React Native comes with AsyncStorage, a key-value storage that has very minimalistic API and a simple idea behind it. It just stores strings for you in either plain files on iOS or SQLite on Android under the hood (secretly, it can also use RocksDB). In order to store something more complex than just a string you have to take care of things like serialization. Which raises a question: Maybe I need a "real" database in my React Native project?
From my perspective, in 90% cases using DB is more about your app's architecture than data itself.
RealmDB is a good example of such fully featured database. It has a query engine, scheme descriptions, migrations and Realm allows operating with quite a big amount of data efficiently: https://realm.io/blog/introducing-realm-react-native/#benchmarks. Note how they compare it with react-native-store -- an additional layer for AsyncStorage to emulate the similar Realm-like interface.
No doubt, Realm is significantly faster when it comes to large databases and complicated queries. But it comes with cost. Realm is a native library that adds a good bunch of megabytes to your binary files and introduces new methods for your Android project (and it could be the problem because of DEX issue). And, like any serious database, Realm also requires to maintain scheme, which is not very expressive.
In vanilla iOS development you most likely may need something like CoreData, but if you came from React world you might want to stick to the well-known paradigms, and having a single global state is one of them.
Choosing Redux means you persist your state to disk, using something like redux-persist or redux-storage. It's easy to do if your app is small and all you need to care about is some user settings. In reality, you have a listview, maybe a few of them, different kinds of collection representations such as maps, tables or tinder-like cards. You need to sort items in these collections, filter them, or operate with parts of it in different ways.
So to understand a perspective and limitations, let's have a look at serialization and deserialization costs of using JSON.stringify/JSON.parse and AsyncStorage:
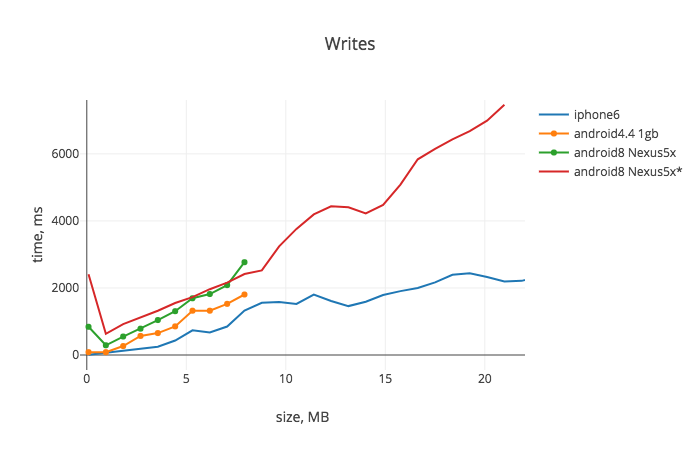
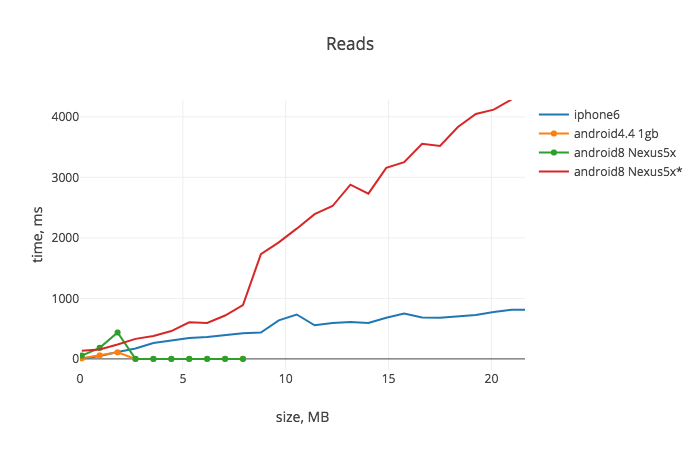
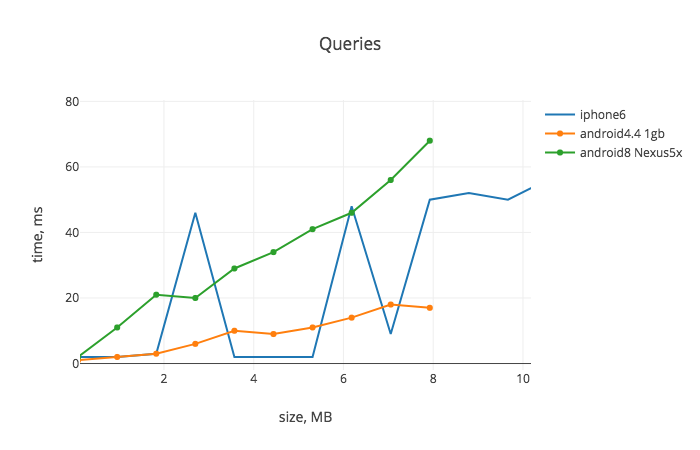
See App.js for details. This can't be called a proper benchmark for various reasons, but reflects real world experience that I’ve had. You can see that the performance is more than enough for iOS, but out-of-the-box Android devices can't process a single AsyncStorage operation after it gets over ~2.5MB*. And anyway you probably don't want to wait more than 1-2 seconds for the first launch data load.
- Persist minimal amount of data.
redux-storageandredux-persistboth have great filter decorators that allows you to blacklist certain keys which are not necessary to persist between relaunches. - Split initial global state loading into chunks, load only most important data that needs to be shown to user for the first screen and delay others parts. Consider this combined reducer state:
{
user: User,
settings: Settings,
photos: Array<Photo>,
favs: Array<Photo>,
mentions: Array<Mention>,
messages: Array<Chats>
}Hypothetically, all you need here to show the first screen is user, settings and first 10 items in photos keys. All of this can be stored as a separate AsyncStorage entity (AsyncStorage.getItem('BASE_DATA')). The others, heavier parts of the state loads later as different processes and lands in the same Redux state.
The basic rule here is "Do not store the whole lists".
- Delay loading. The same tip as before, but applied to array in this case. If you have a collection with 1000 items, just load only first N first, and others later.
- Lazy loading. An improved idea of the previous point. Use
onEndReachedfromFlatList(VirtualizedList) to load more items into collection. - Do not forget to trim the list before persisting state to disk to keep core snapshot small, or use advanced techniques.
- To load larger collections on Android (for temporary usage, such as search) more than 2MB in a batch, you may want to look at wrapper to see the idea of splitting array into chunks before saving.
This is the hardest part, if you need queries extensively then using optimized DB with indexes could be the only choice.
Still even having a pretty large collection, you can structure you data and use some tricks to speed up things.
- Memoized selectors https://github.com/reactjs/reselect. It's common to use the same selector for different connected components (e.g. number of unread messages). Selector is a pure function, so it could be cached.
- Special data structures, like a hashmap or a binary tree. Indexes that can serve you in limited use cases.
- Working with long queries with standalone services
- Trade-off offline search for online. I wouldn't recommend it if it's a core feature of the app, but sometimes it's the only choice.
Android has limits (and for reasons). You can increase the limit:
long size = 50L * 1024L * 1024L; // 50 MB
com.facebook.react.modules.storage.ReactDatabaseSupplier
.getInstance(getApplicationContext())
.setMaximumSize(size);https://stackoverflow.com/questions/20094421/cursor-window-window-is-full
To overcome this limit you may want to use a special AsyncStorage wrapper like this.