
NormaTEI è un software per l'analisi del contenuto di uno o più file XML. NormaTEI è progettato principalmente per due utilizzi:
- controllo dell'uniformità di codifica: quando un'edizione XML/TEI è formata da più file, NormaTEI permette di controllarli in maniera organica, permettendo di individuare facilmente errori o scelte di codifica difformi;
- analisi della codifica: ricerche personalizzate e complesse sul corpus selezionato (uno o più file).
Il nome "Norma" richiama sia l'operazione per cui il software è stato sviluppato ("normalizzazione") che la più famosa opera di Vincenzo Bellini: NormaTEI è stato sviluppato infatti durante la realizzazione di Bellini Digital Correspondence, © Cnr Edizioni, 2023 ISBN: 978-88-8080-562-5, edizione elettronica.
- Daria Spampinato (ISTC-CNR)
- Angelo Mario Del Grosso (ILC-CNR)
- Laura Mazzagufo (UNIPI)
- Pierpaolo Sichera (ILIESI-CNR)
- Salvatore Cristofaro (ILIESI-CNR)

NormaTEI è stato sviluppato utilizzando 4D (https://www.4d.com/). Tra le molteplici caratteristiche di questa piattaforma sono stati sfruttati il supporto nativo XML grazie alla libreria Xerces di Apache Foundation e l’accesso alla struttura di un XML tramite lo standard DOM (Document Object Model). NormaTEI è compatibile con Windows 10 – Windows 11 - da Windows Server 2012 R2 a Windows Server 2022 - da macOS Big Sur (11) a macOS Ventura (13) (le ultime release per ogni versione).
Per utilizzare NormaTEI:
- scarica la cartella Windows (scaricando l'intero repository oppure saricando la singola cartella tramite servizi o software di download);
- estrai i file compressi per ottenere un file zip che puoi estrarre nella cartella che preferisci e poi esegui il file NormaTEI.exe.
- vai su "Impostazioni di sistema -> Privacy e sicurezza" e controlla che sia attiva la voce "Dovunque". Nel caso in cui la voce "Dovunque" non fosse presente la si può abilitare con questo comando dato da Terminale:
sudo spctl --master-disable
- scarica la cartella MacOSX (scaricando l'intero repository oppure scaricando la singola cartella tramite servizi o software di download);
- estrai i file compressi per ottenere un file zip che puoi estrarre nella cartella che preferisci e poi esegui il file NormaTEI.app;
- nota (1): se hai provato ad aprire NormaTEI.app prima di andare su "Privacy e sicurezza", il sistema operativo ti potrebbe aver restituito un errore, impedendo l'apertura dell'applicazione. In questo caso cancella il file ed effettua nuovamente il download e l'estrazione;
- nota (2): per abilitare nuovamente Gatekeeper (nel caso lo avessi disattivato) basterà dare lo stesso comando inserendo la parola enable:
sudo spctl --master-enable
NormaTEI offre due modalità di ricerca:
- Standard: per ricerche semplici, consente di trovare rapidamente errori di codifica;
- Avanzato: per l'analisi e la valutazione approfondita dei corpus.
Al primo avvio potrebbe comparire una finestra per la creazione del file di dati.
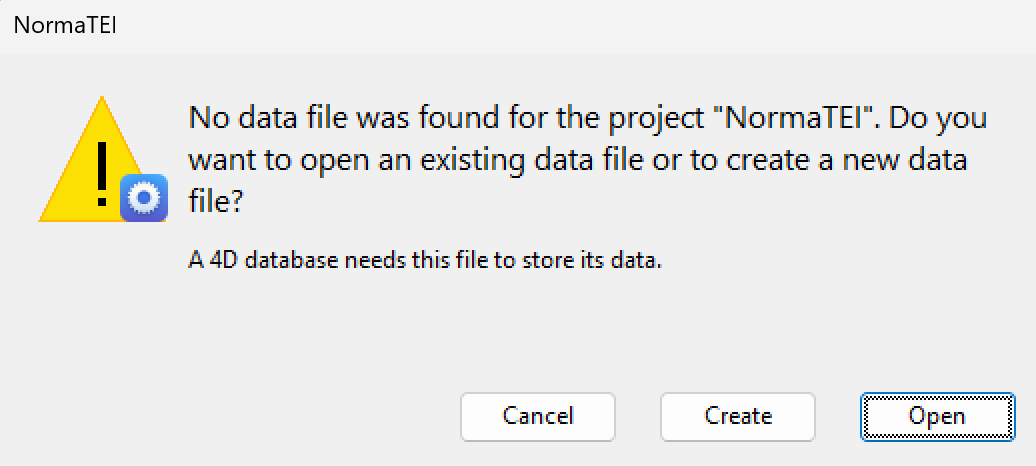 Scegli "Create" e salvalo dove vuoi, NormaTEI ricorderà il percorso utilizzato.
Scegli "Create" e salvalo dove vuoi, NormaTEI ricorderà il percorso utilizzato.
 Nella finestra di avvio cliccare su "Cambia...", per scegliere la cartella contenente i file XML, poi premi il tasto "Importa e analizza".
Se hai gia importato dei file, puoi visualizzare i risultati senza eseguire una nuova importazione col pulsante in basso "Apri i file già caricati".
Puoi aprire più finestre di importazione e analisi contemporaneamente andando sulla finestra pricipale del programma e scegliendo la voce di menu "Start NormaTEI".
Nella finestra di avvio cliccare su "Cambia...", per scegliere la cartella contenente i file XML, poi premi il tasto "Importa e analizza".
Se hai gia importato dei file, puoi visualizzare i risultati senza eseguire una nuova importazione col pulsante in basso "Apri i file già caricati".
Puoi aprire più finestre di importazione e analisi contemporaneamente andando sulla finestra pricipale del programma e scegliendo la voce di menu "Start NormaTEI".
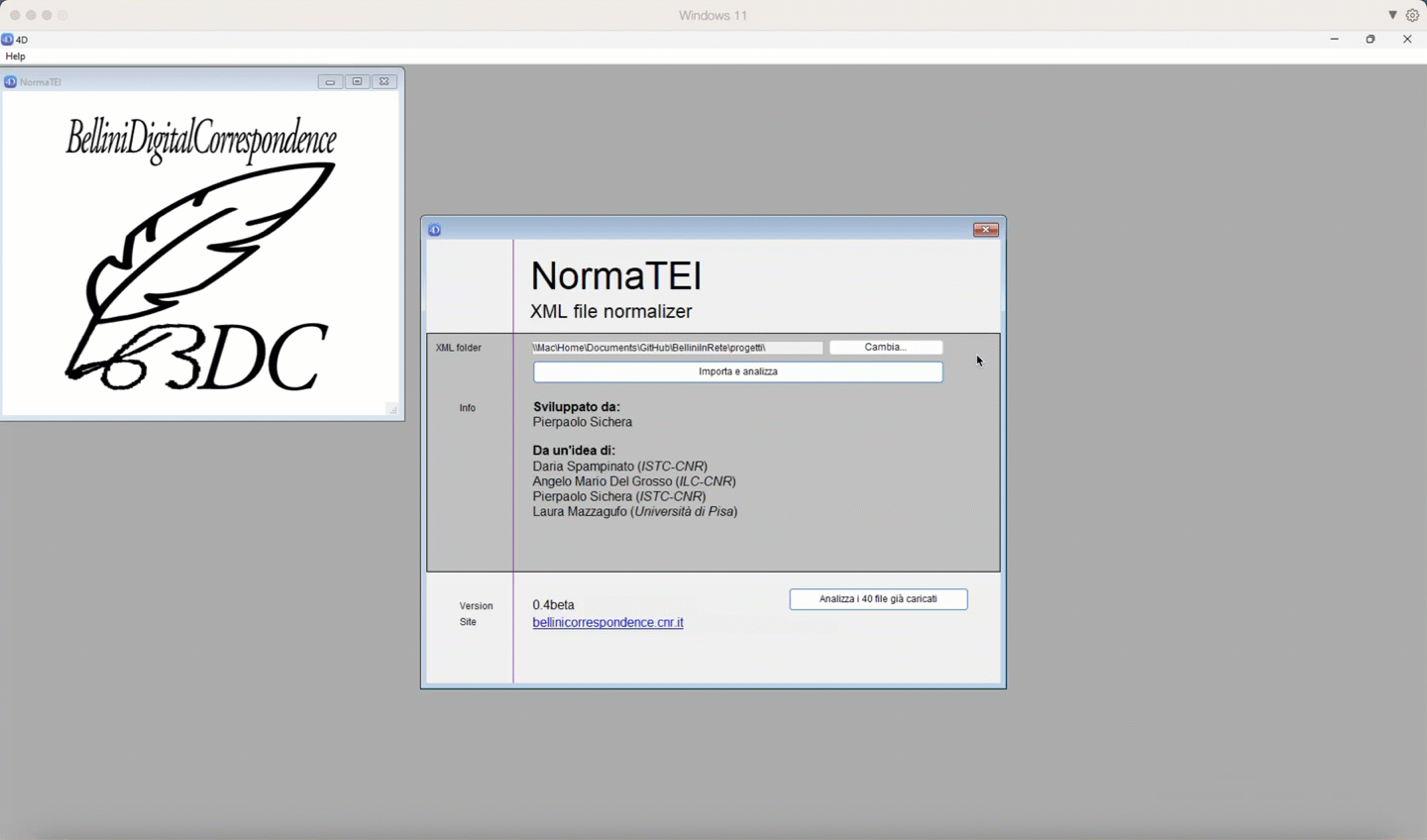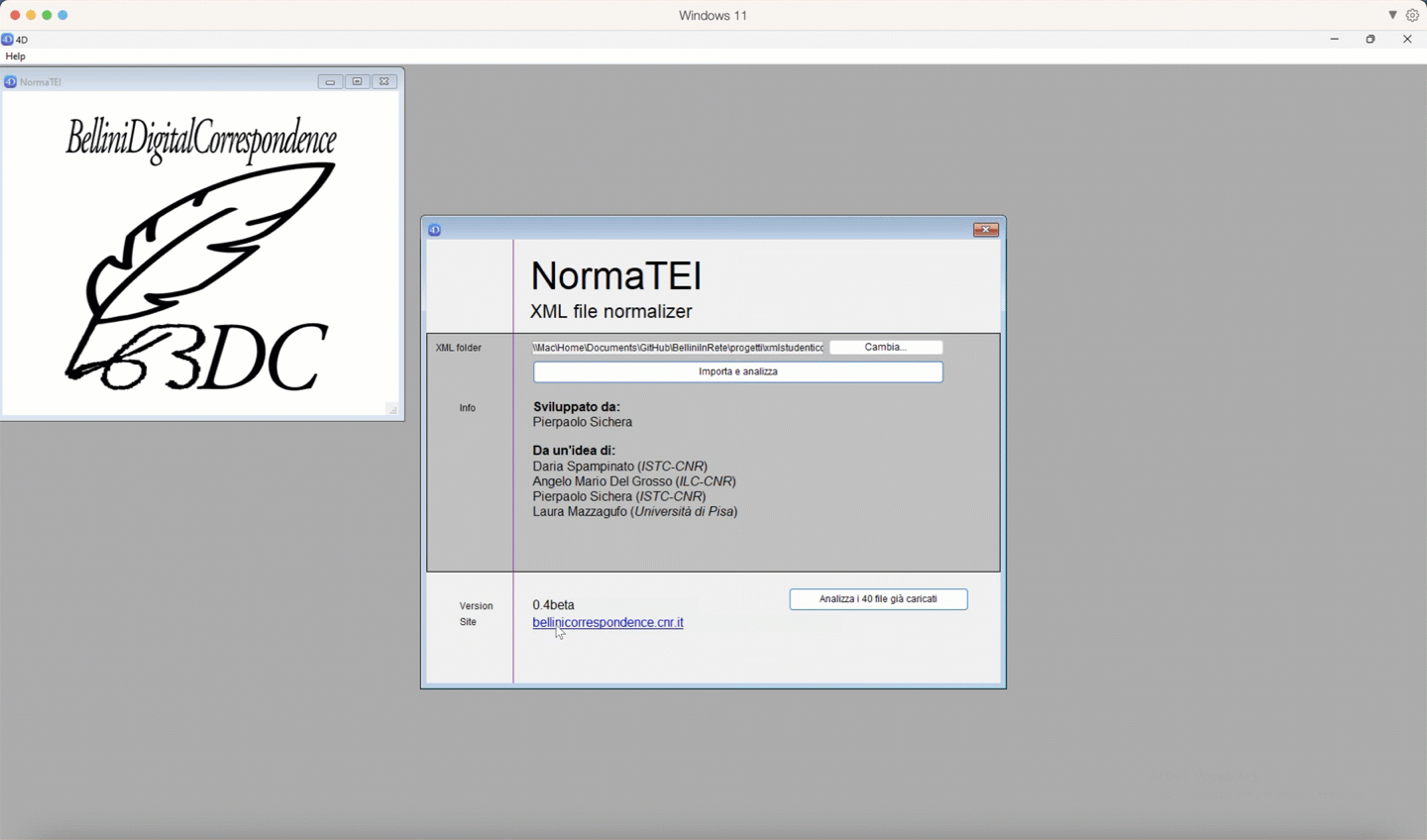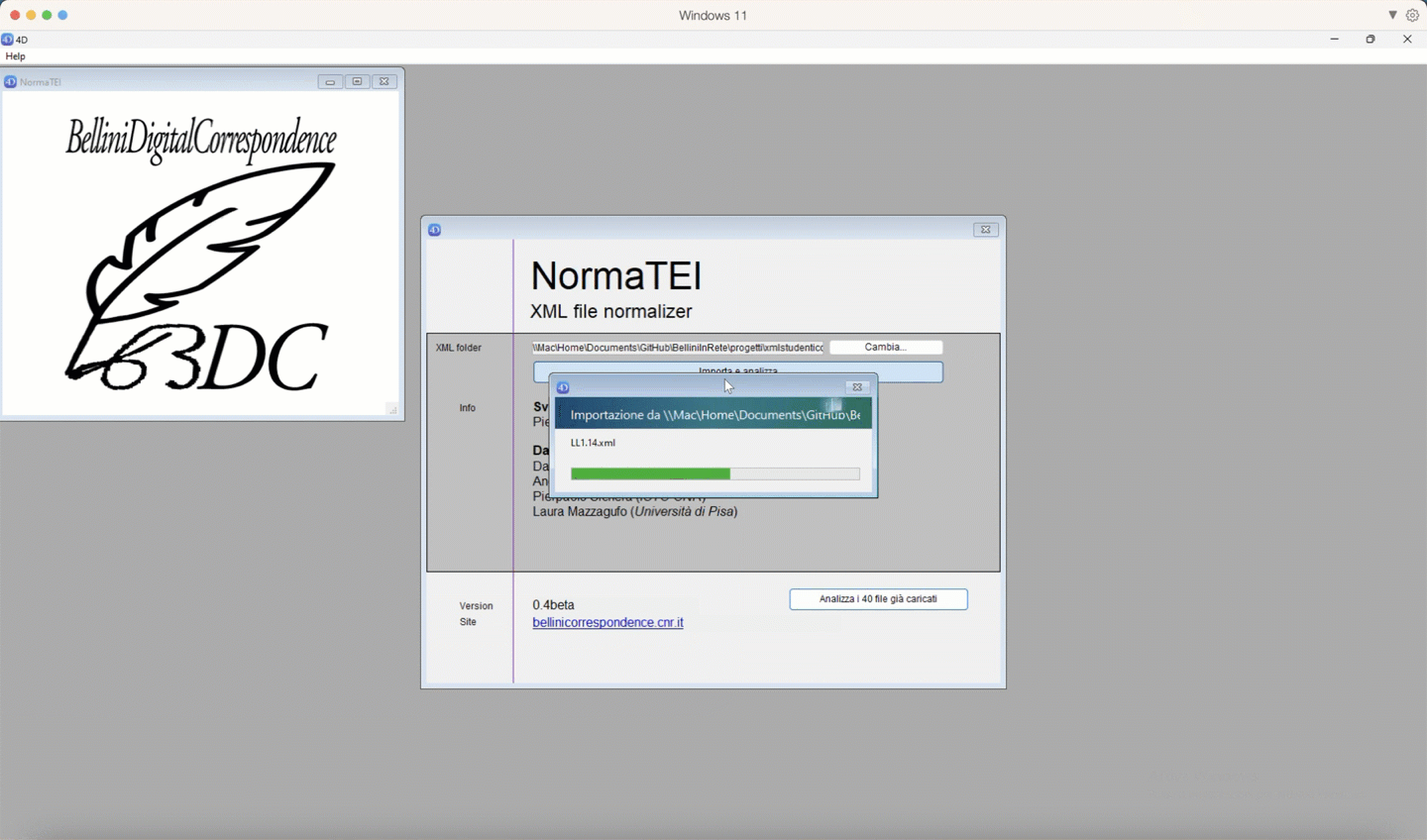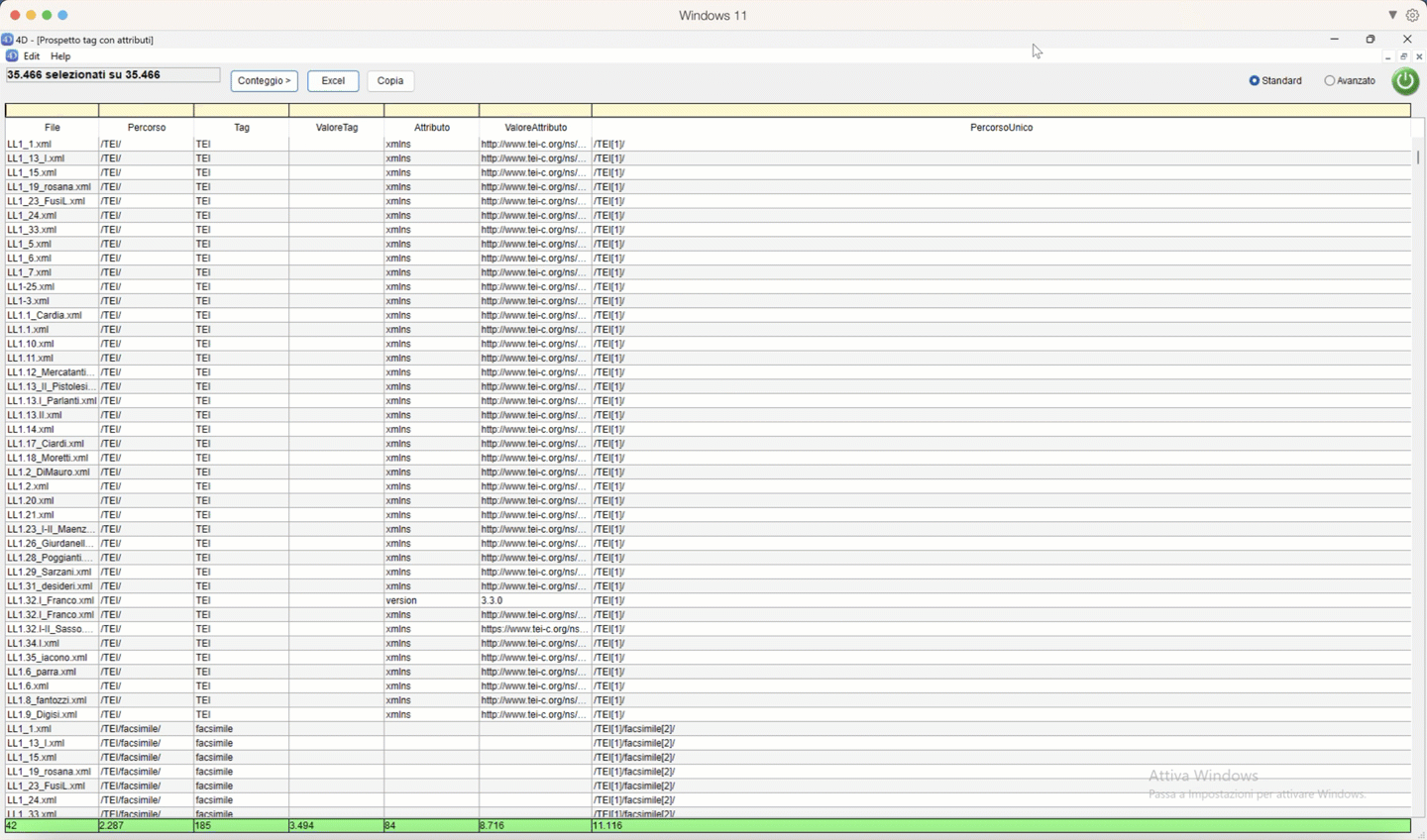
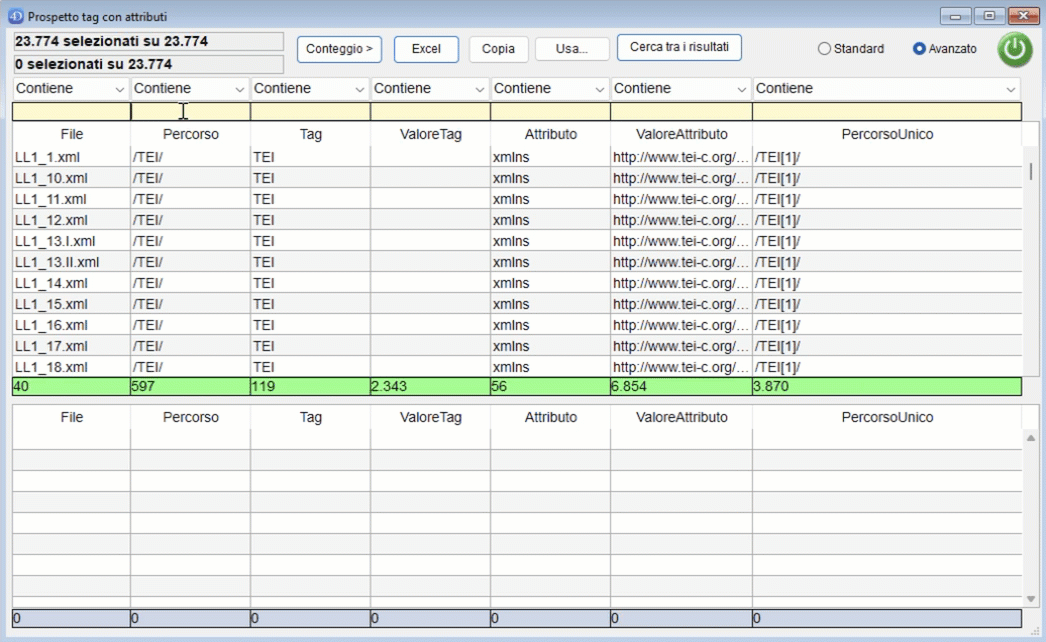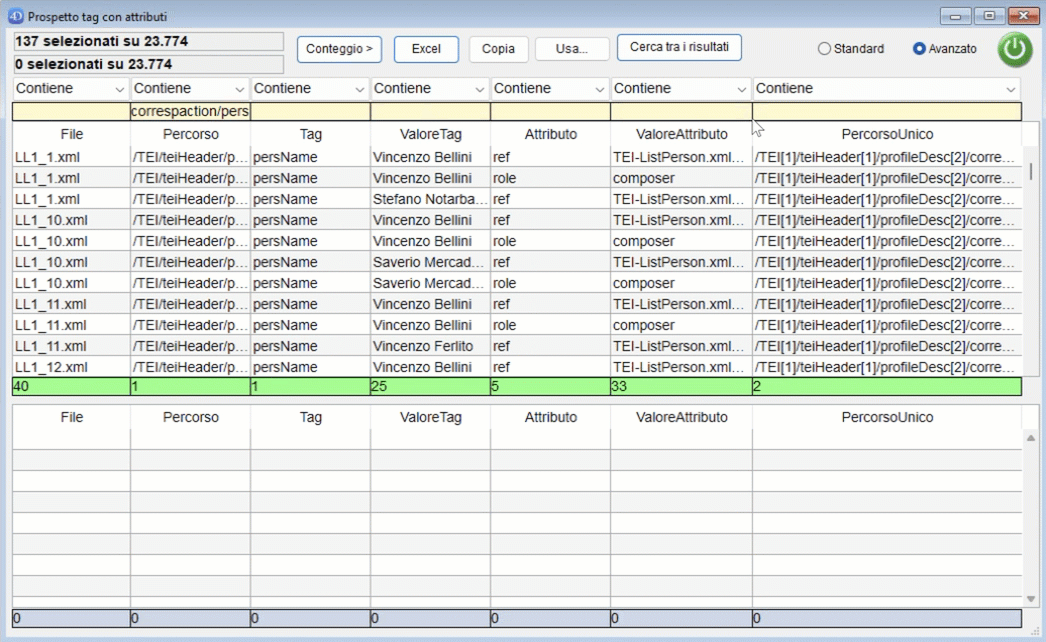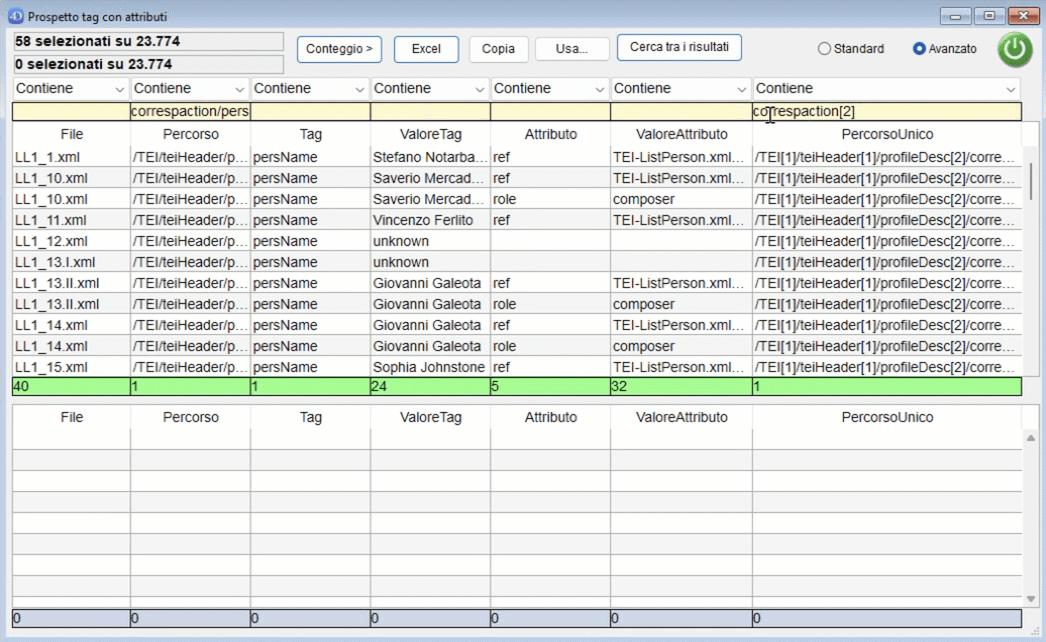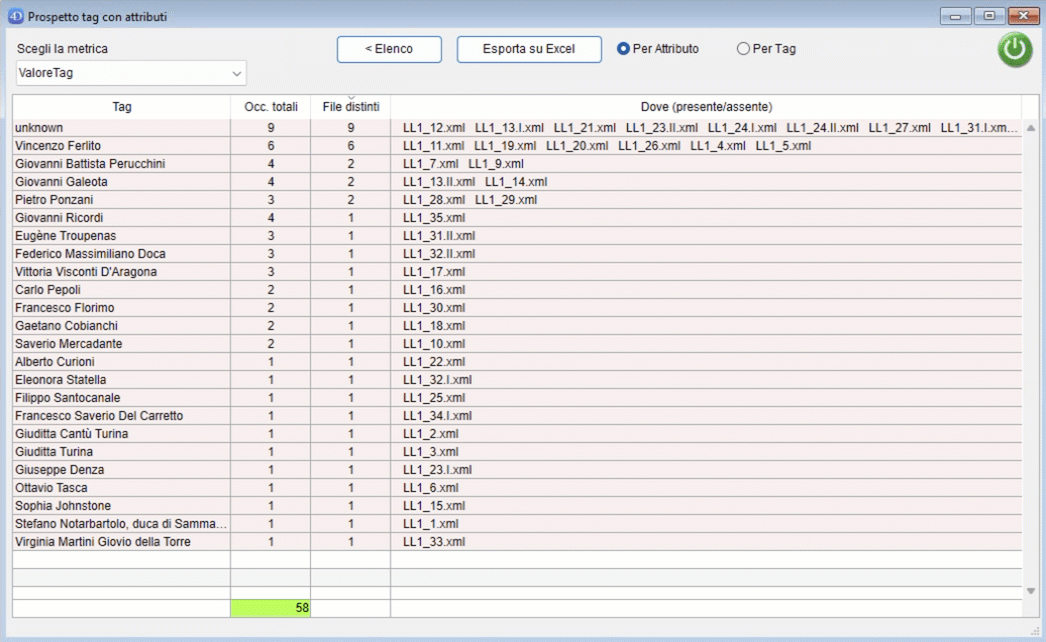
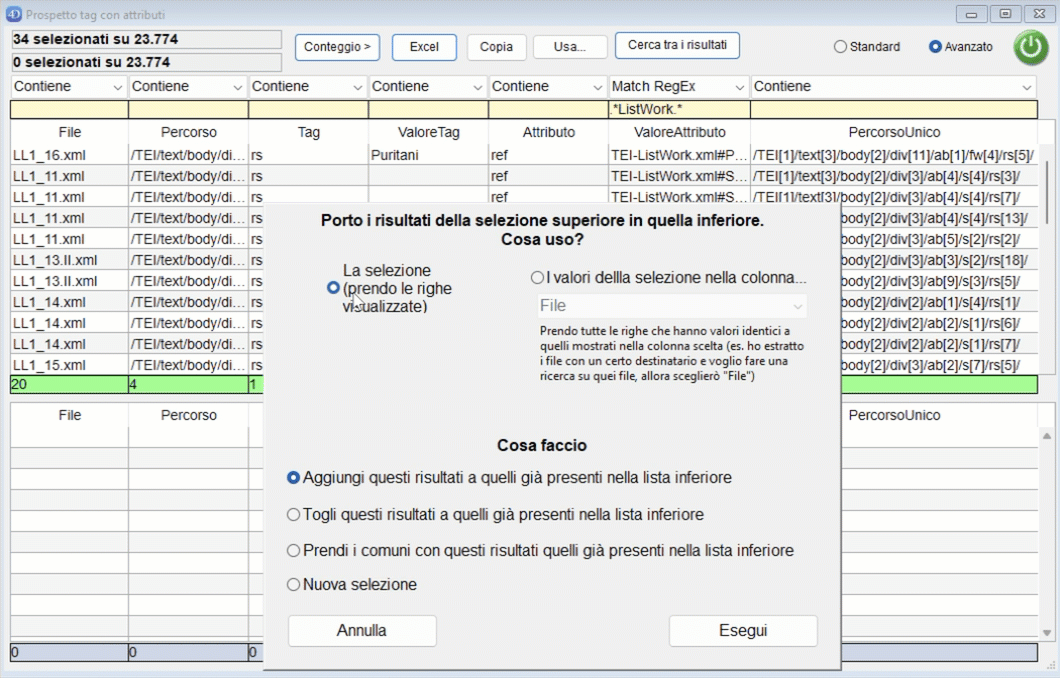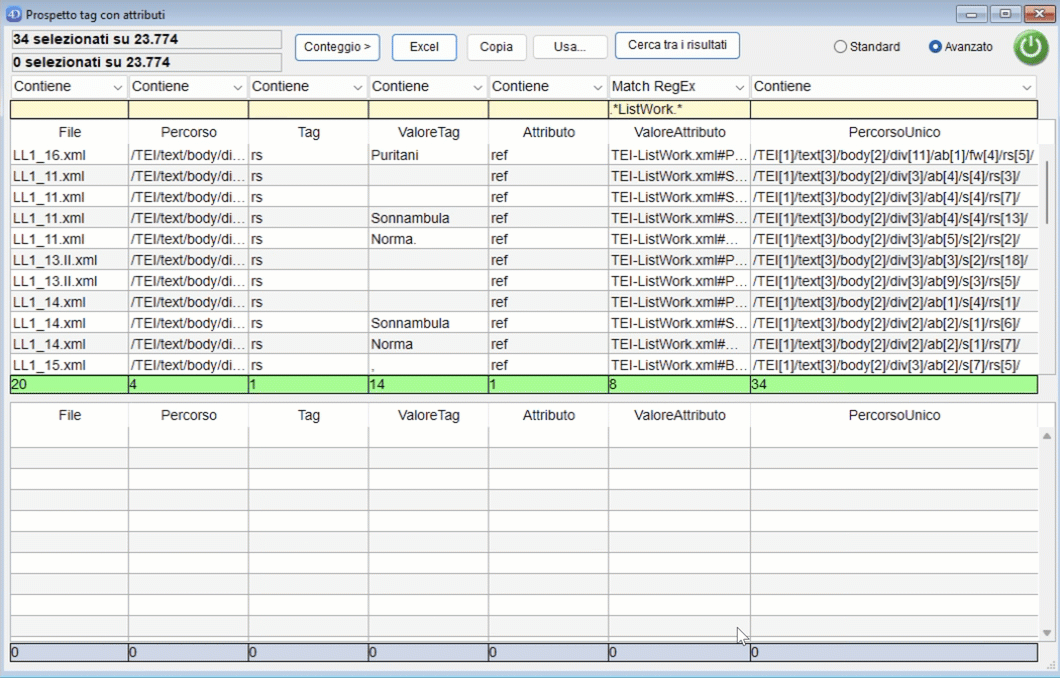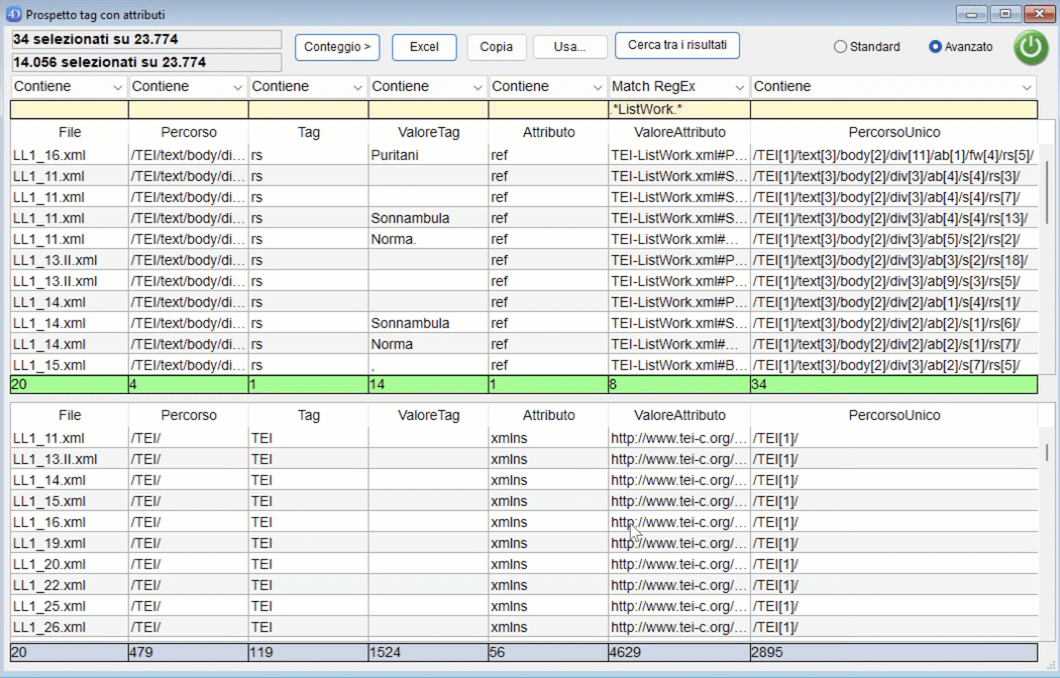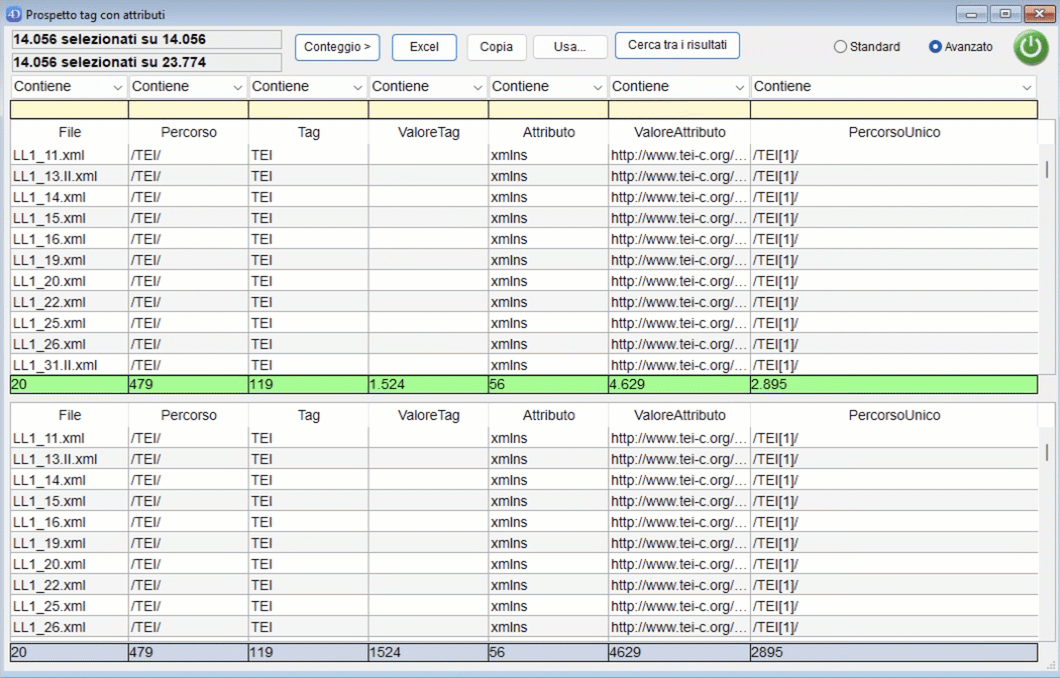
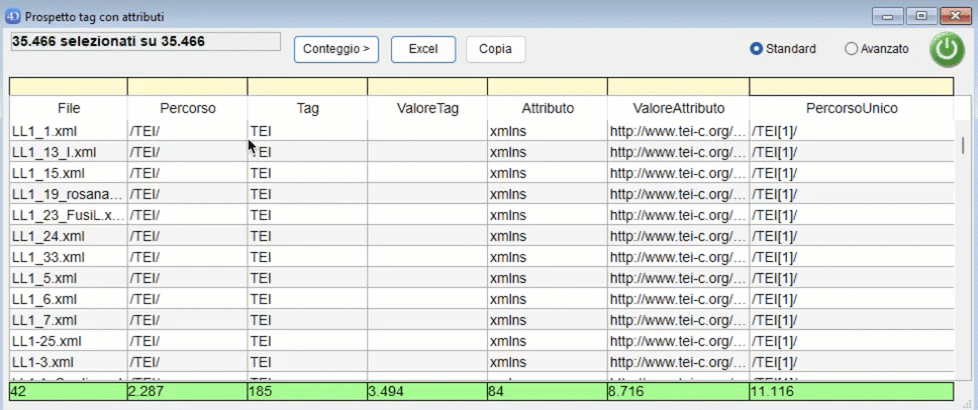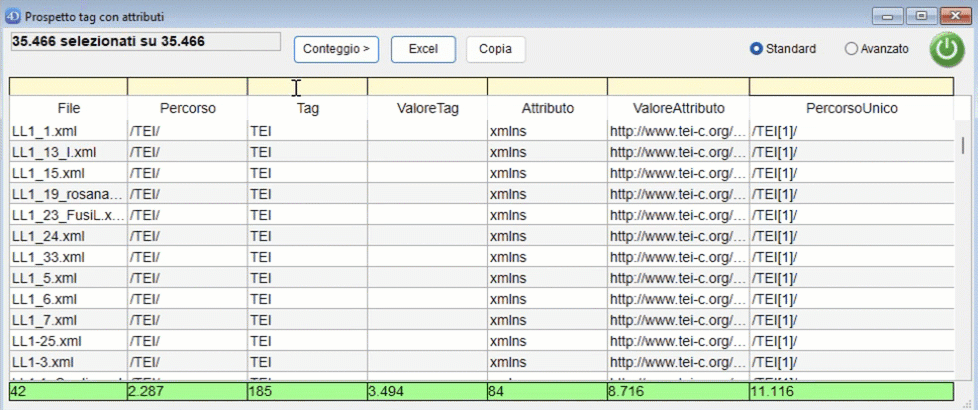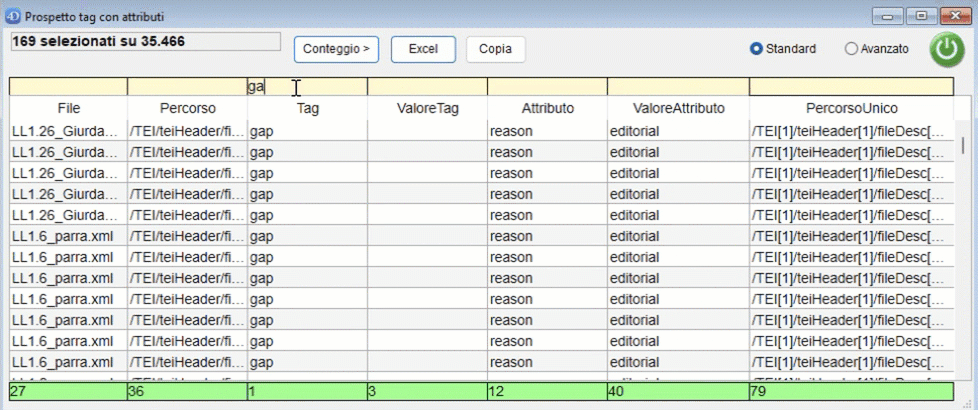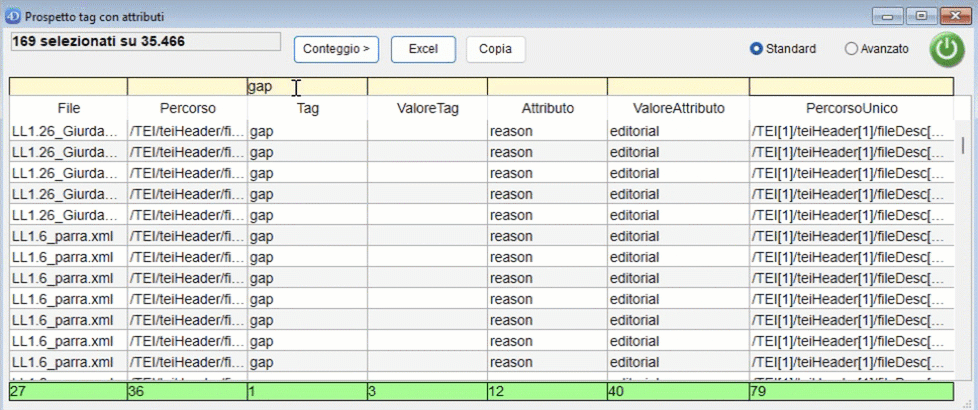 Al termine dell'operazione scelta, NormaTEI mostrerà i dati, generando una lista che elenca:
Al termine dell'operazione scelta, NormaTEI mostrerà i dati, generando una lista che elenca:
- il file dove è presente quel tag;
- il percorso completo;
- il tag;
- il valore di quel tag;
- gli attributi di quel tag;
- i valori degli attributi;
- il percorso univoco. Con "percorso univoco" si intende attribuire un identificativo univoco ad ogni percorso, aggiungendo ad ogni tag del percorso un codice numerico del tipo "[N]". Ad esempio "/TEI[1]/text[3]/body[2]/" indica che body è il secondo figlio del tag text che è il terzo figlio del tag TEI che è il primo figlio della root. In alto a sinistra viene mostrato il numero di risultati totale rispetto al corpus preso in esame. I risultati mostrano:
- una riga per ogni attributo di un tag: quindi se un tag ha tre attributi l'elenco mostra tre righe, una per ogni attributo;
- una riga con un valore nella colonna Tag e nessun valore nella colonna Attributo se il tag non ha attributi. È possibile effettuare delle ricerche inserendo per ogni colonna una parte del testo da cercare nei riquadri gialli in alto. Cliccando sul confine tra le intestazioni delle colonne è possibile ridimensionarle. Se un tag non ha attributi viene mostrata una riga che avrà i dati sugli attributi vuota. Se un tag ha un attributo viene mostrato col suo valore. Se un tag ha più attributi viene mostrata una riga per ogni attributo. In basso viene mostrato il numero di valori distinti per ogni colonna.
 Il pulsante "Conteggio" permette di passare ad una finestra riepilogativa rispetto ai dati visualizzati.
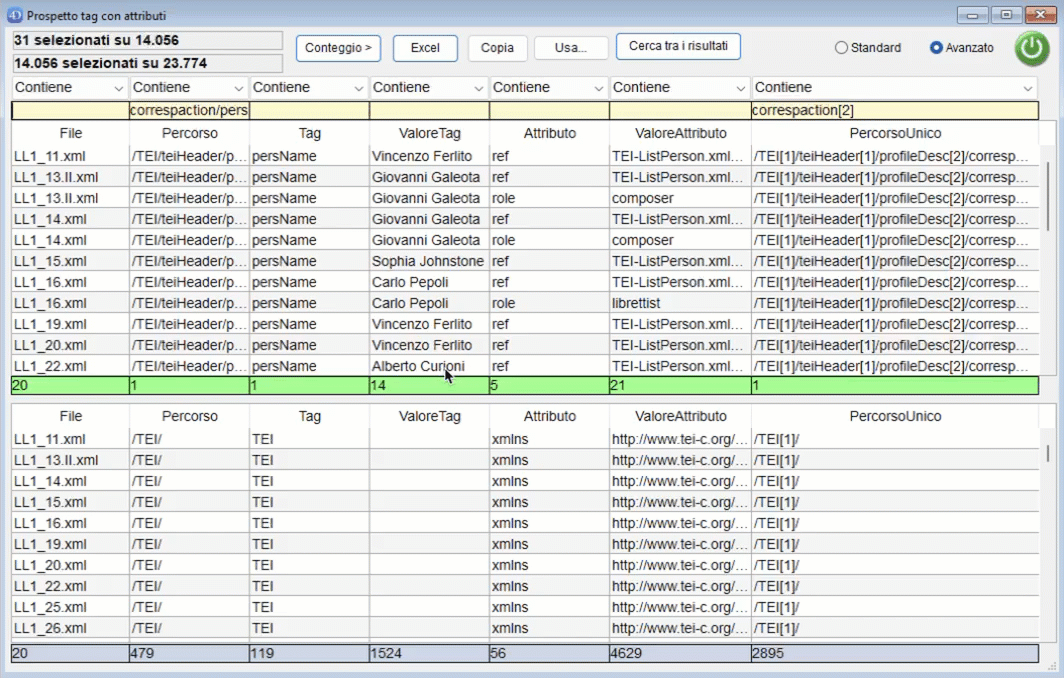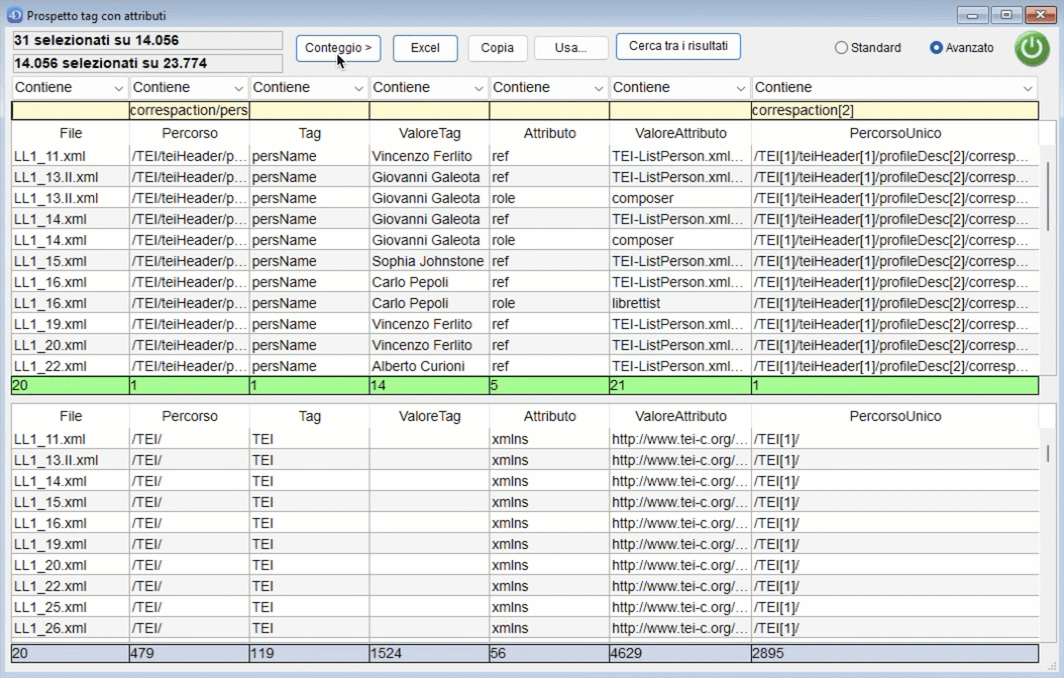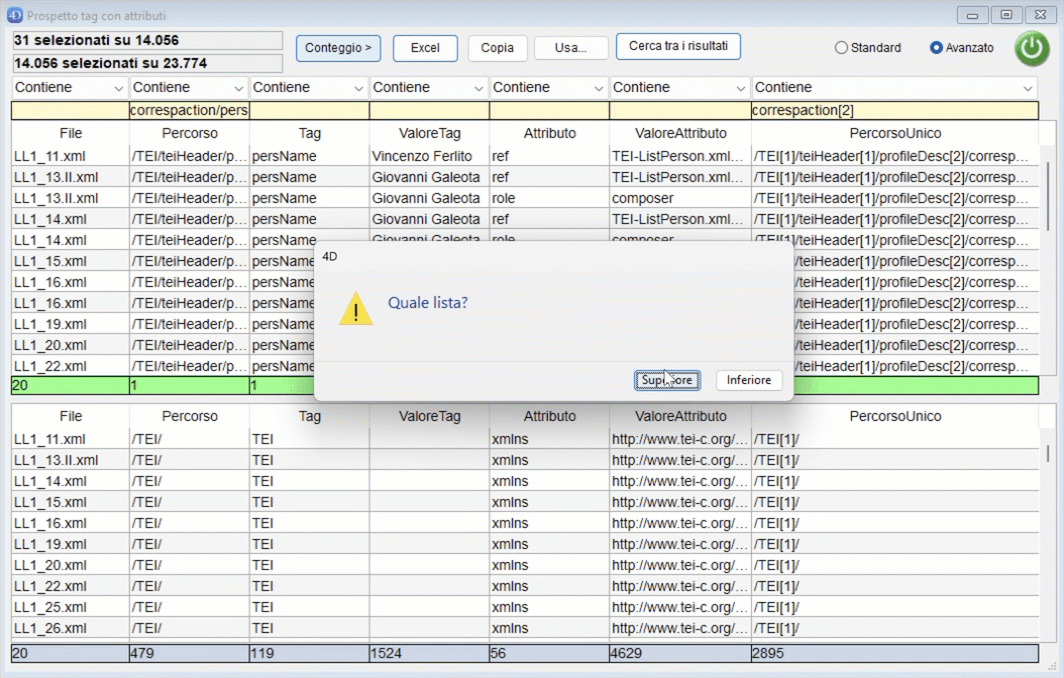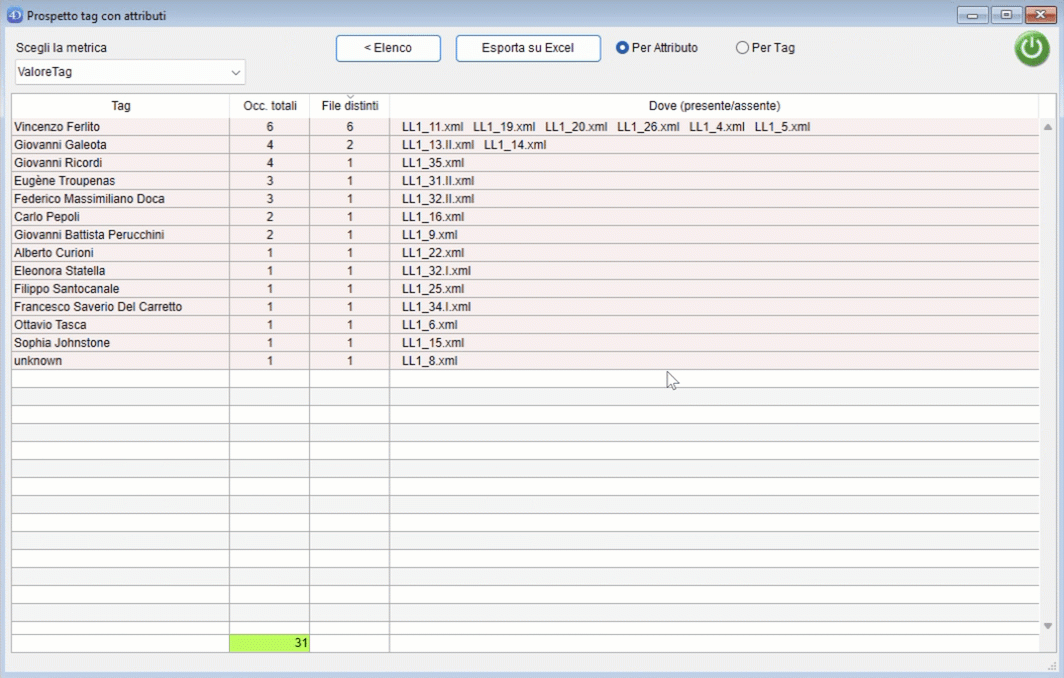
Vengono visualizzati:
Il pulsante "Conteggio" permette di passare ad una finestra riepilogativa rispetto ai dati visualizzati.
Vengono visualizzati:
- la metrica su cui viene eseguito il conteggio (le colonne della finestra di ricerca);
- il numero di occorrenze totali di quel fenomeno;
- in quanti file è presente quel fenomeno almeno una volta;
- i file in cui quel fenomeno è presente/assente (se la riga ha uno sfondo verde quelli mostrati sono i file del corpus dove quel fenomeno non è presente, se la riga ha sfondo rosso sono i file del corpus dove si trova quel fenomeno);
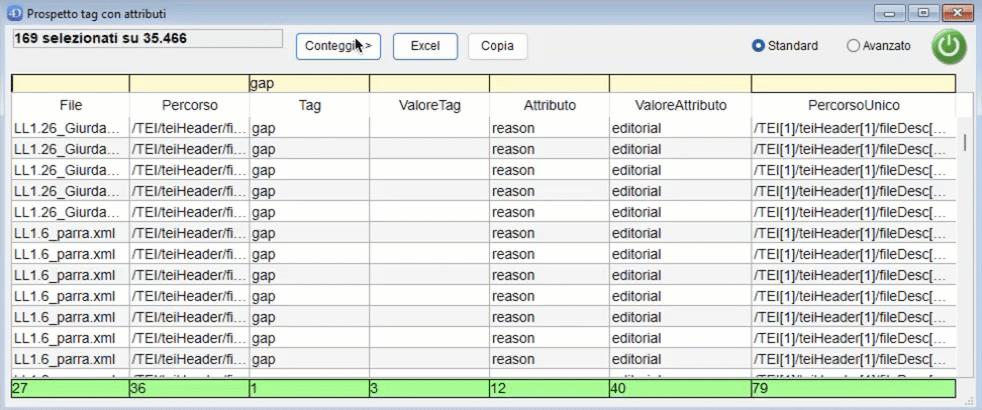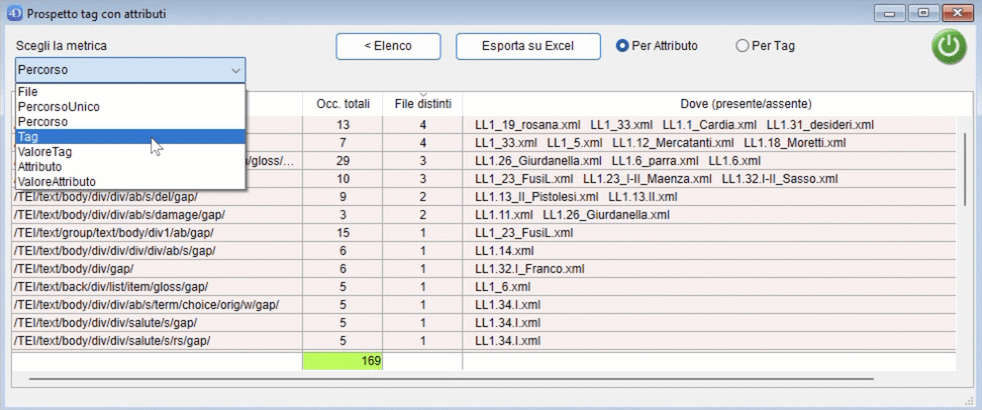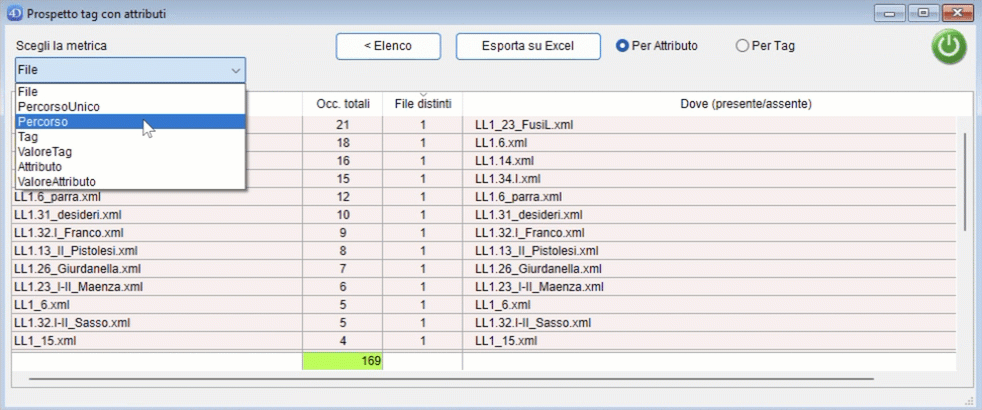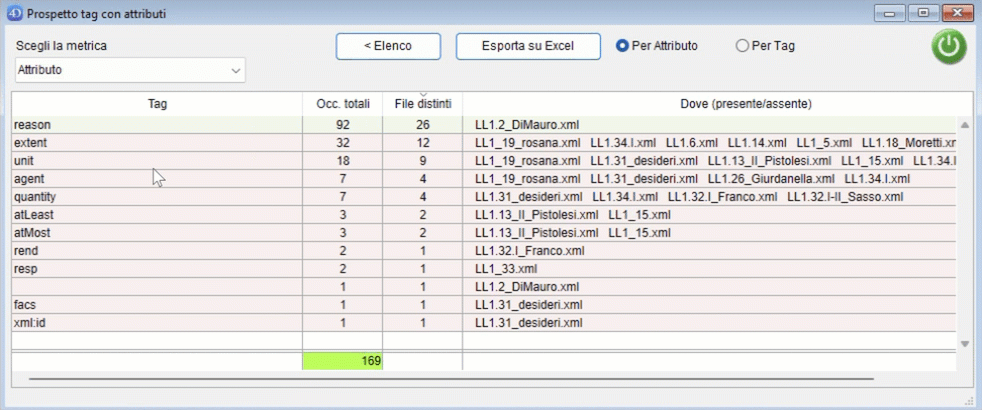
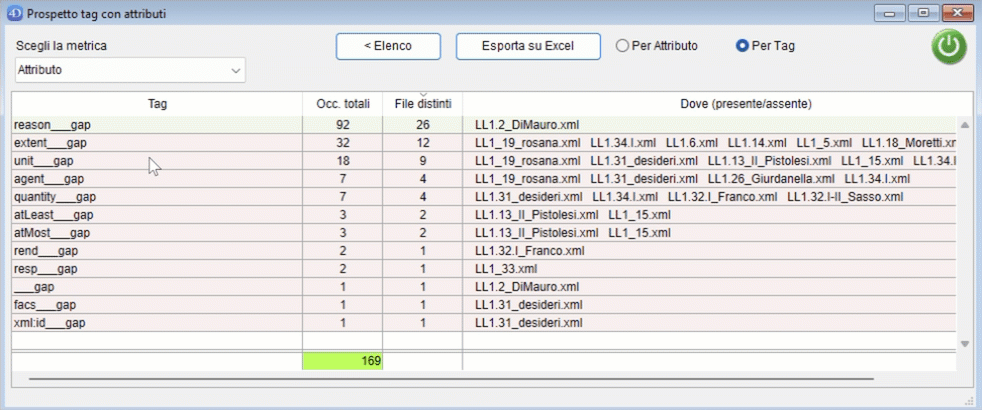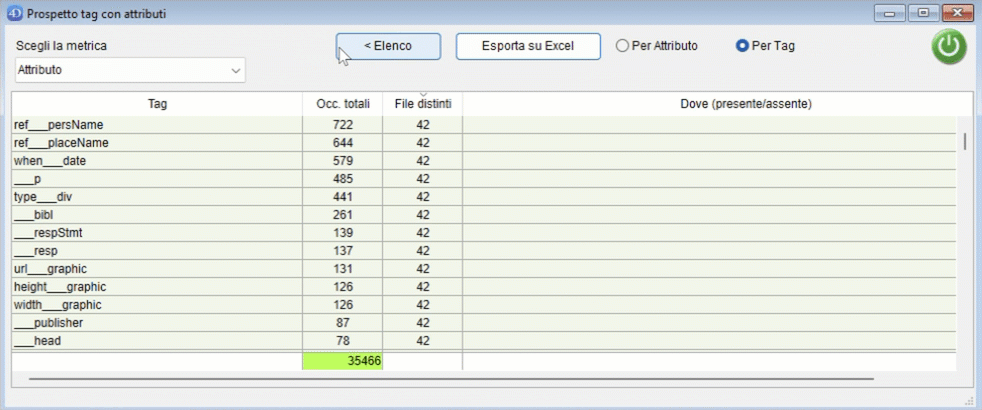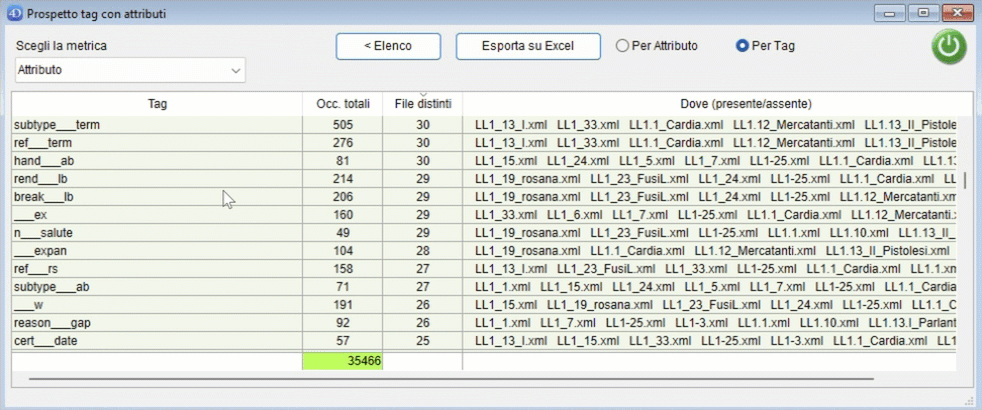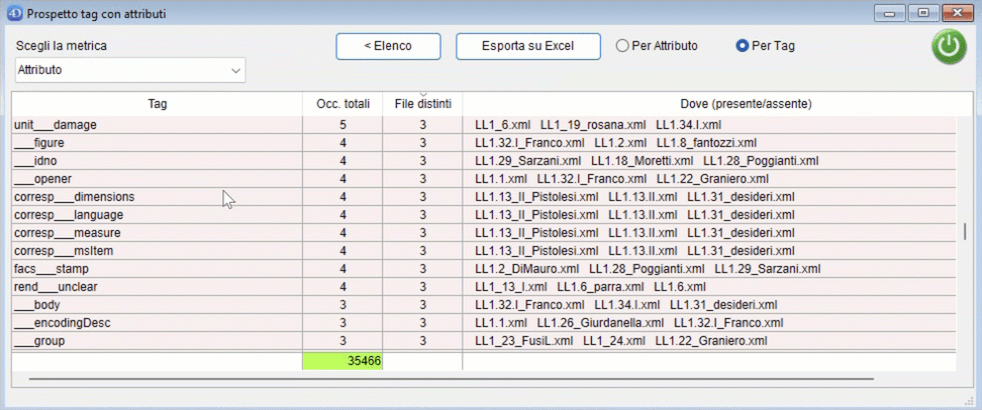 Il conteggio può essere effettuato per attributo o per tag. Esempio: per il tag
Il conteggio può essere effettuato per attributo o per tag. Esempio: per il tag
<ab n="ab_02" next="#LL1.10_ab_01_1v" part="I" rend="first_line_indented" type="parag" xml:id="LL1.10_ab_01_1r">effettuando il conteggio sulla metrica "Tag":
- se il conteggio viene effettuato per Attributo, il valore di ab è 5 (quanti sono gli attributi presenti in questo tag);
- se il conteggio viene effettuato per Tag, il valore di ab è 1 (perché ab è un singolo tag).
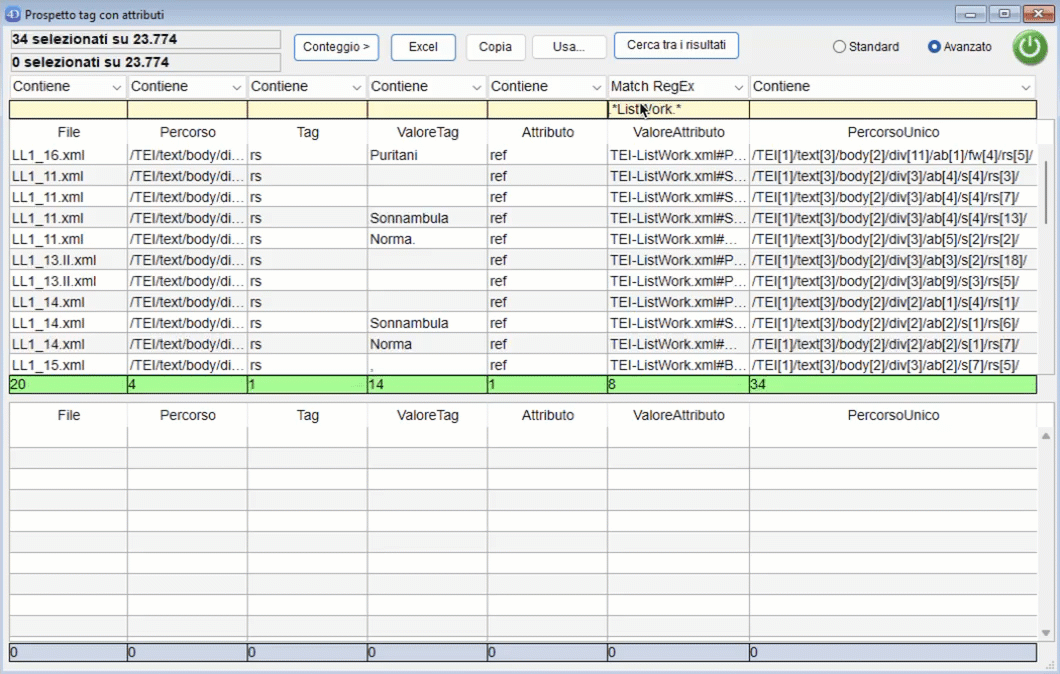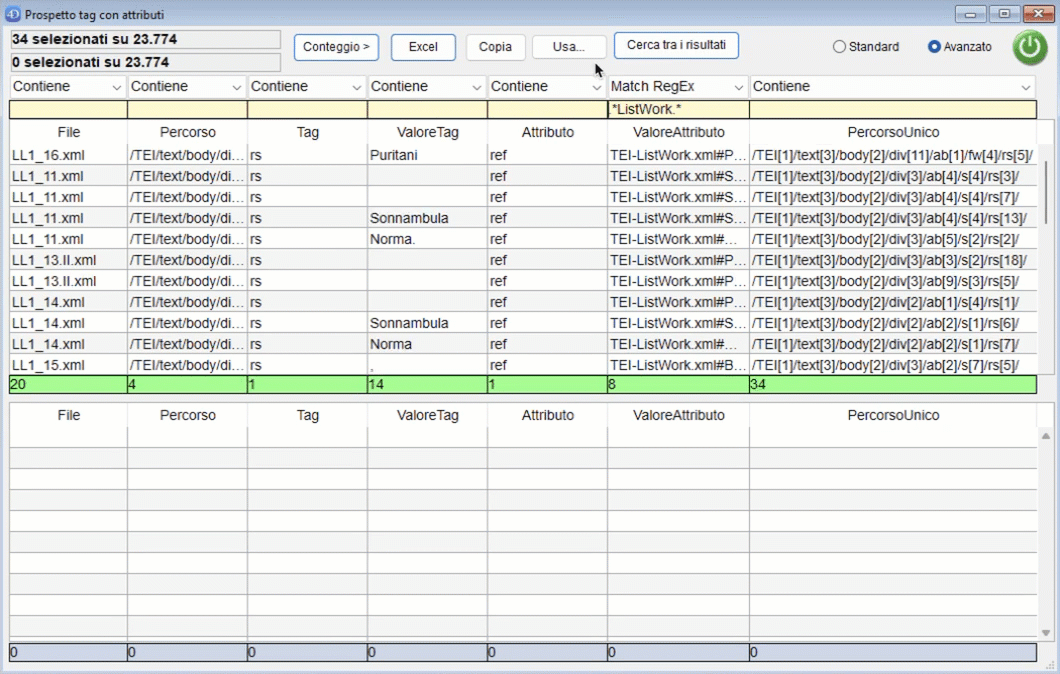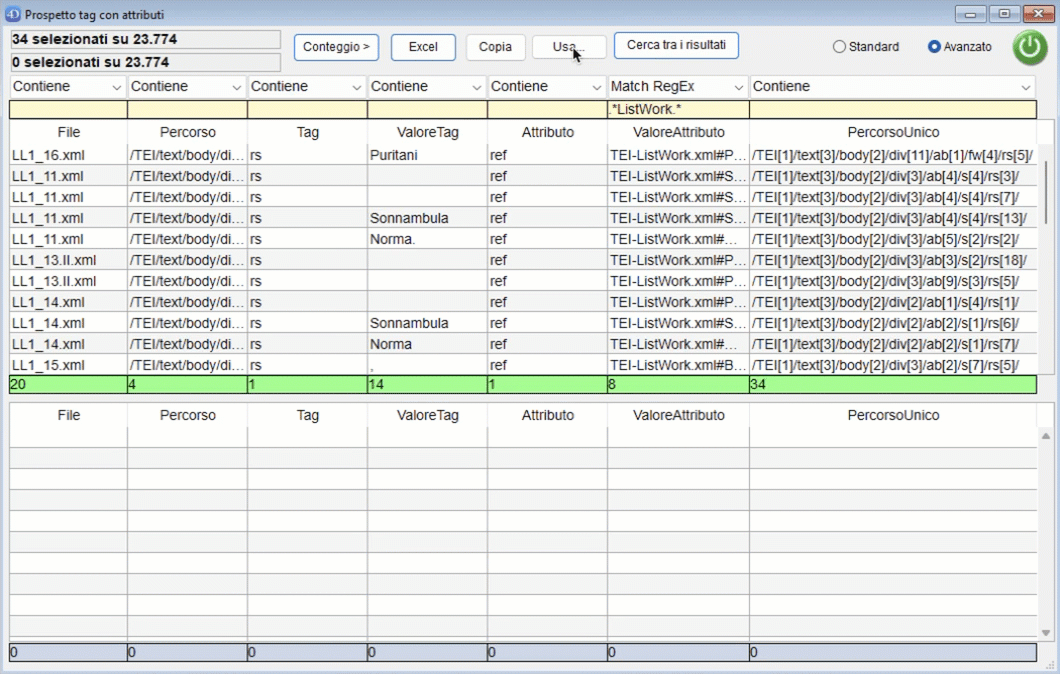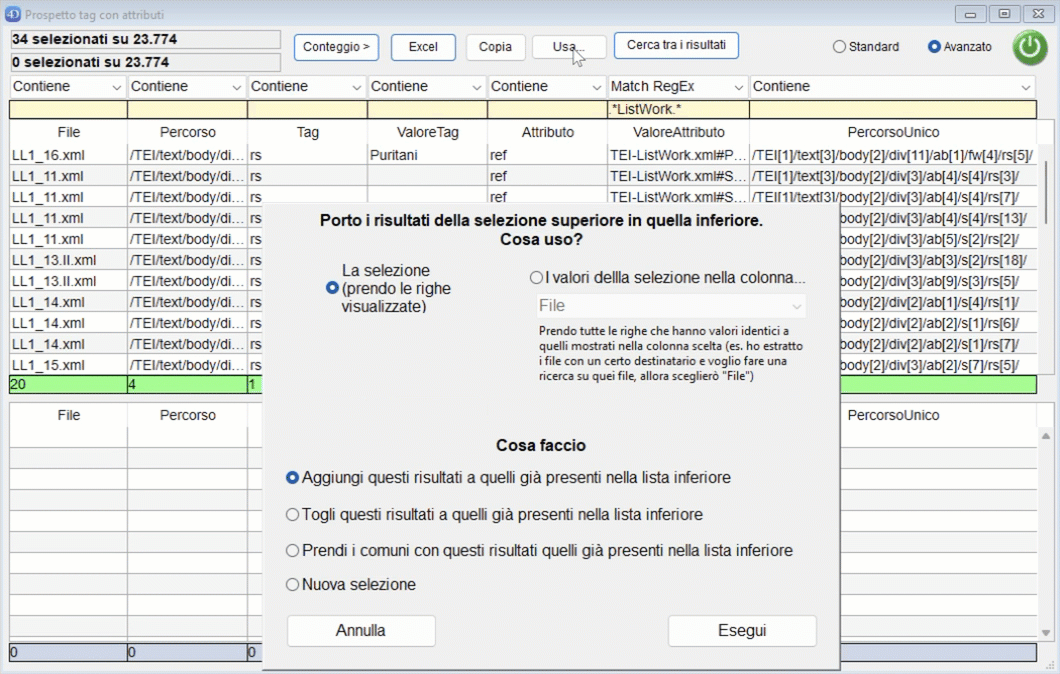
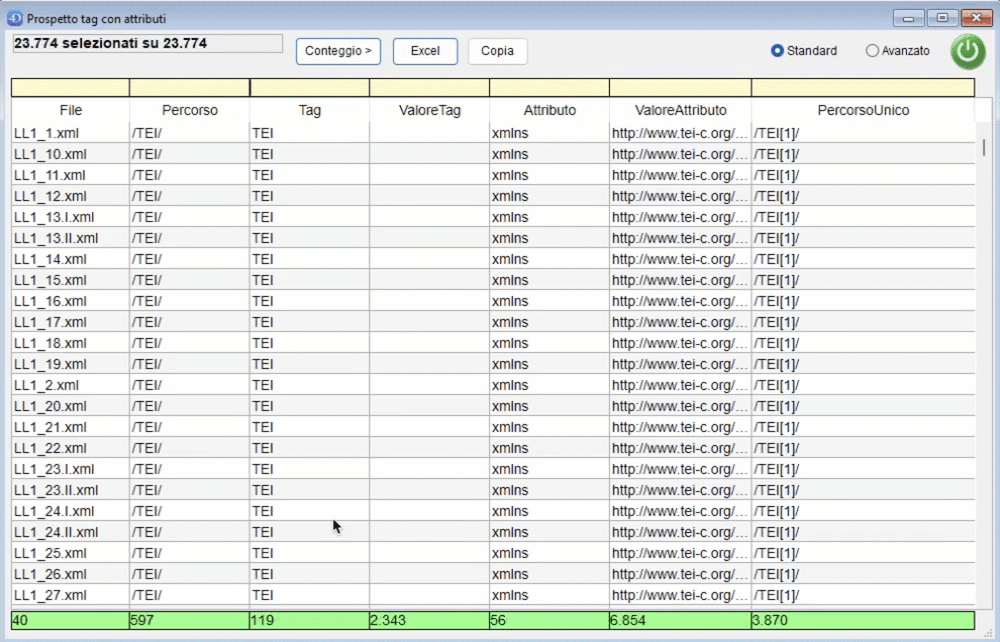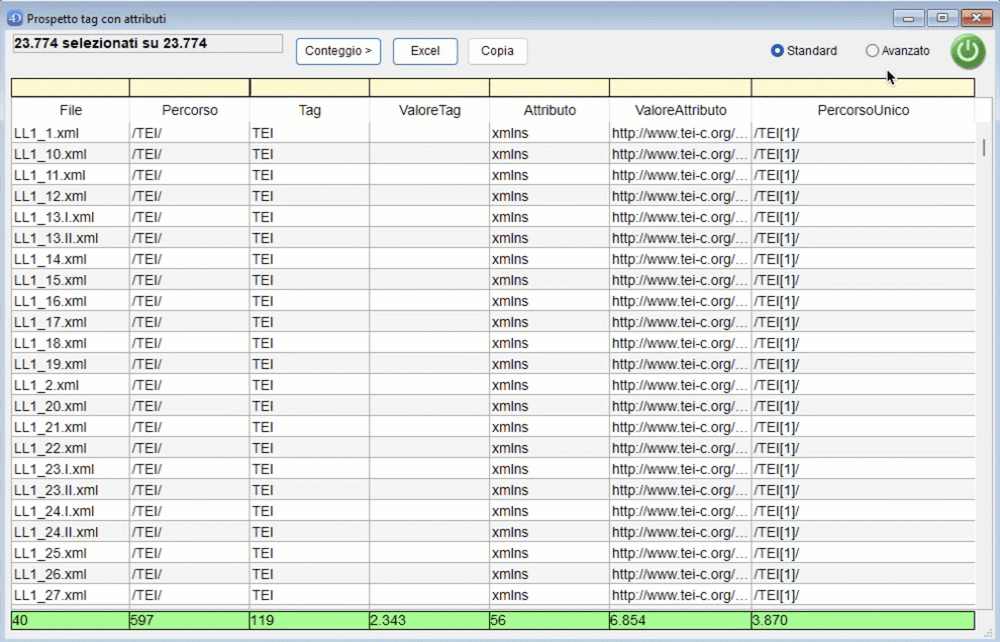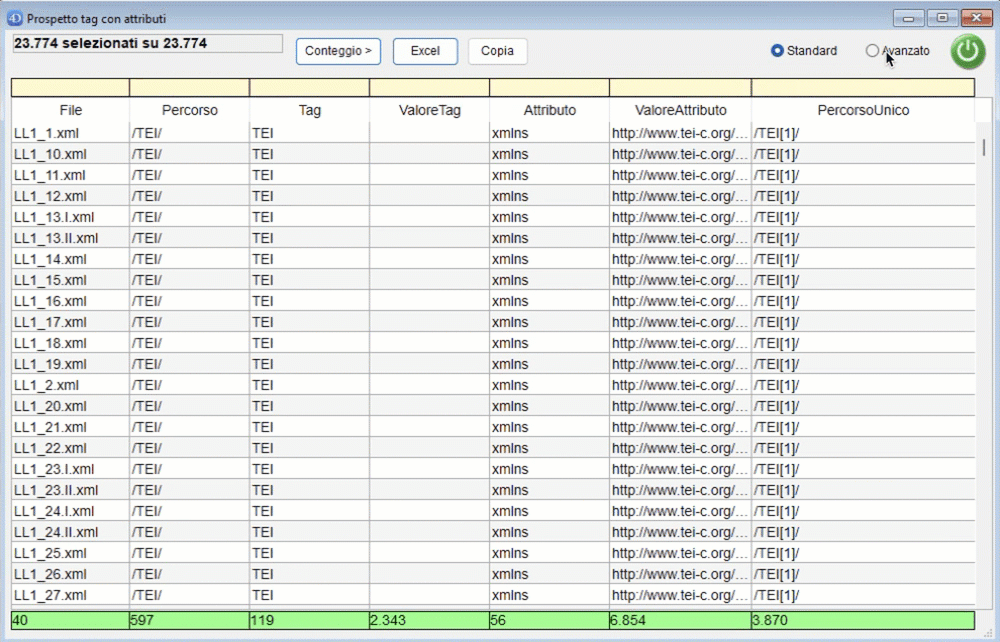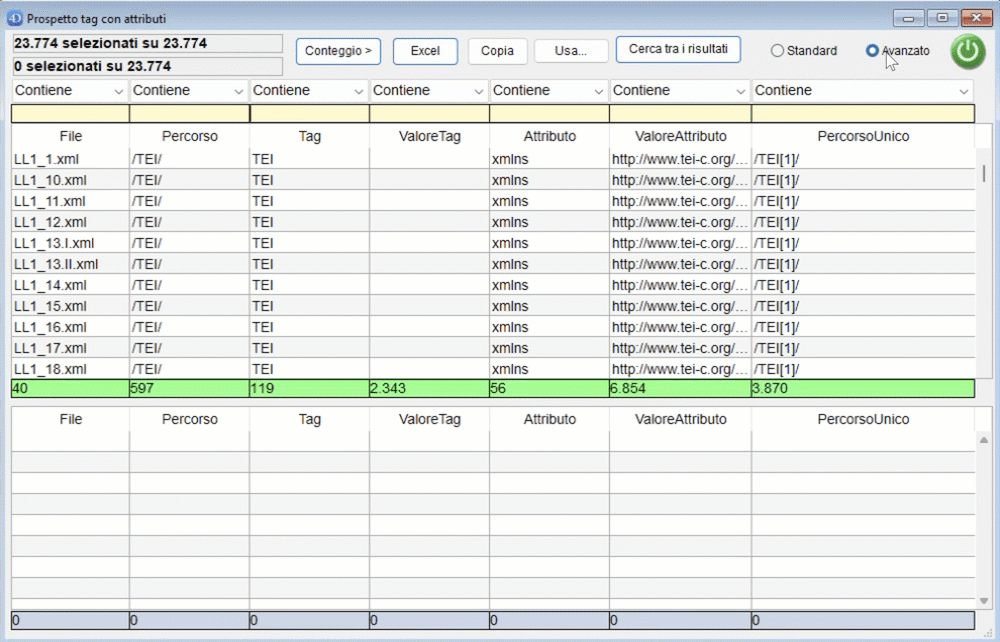 Cliccando in alto a destra su "Avanzato" è possibile attivare la finestra di ricerca avanzata.
Al di sopra della stringa di ricerca è possibile scegliere il criterio da applicare alla stringa di ricerca:
Cliccando in alto a destra su "Avanzato" è possibile attivare la finestra di ricerca avanzata.
Al di sopra della stringa di ricerca è possibile scegliere il criterio da applicare alla stringa di ricerca:
- Contiene: la stringa è contenuta nel campo (senza distinzione di maiuscole e minuscole);
- Inizia con: la stringa si trova nella parte iniziale del campo;
- Finisce con: la stringa si trova nella parte finale del campo;
- Esatto: il valore esatto della stringa;
- Non contiene: la stringa non è presente nel campo;
- Match RegEx: la stringa di ricerca viene valutata come espressione regolare.
 Anche qui è possibile attivare la funzione di conteggio per analizzare i risultati.
Anche qui è possibile attivare la funzione di conteggio per analizzare i risultati.
 Cliccando sul pulsante "Usa" è possibile copiare i risultati della ricerca nella parte bassa della finiestra per un uso successivo:
Cliccando sul pulsante "Usa" è possibile copiare i risultati della ricerca nella parte bassa della finiestra per un uso successivo:
-
Cosa uso:
- La selezione: utilizza le righe trovate
- I valori della colonna: prende tutti le righe del corpus che hanno quel valore in quella colonna. Il caso più classico è quello in cui ho cercato dove una certa caratteristica è presente mio corpus e vorrei fare delle ricerche successive solo su quei file: in questo caso sceglierò i valori nella colonna "File".
-
Cosa faccio:
- Aggiungi: i risultati vengono aggiunti ai risultati nella parte bassa della finestra;
- Togli: i risultati vengono tolti dai risultati nella parte bassa della finestra;
- Prendi i comuni: vengono selezionati i risultati comuni a quelli già presenti nella parte bassa della finestra;
- Nuova selezione: vengono utilizzati i risultati selezionati togliendo quelli eventualmente già presenti nella parte bassa della finestra.
 A questo punto è possibile effettuare una nuova ricerca sull'intero corpus oppure premendo "Cerca tra i risultati" può essere effettuata una ricerca tra i dati selezionati nella parte bassa della finestra.
È inoltre possibile effettuare un conteggio sulle righe visualizzate nella parte Superiore o Inferiore della finestra.
A questo punto è possibile effettuare una nuova ricerca sull'intero corpus oppure premendo "Cerca tra i risultati" può essere effettuata una ricerca tra i dati selezionati nella parte bassa della finestra.
È inoltre possibile effettuare un conteggio sulle righe visualizzate nella parte Superiore o Inferiore della finestra.
NormaTEI is software for analyzing the content of one or more XML files. NormaTEI is designed mainly for two uses:
- control of encoding uniformity: when an XML/TEI edition is made up of multiple files, NormaTEI allows you to control them in an organic way, allowing you to easily identify errors or different encoding choices;
- encoding analysis: personalized and complex searches on the selected corpus (one or more files).
The name "Norma" recalls both the operation for which the software was developed ("normalization") and Vincenzo Bellini's most famous work: NormaTEI was in fact developed during the creation of Bellini Digital Correspondence, © Cnr Edizioni, 2023 ISBN: 978-88-8080-562-5, electronic edition.
- Daria Spampinato (ISTC-CNR)
- Angelo Mario Del Grosso (ILC-CNR)
- Laura Mazzagufo (UNIPI)
- Pierpaolo Sichera (ILIESI-CNR)
- Salvatore Cristofaro (ILIESI-CNR)
NormaTEI was developed using 4D (https://www.4d.com/). Among the many features of this platform, native XML support has been exploited (thanks to the Apache Foundation's Xerces library) and access to the structure of an XML via the DOM (Document Object Model) standard. NormaTEI is compatible with Windows 10 – Windows 11 - from Windows Server 2012 R2 to Windows Server 2022 - from macOS Big Sur (11) to macOS Ventura (13) (the latest releases for each version).
To use NormaTEI:
- download the Windows folder (downloading the entire repository or downloading the single folder via download services or software);
- extract the compressed files to obtain a zip file that you can extract to the folder you prefer and then run the NormaTEI.exe file.
- go to "System Settings -> Privacy and Security" and check that the "Everywhere" option is enabled. If the "Everywhere" item is not present, you can enable it with this command given by Terminal:
sudo spctl --master-disable
- download the MacOSX folder (downloading the entire repository or downloading the single folder via download services or software);
- extract the compressed files to obtain a zip file that you can extract to the folder you prefer and then run the NormaTEI.app file;
- note (1): if you tried to open NormaTEI.app before going to "Privacy and security", the operating system may have returned an error, preventing the application from opening. In this case, delete the file and download and extract it again;
- note (2): to enable Gatekeeper again (if you have deactivated it) just give the same command by inserting the word enable:
sudo spctl --master-enable
NormaTEI offers two search modes:
- Standard: For simple searches, quickly find coding errors;
- Advanced: for in-depth analysis and evaluation of corpuses.
At the first start a window for creating the data file may appear.
Choose "Create" and save it wherever you want, NormaTEI will remember the path used.
In the launch window click on "Change..." to choose the folder containing the XML files, then press the "Import and analyze" button.
If you have already imported files, you can view the results without performing a new import with the "Open already uploaded files" button below.
You can open multiple import and analysis windows at the same time by going to the main program window and choosing the "Start NormaTEI" menu item.
At the end of the chosen operation, NormaTEI will show the data, generating a list that lists:
- the file where that tag is present;
- the complete route;
- the tag;
- the value of that tag;
- the attributes of that tag;
- the values of the attributes;
- the unique path. By "unique path" we mean attributing a unique identifier to each path, adding a numeric code of the type "[N]" to each path tag. For example "/TEI[1]/text[3]/body[2]/" indicates that body is the second child of the text tag which is the third child of the TEI tag which is the first child of the root. The total number of results compared to the corpus examined is shown at the top left. The results show:
- one line for each attribute of a tag: therefore if a tag has three attributes the list shows three lines, one for each attribute;
- a row with a value in the Tag column and no value in the Attribute column if the tag has no attributes. It is possible to carry out searches by entering for each column a part of the text to be searched for in the yellow boxes at the top. By clicking on the border between the column headers you can resize them. If a tag has no attributes, a row with empty attribute data is shown. If a tag has an attribute it is shown with its value. If a tag has multiple attributes, one row is shown for each attribute. The number of distinct values for each column is shown at the bottom.
The "Count" button allows you to go to a summary window with respect to the data displayed.
The following are displayed:
- the metric on which the counting is performed (the columns of the search window);
- the total number of occurrences of that phenomenon;
- in how many files is that phenomenon present at least once;
- the files in which that phenomenon is present/absent (if the line has a green background those shown are the corpus files where that phenomenon is not present, if the line has a red background they are the corpus files where that phenomenon is found) ;
Counting can be done by attribute or tag. Example: for the tag
<ab n="ab_02" next="#LL1.10_ab_01_1v" part="I" rend="first_line_indented" type="parag" xml:id="LL1.10_ab_01_1r">counting on the "Tag" metric:
- if the counting is carried out by Attribute, the value of ab is 5 (how many attributes are present in this tag);
- if the counting is done by Tag, the value of ab is 1 (because ab is a single tag).
By clicking on "Advanced" at the top right you can activate the advanced search window.
Above the search string you can choose the criterion to apply to the search string:
- Contains: the string is contained in the field (case insensitive);
- Starts with: the string is found in the initial part of the field;
- Ends with: the string is found in the final part of the field;
- Equals: the exact value of the string;
- Doesn't contain: the string isn't present in the field;
- Match RegEx: the search string is evaluated as a regular expression.
Here too it is possible to activate the counting function to analyze the results.
By clicking on the "Use" button you can copy the search results in the lower part of the window for later use:
-
What I use:
- The selection: uses the rows found
- Column values: takes all the rows of the corpus that have that value in that column. The most classic case is the one in which I have searched for where a certain characteristic is present in my corpus and I would like to carry out subsequent searches only on those files: in this case I will choose the values in the "File" column.
-
What I do:
- Add: the results are added to the results in the lower part of the window;
- Remove: the results are removed from the results in the lower part of the window;
- Get common: results common to those already present in the lower part of the window are selected;
- New selection: the selected results are used, removing any already present in the lower part of the window.
At this point it is possible to carry out a new search on the entire corpus or by pressing "Search among results" a search can be carried out among the data selected in the lower part of the window.
You can also count the lines displayed at the Top or Bottom of the window.