This is the implementation for the paper Fine-Tuning Language Models with Just Forward Passes. In this paper we propose a memory-efficient zeroth-order optimizer (MeZO), adapting the classical zeroth-order SGD method to operate in-place, thereby fine-tuning language models (LMs) with the same memory footprint as inference.
With a single A100 80GB GPU, MeZO can train a 30-billion parameter OPT model, whereas fine-tuning with Adam can train only a 2.7B LM. MeZO demonstrates comparable performance to fine-tuning with backpropagation across multiple tasks, with up to 12× memory reduction. MeZO is also compatible with both full-parameter and parameter-efficient tuning techniques such as LoRA and prefix tuning. We also show that MeZO can effectively optimize non-differentiable objectives (e.g., maximizing accuracy or F1).
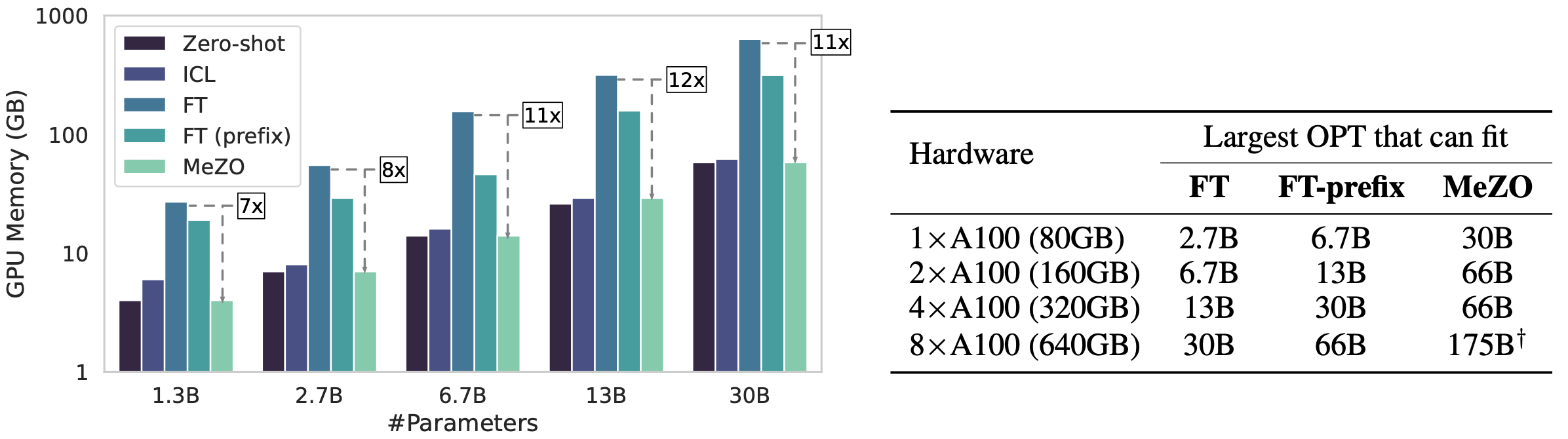 GPU memory usage comparison between zero-shot, in-context learning (ICL), Adam fine-tuning (FT), and our proposed MeZO.
GPU memory usage comparison between zero-shot, in-context learning (ICL), Adam fine-tuning (FT), and our proposed MeZO.
 OPT-13B results with zero-shot, in-context learning (ICL), MeZO (we report the best among MeZO/MeZO (LoRA)/MeZO (prefix)), and fine-tuning with Adam (FT). MeZO demonstrates superior results over zero-shot and ICL and performs on par with FT (within 1%) on 7 out of 11 tasks, despite using only 1/12 memory.
OPT-13B results with zero-shot, in-context learning (ICL), MeZO (we report the best among MeZO/MeZO (LoRA)/MeZO (prefix)), and fine-tuning with Adam (FT). MeZO demonstrates superior results over zero-shot and ICL and performs on par with FT (within 1%) on 7 out of 11 tasks, despite using only 1/12 memory.
For reproducing RoBERTa-large experiments, please refer to the medium_models folder. For autoregressive LM (OPT) experiments, please refer to the large_models folder. If you want to learn more about how MeZO works and how we implement it, we recommend you to read the large_models folder as the implementation is clearer and more extensible. If you want to explore more variants of MeZO, we recommend trying out medium_models as it's faster and has more variants implemented.
Our implementation of MeZO is based on HuggingFace's Trainer. We add MeZO to the official implementation of trainer with minimum editing. Please refer to "How to add MeZO to my own code?" section in large_models README for more details.
If you have any questions related to the code or the paper, feel free to email Sadhika (smalladi@princeton.edu) or Tianyu (tianyug@princeton.edu). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
@article{malladi2023mezo,
title={Fine-Tuning Large Language Models with Just Forward Passes},
author={Malladi, Sadhika and Gao, Tianyu and Nichani, Eshaan and Damian, Alex and Lee, Jason D and Chen, Danqi and Arora, Sanjeev},
year={2023}
}