[RFC] torch.distributed.app (role-based + higher-level RPC APIs) #41425
Description
-- with @Tierex, @mrshenli , @pritamdamania, @lw, @agolynski , @osalpekar, @zhaojuanmao, @rohan-varma
🚀 Feature
Concept (and thus a set of APIs) of a distributed.application that comprises of:
- Higher level torch rpc APIs (role-based rpc APIs)
- Succinct init methods to for apps using both rpc and process groups with a heterogeneous topology (roles)
- Ensure all the above works well when launching these apps using TorchElastic.
These sets of APIs makes it easier and more succinct for the user to express different types of application topologies. The goal is to make things simpler for the user hence we assume that apps will be launched via TorchElastic since using TorchElastic to launch distributed PT scripts makes life simpler for the end user as rank assignment, master selection, etc are done automatically and the user no longer has to specify these manually.
Note: distributed.application does not necessarily have to be a new module, it is merely a set of APIs that function on top of the existing rpc and process group APIs that make it simple for the user to write distributed pytorch applications. Hence the proposed methods can be built directly into torch.distributed or torch.distributed.rpc. However, for the sake of clarity, in this doc, we refer to them as being part of distributed.app.
Motivation
When writing a DDP-style application with distributed torch and launching it with torchelastic the user mainly uses ProcessGroups. The user code looks as follows:
def main():
# torchelastic sets the following env vars so that init_method="env://" works:
# RANK, WORLD_SIZE, MASTER_ADDR, MASTER_PORT
torch.distributed.init_process_group(init_method="env://")
# run collective operations using the process group
torch.distributed.all_reduce(...)
There are a few implications here:
- torchelastic performs rank assignment
- implicitly there is a
TCPStorethat is created on the endpoint -MASTER_ADDR:MASTER_PORT - the
TCPStoreobject (both the server and client) lives in the worker’s process
Homogeneous Torch RCP Apps
When all workers in the application are homogenous, they will all participate in the same RPC group and the same process group. The diagram below shows this topology on 3 nodes, each running 4 workers.

In this case, the application continues working well with torchelastic:
def main_rpc_backend_process_group():
rank=int(os.environ["RANK"]),
rpc.init_rpc(
name=f"worker{rank}",
rank=rank,
world_size=int(os.environ["WORLD_SIZE"]),
backend=BackendType.PROCESS_GROUP)
# default process group is initialized as part of init_rpc()
dist.all_reduce(...)
Heterogeneous Torch RPC Apps
Unlike the homogeneous case, in the heterogeneous application, there are sub-groups of nodes that play different roles in the job. The diagram below shows a topology where there is a master node (running a single master process), 2 trainer nodes (each with 4 trainer workers), 3 parameter server nodes (each with 2 parameter server workers).
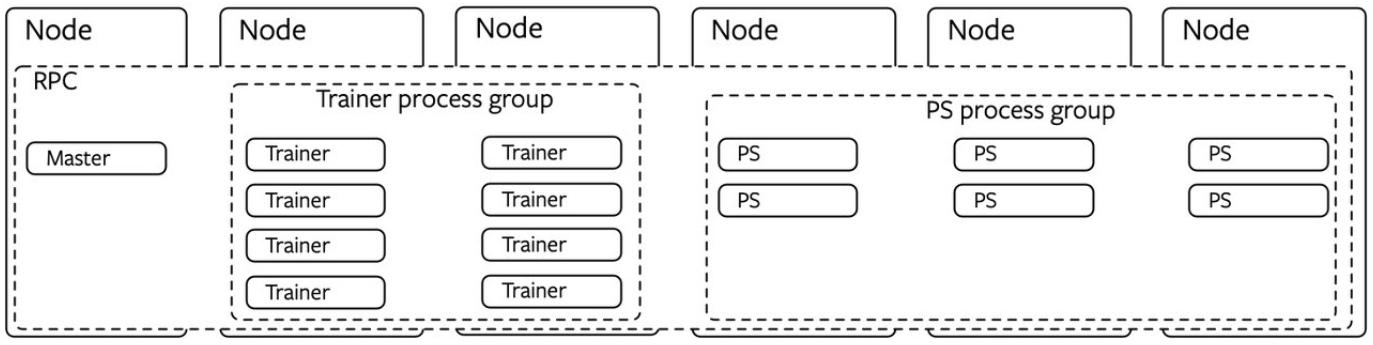
In the heterogeneous case, we want all nodes to be able to invoke remote procedures and hold remote references on each other. However we want the collective operations to be done among the workers of the same role. Ideally, in the heterogeneous case we'd like to make group-rpc calls (e.g. call the same function on all trainers). This is currently cumbersome to do since torch rpc APIs are point-to-point and requires the user to book-keep the worker names for a role and for-loop around them when making rpc calls.
Pitch
Recalling the heterogeneous case above, ideally we'd like the application code to look like the following:
def master_main():
rpc.init_app(role="master", backend=backend, backend_options)
trainer_rets = rpc.rpc_async(on_role="trainer", func=run_trainer, args=(...))
ps_rets = rpc.rpc_async(on_role="ps", func=run_ps, args=(...))
rpc.wait_all(trainer_rets + ps_rets)
def trainer_main():
rpc.init_app(role="trainer", backend=backend, backend_options)
rpc.shutdown()
def run_trainer():
# run the trainer - invoked by master via rpc
all_trainers_pg = rpc.init_process_group()
# technically trainer_main and ps_main can be the same (just pass role as arg)
def ps_main():
rpc.init_app(role="ps", backend=backend, backend_options)
rpc.shutdown()
def run_ps():
# run the ps - invoked by master via rpc
all_ps_pg = rpc.init_process_group()
The next sub-sections describe the changes proposed in the sample code above.
RPC Init App
rpc.init_app(role: str, backend, backend_options) is similar to rpc.init_rpc() except that the call pattern is the same for all processes of the same role. Unlike init_rpc it does not take rank, world_size or init_method since it expects RANK, WORLD_SIZE, MASTER_ADDR, MASTER_PORT to be in the env var. When used with torchelastic these env vars will be set by the elastic agent. Otherwise, the user needs to ensure that the env vars are set before invoking the main method.
After the application is initialized the following hold true:
- Every process (regardless of role) can invoke rpc APIs on one another.
- Every process has a global rank (e.g. one that was passed as
RANKenv var) that can be obtained viadist.get_rank() - Each node is assigned a rank. (this is equivalent to the elastic agent’s rank - a.k.a
GROUP_RANKin torchelastic) - The global rank can be derived from the following formula:

- Where
node_dims[i]returns the number of local processes on node rank i. NODE_RANK(GROUP_RANK),LOCAL_RANKand node_dims is set by elastic agent.- A
roleRankis assigned - this is a number between0 - numWorkersInRoleand may be different from global rank. In the example below the trainer process0on trainer node2gets a global rank of4but a role local rank of3. - The
roleRankis used in theworker_name = {role}:{roleRank}.

Role-based rpc APIs
Since we are working with the concept of roles this is really a syntactic sugar that allows users to perform group rpc calls on all workers belonging to a role rather than having to for-loop around them. It can trivially be implemented by first getting all the worker names for the role (or derive it by using role_world_size = roles[roleRank].x * roles[roleRank].y)
ret_futures = {}
for idx in range(0, roles[trainerRoleRank].x * roles[trainerRoleRank].y)):
name=f"trainer:{idx}"
ret_futures[name] = rpc.rpc_async(to=name, func=foobar, args=(...)))
# versus
ret_futures = rpc.rpc_async_role(role="trainer", func=foobar, args=(...))
Note The original design also included an rpc.wait_all() API for completeness. This has already been implemented in the form of torch.futures.collect_all (https://github.com/pytorch/pytorch/blob/master/torch/futures/__init__.py#L88)
App Init Process Group
Note: this is also discussed in the context of: #33583
Similar to dist.init_process_group() except that this function creates a process group per ROLE. By default it will create the process group for the role that the caller process belongs to. We know the role of the caller since we expect the caller to have called rpc.init_app(role="my_role", ...).
Open Question: should we implement rpc.new_group(names=[]) allowing the user to create process groups, except that since we are in the context of rpc (hence all processes have names) we provide a way to create process groups using names rather than global rank. This is useful as users will tend to think of processes by their names (e.g. the ones they have assigned) rather than their numerical ranks.
App Info Accessors
rpc.get_role_info() expands on rpc.get_worker_info(name) by returning a map of worker_name to WorkerInfo. Useful when operating with roles since when performing point-to-point communication users may need to lookup specific worker information given a role. For instance, the length of the returned collection can be used to determine the total number of workers for a particular role to do some type of index striding for simply for-loop around them to make rpc calls.
Failure Handling Behaviors
This section describes the types of failures and who/how those failures are handled.
We focus on worker process(es) failure since a node failure can be viewed as multiple worker failures. In general TorchElastic views failures as two scaling events: scale-down + scale-up. In TorchElastic the world size is fixed between "rounds" of quorum where "rounds" is defined as the state of the world between two rendezvous versions. Between rounds ALL existing workers are shut down and restarted, hence TorchElastic follows a "all-or-nothing" model when it comes to dealing with faults.
There are three types of torch applications that we care about:
- RPC only (no process groups)
- RPC + DDP
- RPC + DDP + Pipelining
In all three cases the following behavior on failures is guaranteed by TorchElastic:
- Worker process(es) fail
- elastic agent detects the failure
- elastic agent tears down all other workers on the same host
- elastic agent enters a re-rendezvous
- other elastic agents are notified of the re-rendezvous event
- other elastic agents tear down all their respective local workers
- all elastic agents re-rendezvous (e.g. next round) and get assigned a rank
- each elastic agent computes the worker ranks based on the agent ranks
- all elastic agents restart the worker processes
Note: This implies that work between checkpoints are lost.
Note on node failure: TorchElastic is NOT a scheduler hence it cannot deal with replacement of NODES. We rely on the scheduler to replace failed nodes (or containers). Assuming the scheduler replaces the failed node the following behavior is observed on node failures:
- Node(s) fail and are replaced by the scheduler
- Elastic agents are started on the replaced nodes and attempt to join the rendezvous
- The surviving agents are notified of such event and they all tear down their local workers and re-rendezvous
- A new version of rendezvous (e.g. round) is created and the worker processes are started again.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @rohan-varma @xush6528 @jjlilley @osalpekar @jiayisuse