Update SJIS-mac mappings to use Unicode codepoints which were added after Unicode 1.0 #10264
Conversation
The conversion tables used by mbstring were made a long time ago. Since that time, a lot of characters have been added to Unicode. This means that in some cases, we now have Unicode codepoints available which are a better match for characters in other legacy charsets. For MacJapanese, there are at least 7 mappings which can be updated to make use of newer Unicode codepoints: • 0x869E -> U+213B FACSIMILE SIGN (added in Unicode 4.0) Previously, we used a special "Apple transcoding hint" codepoint U+F861 to indicate that the following 3 codepoints should be treated as a single character. Then we used the ASCII letters 'F', 'A', 'X'. However, U+213B explicitly includes all three of the Latin letters 'FAX' as a single character. • 0x86D3 -> U+27A1 BLACK RIGHTWARDS ARROW (Unicode 1.1) • 0x86D4 -> U+2B05 LEFTWARDS BLACK ARROW (added in Unicode 4.0) • 0x86D5 -> U+2B06 UPWARDS BLACK ARROW (added in Unicode 4.0) • 0x86D6 -> U+2B07 DOWNWARDS BLACK ARROW (added in Unicode 4.0) Previously, we used a different special "Apple transcoding hint" codepoint U+F87A to indicate that the color palette should be reversed when rendering the following codepoint, to make white color into black and black color into white. This was done because there were no Unicode codepoints at the time which specifically represented black-colored arrows. But... now there are. • 0xEB6D -> U+FE47 PRESENTATION FORM FOR VERTICAL LEFT SQUARE BRACKET (added in Unicode 4.0) • 0xEB6E -> U+FE48 PRESENTATION FORM FOR VERTICAL RIGHT SQUARE BRACKET (added in Unicode 4.0) Previously, yet another special "Apple transcoding hint" codepoint U+F87E was used to indicate that a 'vertical form' should be used when rendering the following codepoint. However, we now have codepoints which specifically represent vertical forms for square brackets. Although we are now making use of newer codepoints to reduce the number of cases where we need to map one MacJapanese character to a sequence of several codepoints, we still convert the old sequence of codepoints back to the same MacJapanese character (for backwards compatibility). There are likely other cases where we could make good use of newer Unicode codepoints, both in MacJapanese and in other legacy text encodings. As these come to my attention, I would like to continue modernizing the mappings used by mbstring.
Use another 7 newer Unicode codepoints which match legacy SJIS-mac characters better than what we are currently mapping them to. • 0x8591 -> U+1F100 DIGIT ZERO FULL STOP (added in Unicode 5.2) We previously used an "Apple transcoding hint" to indicate that the next two codepoints should be treated as a single character, then the ASCII characters '0', '.' • 0x8645 -> U+1F13C SQUARE M (added in Unicode 6.0) • 0x864B -> U+1F136 SQUARE G (added in Unicode 6.0) Legacy Japanese charsets include various symbols inside of squares; Unicode 6.0 added all the letters of the Latin alphabet inside squares specifically to allow lossless mapping to and from such charsets. • 0x86CE -> U+21F5 DOWNWARDS ARROW LEFTWARDS OF UPWARDS ARROW (added in Unicode 3.2) We previously used an "Apple transcoding hint" to indicate that the next two codepoints should be treated as a single character, then the Unicode codepoints U+2193 DOWNWARDS ARROW, U+2191 UPWARDS ARROW. • 0xEB41 -> U+FE11 PRESENTATION FORM FOR VERTICAL IDEOGRAPHIC COMMA • 0xEB42 -> U+FE12 PRESENTATION FORM FOR VERTICAL IDEOGRAPHIC FULL STOP • 0xEB63 -> U+FE19 PRESENTATION FORM FOR VERTICAL HORIZONTAL ELLIPSIS (all added in Unicode 4.1) We previously used an "Apple transcoding hint" to indicate that a vertical form should be used when rendering the following codepoint, then a codepoint such as U+3001 IDEOGRAPHIC COMMA. Now we have codepoints specifically for the vertical form of these symbols.
|
@alexdowad I have a question. Where is from Its not ftp://ftp.unicode.org/Public/MAPPINGS/VENDORS/APPLE/JAPANESE.TXT isn't it? |
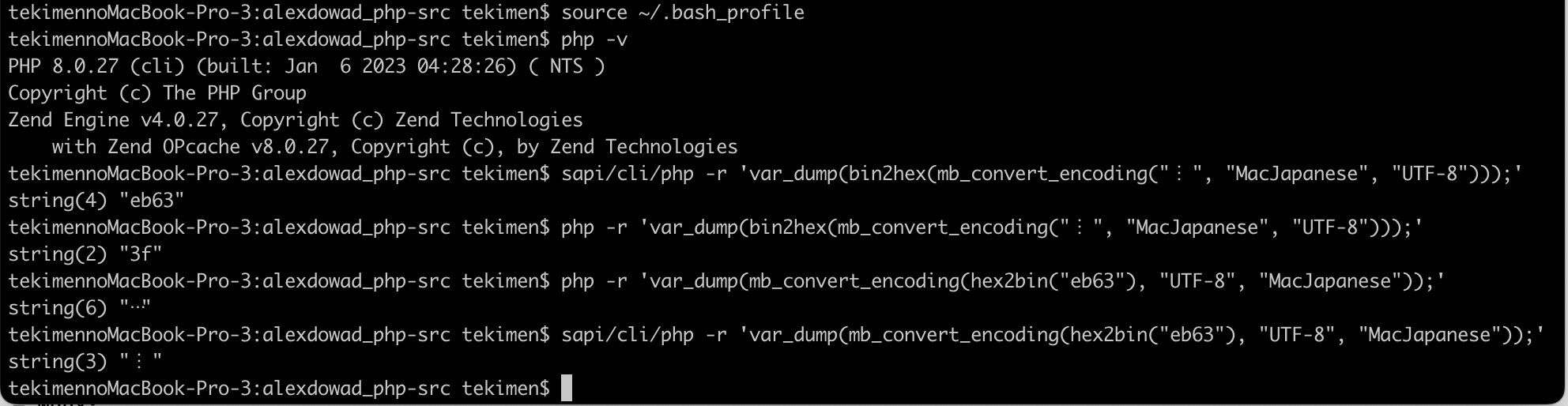
Thanks for sharing that example. I believe that in MacJapanese 0xEB63 is supposed to be a "vertical form" of the ellipsis, so from looking at the screenshot you kindly shared, I think the glyph which shows is actually more correct than the other one.
Yes, that should be the one. |
|
I convert SJIS-mac Reference from https://unicode.org/Public/MAPPINGS/VENDORS/APPLE/JAPANESE.TXT of comment is But, looks like
Therefore, I think result of |
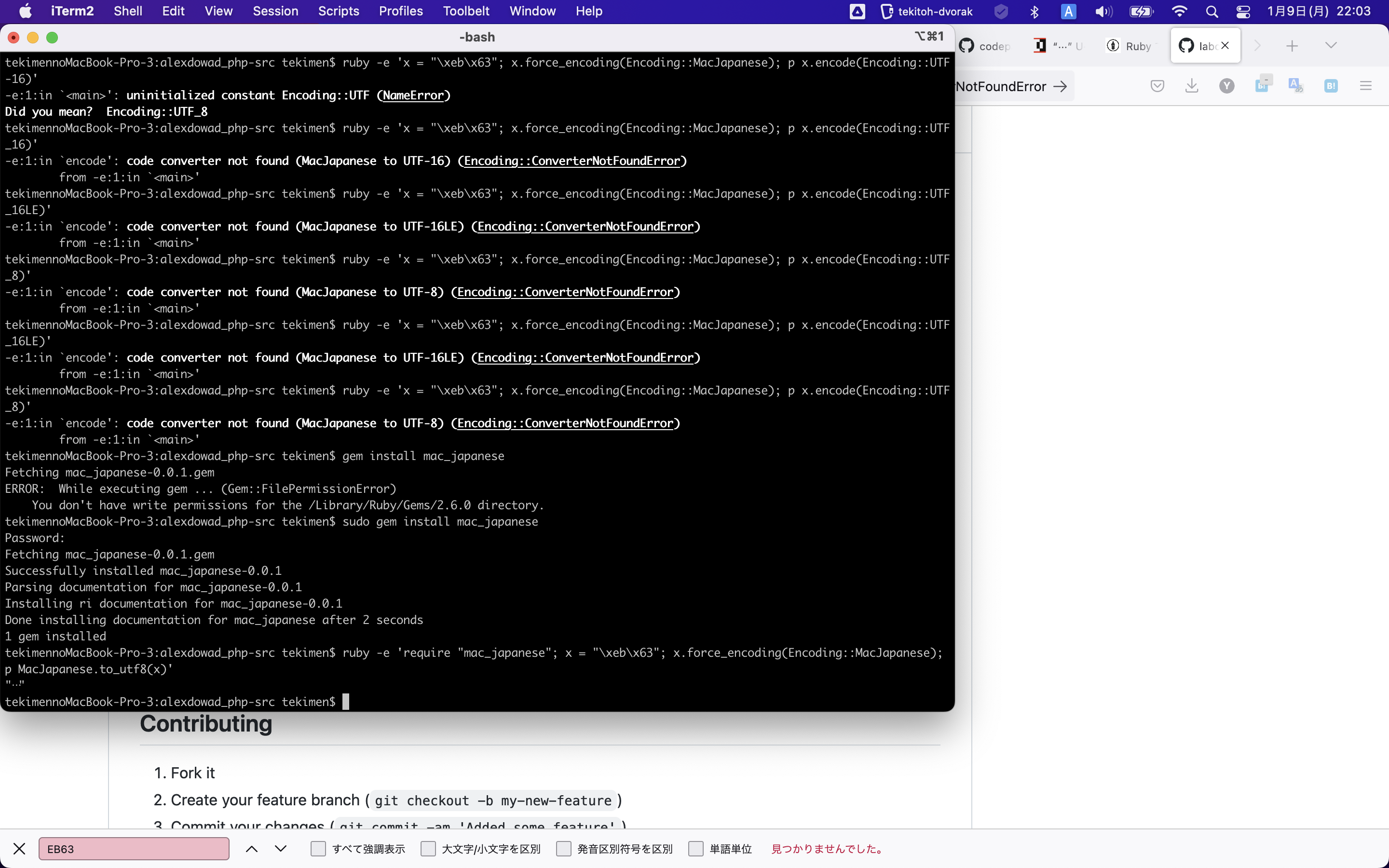
Fair enough. It does raise the question of what What do you think about the other mappings? |
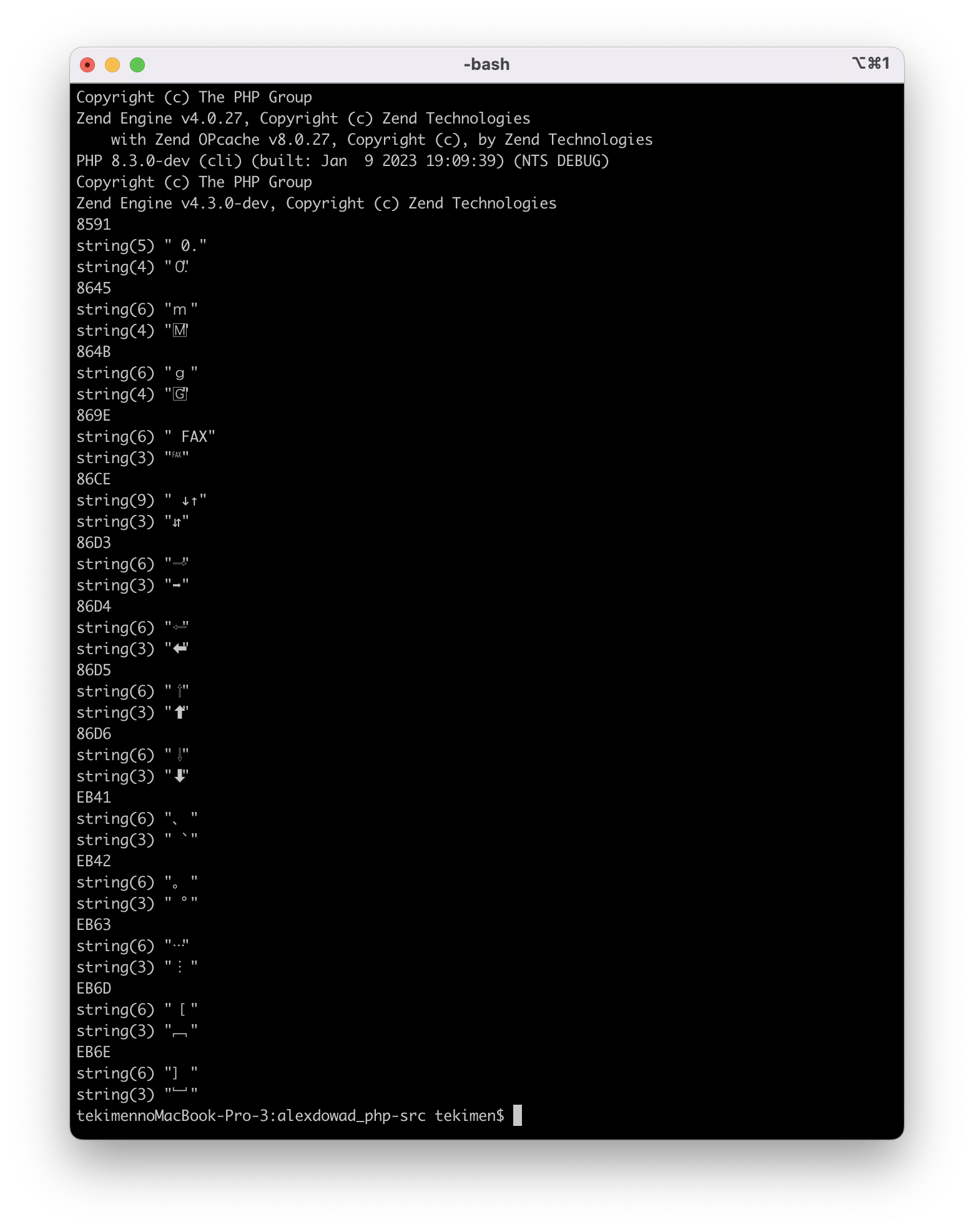
I search different to PHP 8.0 and this PR, I created shell script to all differents character. It seems any meaning characters that all characters. My macOS font (Monaco), there is no rectangle. |
|
Thanks for the testing.
Sorry, I'm not very sure what this means, but would like to understand more. Could you kindly explain a bit more? (英語が難しかったら、日本語も読めます。) |
|
@alexdowad ありがとうございます。それではお言葉に甘えて日本語でお伝えします。 WikipediaのMacJapaneseが参考になるかと思いますが、このPull RequestではUnicodeコードポイントの互換がないため、違う文字に変換されてしまいます。 MacJapaneseとは何なのかを調べていくと、Macが日本の印刷所で使われていた時代に、自ら外字を当てはめていったものを、Appleが取り込んだとする説を見ることができました。Macが日本の印刷所で使われていた時代、となると1990年代から2000年代あたりだと思います。 MacJapaneseでは、複数のUnicodeコードポイントを用いて表現する文字がありえますが、この文字を再現し、満足に表示できるフォントは現代においてはほぼ無いと考えられ、違うUnicodeコードポイントで復元することは何らかの文字列を破壊する可能性があります。そのため、「It seems any meaning characters that all characters.」という文章を書いてしまいました。 従って、後方互換性の破壊(BC breaks)になりうるため、なるべく維持するのが望ましいです。 参考 |
|
@youkidearitai Thanks for your research. Brief summary for others who are following this discussion in English: @youkidearitai did some research on the background of MacJapanese encoding. He says that it dates back to the time when classic Macs were used in Japanese printing companies, around the 1990s and early 2000s. @youkidearitai further says that fonts which can faithfully recreate the same characters which were used on those classic Macs may not be available on modern platforms, and if we try to recreate them using other Unicode codepoints, it might cause breakage, so he would prefer that we avoid changing the mappings as much as possible. |
|
My response is as follows. I think there is a very simple way to determine whether any Unicode codepoints in the current Unicode standard can faithfully represent characters used on classic Macs or not: find someone who has a classic Mac running a Japanese build of MacOS, get screenshots showing how the characters in question appeared, and compare them to the glyphs which are available on modern personal computers. I don't know if I will actually do that or not. If I have time, I might try. |
|
@alexdowad *1: Re @youkidearitai's comment "to break strings of some sort" From a consistency standpoint, whether the glyph shapes are identical is not the main problem by the way. Its mapping for those glyphs had been defined as such. It is unfortunate that many fonts today may not have such ligatures defined in them, making it not possible to display the sequences correctly even on macOS. That being said, with the late comment, I've made the SJIS glyph table displayed on Mac OS 9: https://github.com/ranvis/sjis-pict/wiki/samples |
|
@ranvis Thanks for your comments. If it wasn't clear, this PR was not merged and there are currently no plans to merge it. Let me close it now. |
I expect @youkidearitai will be particularly interested in this one?
Probably a lot of the other legacy text encodings supported by mbstring could benefit from similar updates.
@cmb69 @Girgias @nikic @kamil-tekiela @youkidearitai