[RFC] Pipeline Parallelism in PyTorch #44827
Description
Introduction
As machine learning models continue to grow in size (ex: OpenAI GPT-2 with 1.5B parameters, OpenAI GPT-3 with 175B parameters), traditional Distributed DataParallel (DDP) training no longer scales as these models don’t fit on a single GPU device. As a result, we need to leverage some sort of model parallelism techniques to train such large models. There are several techniques in the industry that have been employed to achieve this goal. Some examples include GShard and Mesh-Tensorflow from Google, ZeRO from Microsoft and Megatron-LM from Nvidia.
Although, one of the first approach to attempt to solve this problem was pipeline parallelism as described in the GPipe paper. The high level idea is to partition the layers of a model sequentially across several GPUs and then split a mini-batch of data into multiple micro-batches and execute these micro-batches in a pipelined fashion across multiple devices.
This idea is illustrated in Figure 1 below where a mini-batch is split into 4 micro-batches and its execution is pipelined across 4 GPUs. Fi,j denotes the forward pass for micro-batch j on GPU i and Bi,j denotes the backward pass for micro-batch j on GPU i. The update in the end is the optimizer that applies all the gradients.
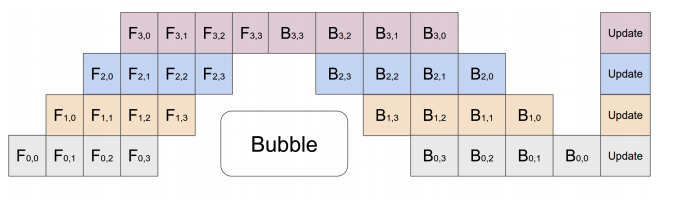
Figure 1 (GPipe)
PyTorch currently provides the basic primitives for users to build such pipelined training themselves. Although as we shall see below, pipeline parallelism involves quite a bit of complexity and it would be extremely useful for users if we could provide an easy to use framework (like DDP) for them. In addition to this pipeline parallelism has been widely studied and used for training large models and as a result it makes it a perfect starting point for PyTorch to support training large models.
Related Work
Pipeline parallelism is an active research area with several different approaches to the problem. torchgpipe is an implementation of GPipe in PyTorch and goes into the nitty gritty details of how to implement such a framework in PyTorch. The fairscale project has forked torchgpipe to provide an implementation of GPipe for various research teams in FAIR.
As you can see in Figure 1, GPipe has some challenges in effectively utilizing GPU resources since it has a pipeline bubble due to the synchronous nature of training. The “update” step at the end needs to synchronize all GPUs and update the parameters before moving onto the next micro-batch. An alternative to this is an asynchronous pipelining approach that is adopted by PipeDream (Figure 2) and XPipe.
As you can see in Figure 2, a mini-batch is split into 4 micro-batches, but the pipeline admits micro-batches from the next mini-batch before the current mini-batch has completely finished. The first mini-batch consists of (1, 2, 3, 4) as micro-batches and the next mini-batch consists of (5, 6, 7, 8). But device 1 starts executing micro-batch 5 as soon as micro-batch 1 is done. This approach provides better GPU utilization and as a result better training throughput, although it also introduces some parameter staleness that can reduce training accuracy.

Figure 2 (PipeDream)
As a result, pipelining approaches can be divided into two broad categories:
- Synchronous (GPipe/torchgpipe): GPUs are not fully utilized in this approach, although it provides better training accuracy and doesn’t affect the existing training loop much. In addition to this, memory utilization is low since we only keep a single version of the weights.
- Asynchronous (PipeDream/XPipe): GPU utilization is much better compared to Synchronous and results in better training throughput. Although, parameter staleness could affect model quality and the asynchronous nature needs some modifications to continuously feed data into the system. In order to overcome the parameter staleness issue, the asynchronous systems usually store multiple versions of the weights (weight stashing/weight prediction) resulting in increased memory utilization.
Target Use Cases
The use case here is mostly for large NLP/CV models that don't fit on a single GPU and this is what Gpipe, torchgpipe, PipeDream and XPipe target. For these use cases, it might be beneficial to provide users the flexibility to choose from synchronous and asynchronous pipelining approaches based on the tradeoffs they are comfortable with.
API Proposal
The high level idea is to support two different APIs for synchronous and asynchronous pipeline parallelism. The reason for two different APIs is due to the fact that the way these APIs would be used would be very different from each other.
torch.distributed.pipeline_async (Option1)
torch.distributed.PipelineAsyncModel(
pipeline: nn.Sequential,
per_stage_optim: List[OptimSpec],
chunks: int = 1)
class OptimSpec {
optimizer_class # Subclass of torch.optim.Optimizer (https://pytorch.org/docs/stable/optim.html#torch.optim.Optimizer).
module_to_optimize # The nn.Module (could be RemoteModule) that needs to be
optimized.
optimizer_args # args to build the optimizer instance.
optimizer_kwargs # kwargs to build the optimizer instance.
}
Arguments:
pipeline: nn.Sequential (https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html) where each nn.Module in the list is placed on the
appropriate device(CPU or GPU)/machine by the user. Note that the
nn.Sequential could also consist of RemoteModule (https://github.com/pytorch/pytorch/blob/master/torch/distributed/nn/api/remote_module.py#L147) for cross host
pipelining.
per_stage_optim: List of OptimSpec, one for each stage of the pipeline.
Should have exactly the same number of elements as pipeline. We use
an OptimSpec here instead of a list of actual optimizer instances
since we don't want to create all the optimizer instances locally.
Instead, we'd like to get a spec and the pipeline can create the
optimizers for the appropriate stages on the appropriate
hosts/devices.
chunks: Number of micro-batches.
PipelineAsyncModel Interface:
PipelineAsyncModel is an interface and users need to override this class to create
an appropriate pipeline instance. The PipelineAsyncModel provides a handful of
methods and the rest need to be implemented by the user. The methods mentioned as
"interface" below have to be implemented by the user.
PipelineAsyncModel.forward(self, *args, **kwargs) -> MinibatchProcessor
Runs the forward pass for the model asynchronously and returns a
"MinibatchProcessor" handle.
PipelineAsyncModel.forward_pre_hook(
microbatch_input,
stage_idx,
microbatch_idx) -> None
Called before the forward pass is called on any stage/microbatch in the pipeline.
Can be used to perform weight prediction.
# interface method
PipelineAsyncModel.forward_post_hook_final_stage(
microbatch_output: Tensor,
microbatch_idx: int
target: Tensor = None, # Tensor/Parameter/ParameterList/nn.Module (anything that supports .to())
dist_autograd_context_id: int,
) -> None
The "forward_post_hook" method is called for every microbatch on the last stage
when the forward pass for the microbatch is complete. The purpose of the
"forward_post_hook" is to compute the loss for the microbatch once it is done
and initiate the backward pass.
"forward_post_hook" has to be pickleable.
Arguments:
microbatch_output: Output of the forward pass of the microbatch.
microbatch_idx: Index of the microbatch that we are processing.
target: Usually the "target" Tensor that would be used to compute the
loss, the pipeline automatically moves the "target" to the last
stage in the pipeline and on the appropriate device as well.
dist_autograd_context_id: The distributed autograd context id to use for
the backward pass. If None, local autograd can be
used.
# interface method
PipelineAsyncModel.backward_post_hook(
per_stage_optim: torch.optim.Optimizer,
microbatch_idx: int,
stage_idx: int) -> None
The "backward_post_hook" method is invoked once the backward pass of a particular
microbatch has finished on a particular stage. The purpose of this callback
is to perform the appropriate optimizer operations (zero_grads, step etc.)
Arguments:
per_stage_optim: The optimizer for this stage, which is built based on
the OptimSpec provided for this stage.
microbatch_idx: Index of the microbatch that we are processing.
stage_idx: Index of the stage on which we are running.
PipelineAsyncModel.save_current_stage(key:str, value: object) -> None
Saves a key:value pair on the current stage of the pipeline. This can only be
used in the provided hooks (forward_post_hook, backward_post_hook etc.) to save
data on the appropriate stage of the pipeline. This can be used for weight
stashing/prediction.
PipelineAsyncModel.save_on_stage(key:str, value: object, stage_id, device_id) -> None
Saves a key:value pair on the given stage of the pipeline. This can be used to
save any additional state on a particular stage and retrieve it accordingly.
Using the device_id option, this state can be saved on either CPU or GPU.
PipelineAsyncModel.retrieve_current_stage(key:str) -> object
Retrieve the value on the current stage that was stored using
"save_current_stage"
PipelineAsyncModel.module_for_current_stage() -> torch.nn.Module
This can only be used in the provided hooks (forward_post_hook,
backward_post_hook etc.) to to get the nn.Module for the current stage.
MinibatchProcessor.set_target(target: Tensor) -> None
Sets the "target" for the minibatch we are processing. This "target"
is moved to the appropriate device on the last stage of the pipeline
and is passed to the "forward_post_hook".
Examples:
# This is an example of a pipeline across two machines each using one GPU.
# On worker 0
layer1 = nn.Linear(10, 5).cuda(0)
# Need to enhance RemoteModule to include device for this purposes.
layer2 = RemoteModule("worker1", device="cuda:0", nn.Linear, 5, 1)
pipeline = nn.Sequential(layer1, layer2)
# Build the optim_spec
optim_spec1 = OptimSpec(optim.SGD, layer1, lr=0.05)
optim_spec2 = OptimSpec(optim.SGD, layer2, lr=0.05)
class SimplePipelineModel(torch.distributed.PipelineAsyncModel):
def forward_post_hook(microbatch_output, microbatch_idx, target, context_id):
loss = F.cross_entropy(microbatch_output, target[microbatch_idx])
dist_autograd.backward([loss], context_id)
def backward_post_hook(per_stage_optim, microbatch_idx, stage_idx):
per_stage_optim.step()
per_stage_optim.zero_grads()
model = torch.distributed.SimplePipelineModel(
pipeline,
[optim_spec1, optim_spec2],
chunks = 4)
for minibatch, target in data:
model(minibatch).set_target(target)
torch.distributed.pipeline_async (Option2)
torch.distributed.pipeline_async(
data_iter: Iterator,
pipeline: nn.Sequential,
dist_optim: DistributedOptimizer,
loss_func: Callable,
chunks: int = 1) -> PipelineAsyncModel
Arguments:
data_iter: An iterator to data consisting of a tuple of input data and the
associated target for that data.
pipeline: nn.Sequential (https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html) where each nn.Module in the list is placed on the
appropriate device(CPU or GPU)/machine by the user. Note that the
nn.Sequential could also consist of RemoteModule (https://github.com/pytorch/pytorch/blob/master/torch/distributed/nn/api/remote_module.py#L147) for cross host
pipelining.
dist_optim: An instance of DistributedOptimizer (https://github.com/pytorch/pytorch/blob/master/torch/distributed/optim/optimizer.py#L58) to optimize the relevant
parameters of the model. Note that we need to use
DistributedOptimizer here since we could have pipelining across
hosts. By default, the optimizer is run inline once the
backward pass completes for a parameter.
loss_func: A Callable that will be passed the output and target for each
microbatch in the pipeline and it is responsible to return the loss
based on that. The returned loss will be used to run the backward
pass.
chunks: Number of micro-batches.
Example:
# This is an example of a pipeline across two machines each using one GPU.
# On worker 0
data = [
(torch.rand(10, 10), torch.rand(10, 1),
(torch.rand(5, 10), torch.rand(5, 1),
]
layer1 = nn.Linear(10, 5).cuda(0)
# Need to enhance RemoteModule to include device for this purposes.
layer2 = RemoteModule("worker1", device="cuda:0", nn.Linear, 5, 1)
pipeline = nn.Sequential(layer1, layer2)
rref_params = [RRef(param) for param in layer1.parameters()]
# Need to enhance RemoteModule for `get_rref_parameters`
rref_params.append(layer2.get_rref_parameters())
dist_optim = DistributedOptimizer(optim.SGD, rref_params, lr=0.05)
# Loss function for the pipeline.
def loss_func(microbatch_output, microbatch_target):
return F.cross_entropy(microbatch_output, microbatch_target)
# Now run the pipeline on our data.
torch.distributed.pipeline_async(
iter(data),
pipeline,
dist_optim,
loss_func,
chunks = 4)
Note on DDP: Given the async nature of the pipeline, we can’t wrap this pipeline easily in DDP since there really is no synchronization point in the pipeline where we can decide to have DDP to start allreducing the gradients. In addition to this, DDP would kind of allreduce after each minibatch which defeats the point of an async pipeline and makes it more inline with the synchronous counter part. Although, if we’d like to run pipeline_async for a model across multiple GPUs in a single host, but Distributed DataParallel across replicas of the model across multiple hosts, we can introduce a parameter called sync_every_minibatches which basically adds a synchronization point after sync_every_minibatches is done and synchronizes all model parameters across different hosts.
torch.distributed.pipeline_async (Option3)
model = torch.distributed.pipeline_async(
pipeline,
[optim_spec1, optim_spec2],
chunks = 4)
futures = []
for microbatch, target in data:
futures.append(
# this returns a special Future that contains the autograd context id
model(microbatch)
# this will forward it's autograd context id to chained future
# and the then function all be wrapped with that context
.then(lambda out_future: loss_fn(target, out_future.wait()))
# the future.then wrapps the returned tensor with custom tensor
# type that overrides the backward function which calls dist.backward
.then(lambda loss_future: loss.backward())
)
torch.futures.collect_all(futures).then(lambda unused: optimizer.step())
Different stages can be chained using .then. If we still get complains that the above API is different from today’s PyTorch API, I guess we can offer loss function and optimizer wrappers that internally calls the .then API.
loss_fn = AsyncLossFn(F.cross_entropy)
opt = AsyncOptimizer(DistributedOptimizer(optim.SGD, rref_params, lr=0.05))
for minibatch, target in data:
out_future = model(minibatch)
loss_future = loss_fn(out_future, target)
bwd_future = loss_future.backward()
opt.wait_for(bwd_future)
opt_done_future = opt.step()
torch.distributed.pipeline_sync
# Note: This API is very similar to torchgpipe and inspired from it.
# torchgpipe API for reference: https://torchgpipe.readthedocs.io/en/stable/api.html
torch.distributed.pipeline_sync(
pipeline: nn.Sequential,
checkpoint: CheckpointEnum = EXCEPT_LAST, # ALWAYS, EXCEPT_LAST, NEVER
chunks: int = 1) -> PipelineSyncModel
Arguments:
pipeline: nn.Sequential (https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html) where each nn.Module in the list is placed on the
appropriate device(CPU or GPU)/machine by the user. Note that
nn.Sequential could also consist of RemoteModule (https://github.com/pytorch/pytorch/blob/master/torch/distributed/nn/api/remote_module.py#L147) for cross host
pipelining.
checkpoint: Enum that determines which checkpointing mode to use.
chunks: Number of micro-batches.
Returns:
An instance of PipelineSyncModel
Forward Method
PipelineSyncModel.forward(self, *input, **kwargs) -> RRef
Returns:
RRef to output corresponding to the result of the minibatch.
Since we plan to support cross host pipelining, the RRef could be on a
device on a different host.
Example:
# This is an example of a pipeline across two machines each using one GPU.
# On worker 0
layer1 = nn.Linear(10, 5).cuda(0)
# Need to enhance RemoteModule to include device for this purposes.
layer2 = RemoteModule("worker1", device="cuda:0", nn.Linear, 5, 1)
pipeline = nn.Sequential(layer1, layer2)
model = torch.distributed.pipeline_sync(pipeline, chunks = 4)
rref_params = [RRef(param) for param in layer1.parameters()]
# Need to enhance RemoteModule for `get_rref_parameters`
rref_params.append(layer2.get_rref_parameters())
dist_optim = DistributedOptimizer(optim.SGD, rref_params, lr=0.05)
# Helper functions
def compute_loss(output_rref, target_rref):
return F.cross_entropy*(*output_rref.local_value()*,* target_rref.local_value()*)*
def identity_fn(inp):
return inp
for minibatch, target in data:
# Use dist autograd context for distributed autograd.
with dist_autograd.context() as context_id:
target_rref = rpc.remote("worker1", identity_fn, target)
output_rref = model(minibatch)
loss_rref = rpc.remote("worker1", compute_loss, output_rref, target_rref)
# Can enhance RRef to ensure this calls "dist_autograd.backward" on the last
# node in the pipeline.
loss_rref.backward(context_id)
dist_optim.step()
Complex Example
In this example, we have two hosts with 8 GPUs each. On each host, we have intra-layer parallelism for the first 4 GPUs and last 4 GPUs and those two groups are connected via pipeline_sync. pipeline_sync itself is wrapped in DDP and the model is replicated across the two hosts. Pseudocode of what this would look like on each host:
# RowParallelLinear here is a slight modification of
# https://fburl.com/6uv0tr07 (https://github.com/facebookresearch/fairscale/blob/e2d8f573f0600e6f9abc370b2b1f800f4b0ecb9e/fairscale/nn/model_parallel/layers.py#L296) to make it more flexible where it can accept
# an arbitrary set of devices.
layer1 = RowParallelLinear(100, 50, devices=[0, 1, 2, 3])
layer2 = RowParallelLinear(50, 20, devices=[4, 5, 6, 7])
model = torch.distributed.pipeline_sync(
nn.Sequential(layer1, layer2),
chunks = 4)
ddp_model = DDP(model)
# Now run the training loop with ddp_model.
Single Process vs Multi-Process on the same host
The same API can be applied to either single process or multi-process setups on a single host. In the multi-process setup, we can use RemoteModule to setup modules on different processes and use TensorPipe's NVLink support to transfer Tensors from one GPU to another.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar @jiayisuse @agolynski @jjlilley