

{kind=link}
gitwalk is a tool to manipulate multiple git repositories at once. You select a group of repos using an expression and provide an operation to be completed. Gitwalk will download the repos, iterate through them and run the operation for each one. This may be searching through files and commits, running tests and linters, editing files and pushing the changes back upstream — whatever you can think of.
gitwalk is made in CoffeeScript and runs on Node.js. nodegit and node-github do most of the heavy lifting in the background.
## Features
- Wildcard matching
- Integrates directly with GitHub API
- Works with private repos via GitHub auth
- Authenticated pushes via ssh and http
- Lets you define groups of repositories
- Built-in search tool
- Easily extensible with new expressions and processors
- Usable from the CLI as well as JavaScript
Gitwalk is distributed as an npm package. Use the following command to install it on your system:
$ npm install -g gitwalkMake sure to include -g to get the CLI command in your $PATH.
The interface is pretty straight-forward. Here's the synopsis:
gitwalk [options] <expr...> <proc> <proc-args>
The first positional arguments are expressions that determine which repositories will be processed. You can pass one or more of them at the same time. The next one is your preferred processor which specifies what will happen with the repositories, followed by any arguments that it takes — usually a command, but different processors support different ones.
Check out the expressions and processors sections below for the details.
Here are a few quick examples that should work out of the box. Paste them in your terminal and see what happens.
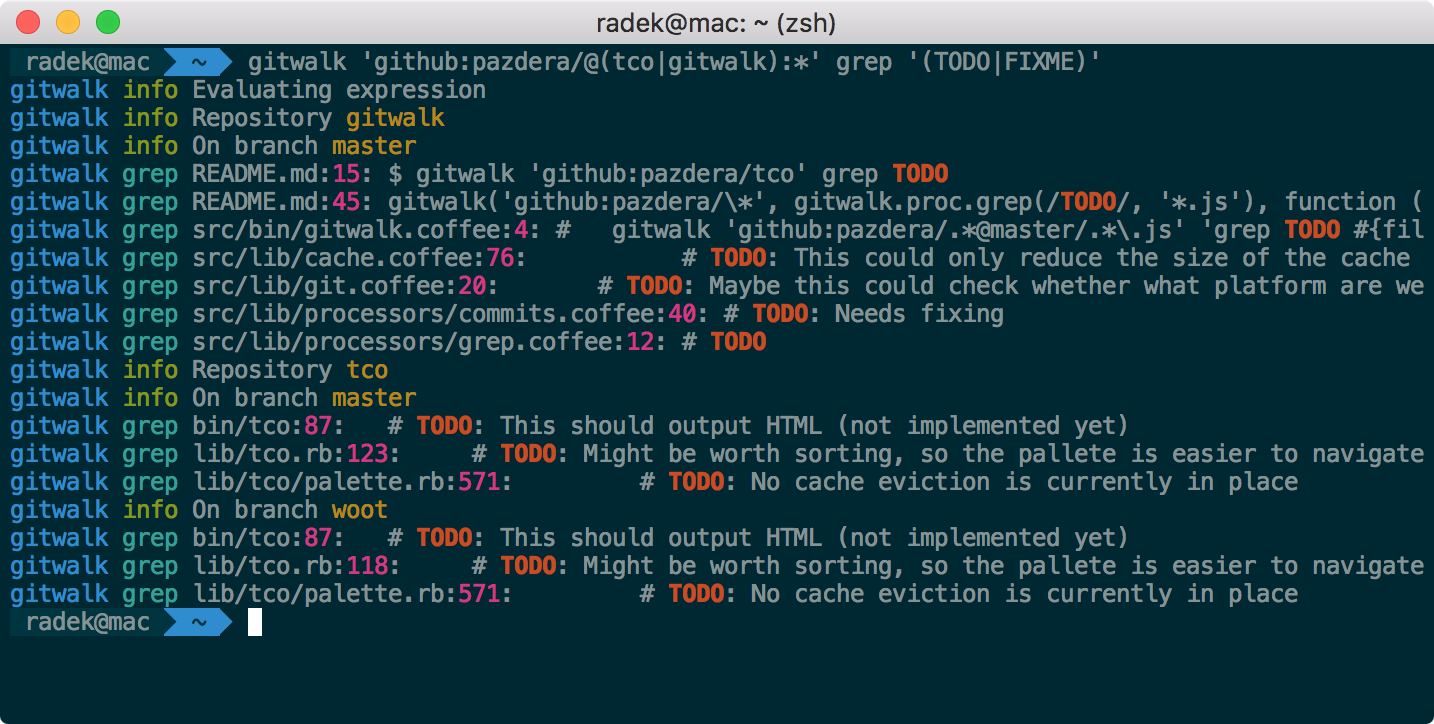
$ gitwalk 'github:pazdera/tco:*' grep TODO
$ gitwalk '**/*' command 'tree .'
$ gitwalk 'github:pazdera/@(catpix|word_wrap)' commits 'echo "#{sha}: #{summary}"'Expressions determine which repositories will be processed by the gitwalk
command. You can provide one or more of them and their results will be
combined. Check out the following examples:
# Matches all branches of the npm repo on GitHub.
$ gitwalk 'github:npm/npm:*' ...
# Matches all the git repositories in my home dir.
$ gitwalk '~/**/*' ...
# Use ^ to exclude previously matched repositories.
# Matches all my repos on GitHub _except_ of scriptster.
$ gitwalk 'github:pazdera/*' '^github:pazdera/scriptster' ...
# URLs work too.
$ gitwalk 'https://github.com/pazdera/tco.git:*' ...
# You can predefine custom groups of repositories.
# Check out the _Groups_ resolver below.
$ gitwalk 'group:all-js' 'group:all-ruby' ...What comes after the last colon in each expression is interpreted as branch
name. If omitted, gitwalk assumes master by default. Also note that you can
use globs for certain parts.
Check out the detailed description of each resolver below for more information.
Under the hood, each type of expression is handled by a resolver. What follows is a description of those that come with gitwalk by default. However, it's really easy to add new ones. See the contribution guidelines.
With this resolver, you can match repositories directly on GitHub. Gitwalk will make queries to their API and clone the repositories automatically.
github:<username>/<repo>:<branch>
- username: GitHub username or organisation.
- repo: Which repositories to process (glob expressions allowed).
- [optional] branch: Name of the branch to process (glob expressions allowed).
To be able to work with private repositories, you need to give gitwalk either your credentials or auth token. Put this into your configuration file:
{
"resolvers": {
"github": {
"username": "example",
"password": "1337_h4x0r",
"token": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}
}
}Pushing to repositories on GitHub again requires authentication. You'll need to give gitwalk either your SSH keys or credentials via the config file. Here's how to do it:
{
"git": {
"auth": {
"github-http-auth": {
"pattern": "^https?\\:\\/\\/github\\.com",
"username": "example",
"password": "1337_h4x0r"
},
"github-ssh-auth": {
"pattern": "^git@github\\.com",
"public_key": "/Users/radek/.ssh/id_rsa.pub",
"private_key": "/Users/radek/.ssh/id_rsa",
"passphrase": ""
}
}
}
}You can match repositories on your file system using glob. Note that gitwalk will clone the repository even if it's stored locally on your computer. One can never be too careful.
<path>:<branch>
- path: Location of the repositories (glob expressions allowed).
- [optional] branch: Name of the branch to process (glob expressions allowed).
URLs aren't a problem eiter. Gitwalk will make a local copy of the remote repository and process it. However, you can't do any wildcard matching with URLs.
<url>:<branch>
- url: An URL pointing to a git repository (glob not allowed).
- [optional] branch: Name of the branch to process (glob expressions allowed).
You can define custom groups of expressions that you can refer to by name later on. There are no predefined groups.
group:<name>
- name: Name of the group.
Groups of expressions can be defined in the configuration file like this:
{
"resolvers": {
"groups": {
"all-ruby": [
"github:pazdera/tco",
"github:pazdera/scriptster",
"github:pazdera/catpix"
],
"c": [
"github:pazdera/*itree*:*",
"^github:pazdera/e2fs*"
],
"c++": [
"github:pazdera/libcity:*",
"github:pazdera/OgreCity:*",
"github:pazdera/pop3client:*"
]
}
}
}Processors are tasks that you can run on each of the repositories that were matched by your expressions. Just as with expressions, it's really easy to add your own. Here are the ones that ship with gitwalk by default:
# Search for unfinished work in all JavaScript files
$ gitwalk ... grep '(TODO|FIXME)' '**/*.js'
# List all files in the repository
$ gitwalk ... command 'tree .'
# Another way to search the files
$ gitwalk ... command 'git grep "(TODO|FIXME)"'
# Replace the year in all Ruby files
$ gitwalk ... files '**/*.rb' 'sed -i s/2015/2016/g #{file}'
# Simple commit message profanity detector
$ gitwalk ... commits 'grep "(f.ck|sh.t|b.llocks)" <<<"#{message}"'The #{hashCurlyBraces} templates will be expanded into values before the
command is executed. Each command exports different set of variables; check
out the detailed descriptions below to find out more.
Line-by-line search through all the files in the working directory using regular expressions, similar to grep.
$ gitwalk ... grep <pattern> [<files>]- regexp: The pattern to look for.
- (optional) files: Limit the search to certain files only (glob expressions allowed). Searches all files by default.
Run a custom command for each file in the repository. The path parameter
lets you match only certain files.
$ gitwalk ... files <path> <command>- path: Path filter (glob expressions allowed).
- command: A command to run for each file
- Expored vars
- #{file}
- Expored vars
Run a command for each
$ gitwalk ... commits <command>- command: A command to run for each commit.
- Expored vars
- #{sha}
- #{summary}
- #{message}
- #{author}
- #{committer}
- Expored vars
Run a command per repository. This is useful for running custom scripts. The
current working directory for the command is set to the working tree of
gitwalk's local clone. You should be able to use the git command as usual.
$ gitwalk ... command <command>- command: A command to run for each repository.
Providing a config file isn't mandatory. However, you'll need one if you want to be able to git-push or access private repositories. Gitwalk loads the following files:
~/.gitwalk.(json|cson)/etc/gitwalk.(json|cson)
Both json and cson formats are accepted. Here's how a basic gitwalk config
might look like:
{
"resolvers": {
"github": {
"token": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
},
},
"git": {
"auth": {
"github-ssh": {
"pattern": "^git@github\\.com",
"public_key": "/Users/radek/.ssh/github.pub",
"private_key": "/Users/radek/.ssh/github",
"passphrase": ""
}
}
},
"logger": {
"level": "debug"
}
}The JS API is similar to the CLI interface:
var gitwalk = require('gitwalk');
gitwalk('github:pazdera/\*', gitwalk.proc.grep(/TODO/, '*.js'), function (err) {
if (err) {
console.log 'gitwalk failed (' + err + ')';
}
});If you found a bug, please open a new issue with as much relevant information as possible. And in case you'd like to jump in and get your hands dirty, here are a few ideas to get you started:
- Add new resolvers (BitBucket and other services)
- Add new processors (profanity search, integration with linters)
- The tests are atrocious (please help me write them!)
- Finish writing the API docs
If you start working on something, feel free to create an issue or drop me a line to make sure you're not working on the same thing as somebody else.
Radek Pazdera <me@radek.io> http://radek.io
Please see LICENCE.