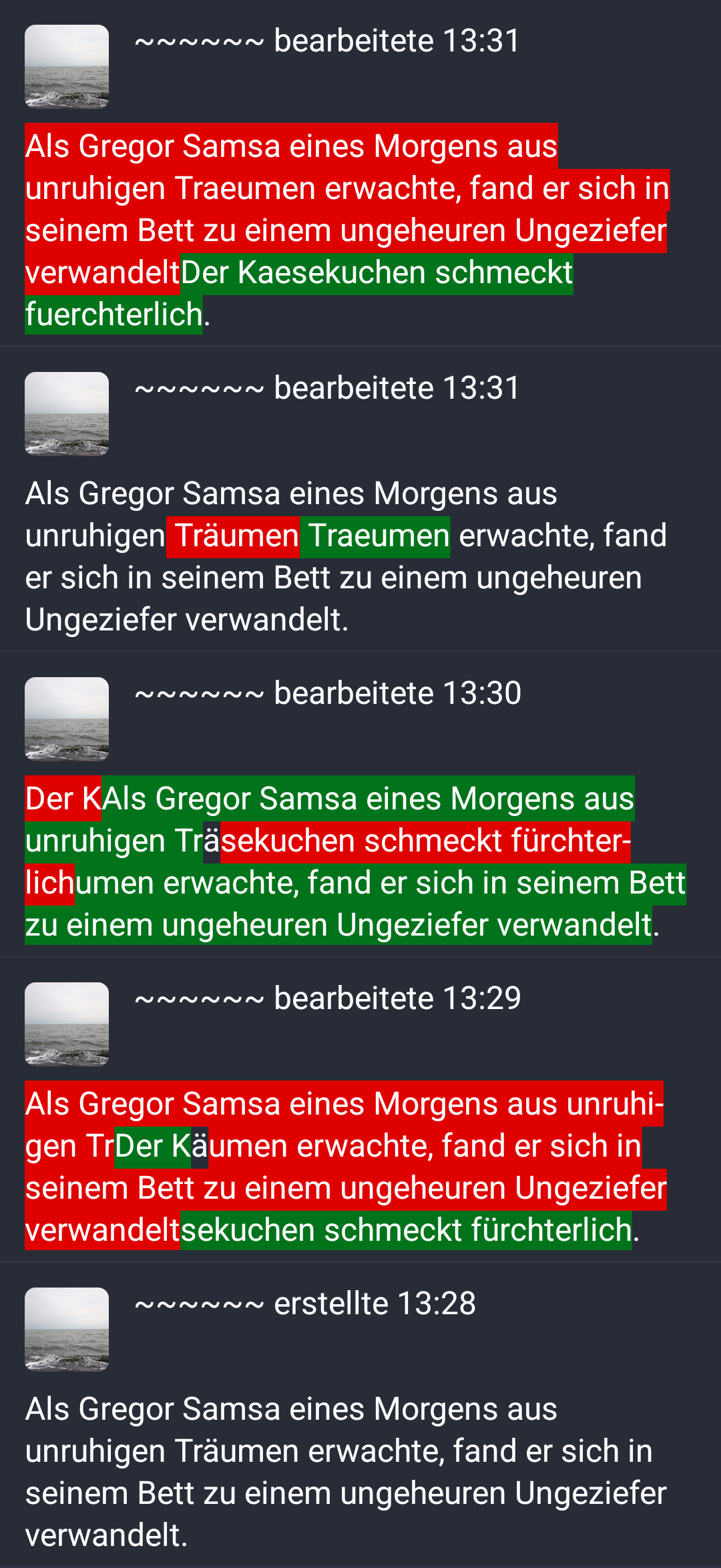
Notice how in the last-but-one item in the list the word "Käumen" has been split at the "ä".
@sl1txdvd who reported it to us has a fix to the regex in master...sl1txdvd:diffx:unicode.
Separately, I tried to fix this by writing a new tokenizer based on TokenizerBySpaceWord, but when I did this I quickly discovered:
- All the classes are final, so I couldn't simply extend an existing tokenizer, I would have to write a new one
- There is no mechanism for plugging a custom tokenizer in to the processing pipeline, and again, all the classes are final, so actually doing this would require forking the project
Please consider making it easier to override this functionality, thanks.