[nhwc support for adaptive_avg_pool2d & adaptive_avg_pool2d_backward] #24396
Conversation
Initial kernel support added for optimized NHWC tensor. TODO: currently backwards kernel spits out tensor with NHWC stride. Unfortunately autograd restores grad to contiguous (in either copy or add). This makes real perf tuning annoying to do. (since I cannot easily measure end-to-end time in my python script) My current kernel is blazing fast comparing to the original NCHW kernel in fp16, since I avoided atomicAdd. I'll finish perf tuning after we merged some future PR expanding NHWC support in the core.
|
Supporting #23403 |
|
cc @ifedan |
|
@jjsjann123 Do you have any performance metrics? NCHW vs NHWC |
|
I do not have general speedup showing the perf improvement because of the extra kernel I mentioned in this PR (hence perf tuning will be in a follow up PR, I did run a swipe test and see rough perf improvements so it should be fine) To give a specific point here, for input as [128, 256, 64, 64] and output as [128, 256, 32, 32], here's the kernel time. You can see slight perf improvement for fp32, and 2x on fp16 backward kernel. I haven't spend enough time looking at the forward kernel yet, Will revisit that in the perf tuning PR later. |
|
@ifedan Graph showing the relative speedup comparing to PyTorch native kernel.
|
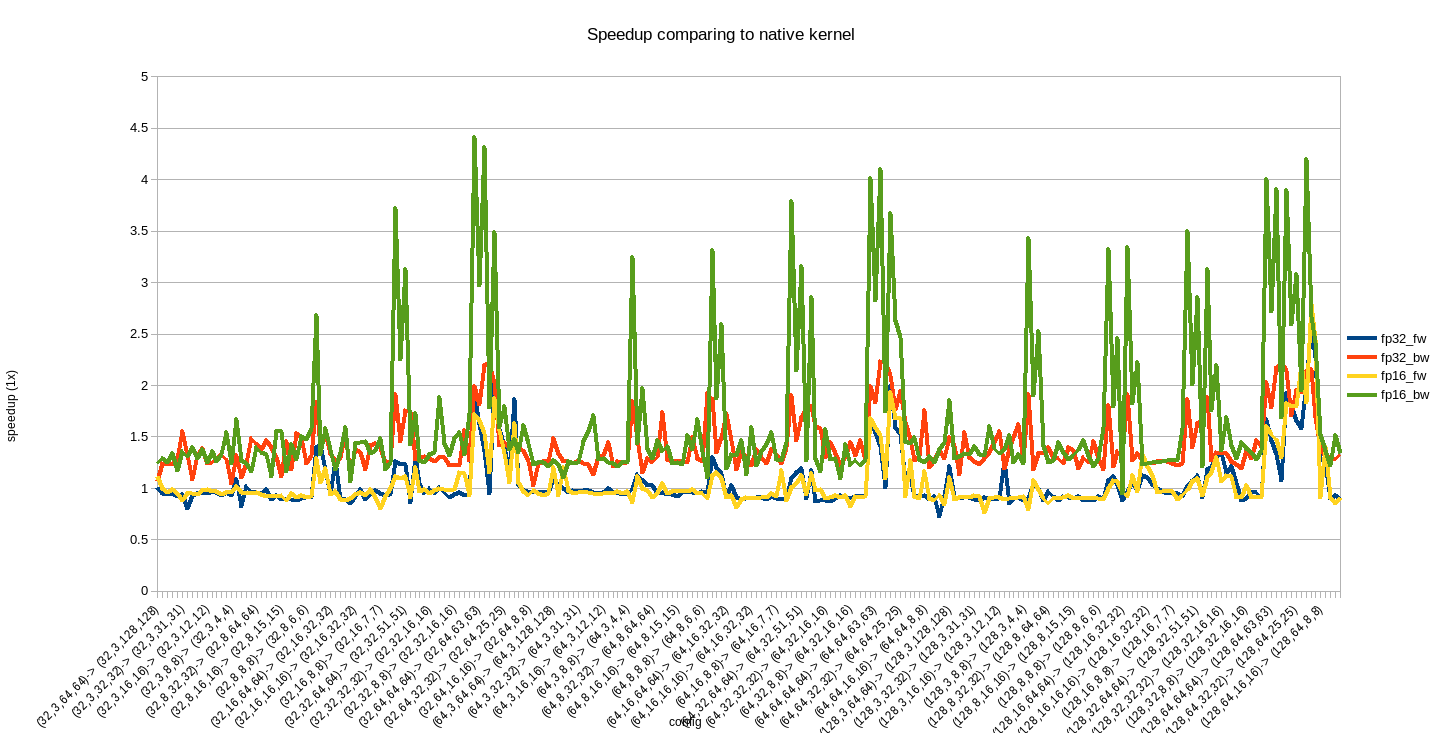
|
Notice that my benchmark was done via hacking: I have to explicitly set |
|
Please rebase, we are getting ready to land it. |
Previous kernel does not stride on Channel dimension, and the kernel uses shared memory to store temporary result (to break data dependency -> code paralellism) Resulted in requesting more resources than what's available. Fixing: added striding on C to reduce shmem usage per CTA.
|
Rebased my code and cherry-picked the patch from #25102 |
2. adding test for non-contiguous input tensor;
|
Should have addressed all review comments. Feel free to take another look. |
There was a problem hiding this comment.
@VitalyFedyunin has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
There was a problem hiding this comment.
@VitalyFedyunin has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
@VitalyFedyunin merged this pull request in e263dd3. |
Summary: Initial kernel support added for optimized NHWC tensor. TODO: currently backwards kernel spits out tensor with NHWC stride. Unfortunately autograd restores grad to contiguous (in either copy or add). This makes real perf tuning annoying to do. (since I cannot easily measure end-to-end time in my python script) My current kernel is blazing fast comparing to the original NCHW kernel in fp16, since I avoided atomicAdd. I'll finish perf tuning after we merged some future PR expanding NHWC support in the core. Pull Request resolved: pytorch/pytorch#24396 Differential Revision: D18115941 Pulled By: VitalyFedyunin fbshipit-source-id: 57b4922b7bf308430ffe1406681f68629baf8834
Summary: Initial kernel support added for optimized NHWC tensor. TODO: currently backwards kernel spits out tensor with NHWC stride. Unfortunately autograd restores grad to contiguous (in either copy or add). This makes real perf tuning annoying to do. (since I cannot easily measure end-to-end time in my python script) My current kernel is blazing fast comparing to the original NCHW kernel in fp16, since I avoided atomicAdd. I'll finish perf tuning after we merged some future PR expanding NHWC support in the core. Pull Request resolved: pytorch#24396 Differential Revision: D18115941 Pulled By: VitalyFedyunin fbshipit-source-id: 57b4922b7bf308430ffe1406681f68629baf8834
Initial kernel support added for optimized NHWC tensor.
TODO: currently backwards kernel spits out tensor with NHWC stride.
Unfortunately autograd restores grad to contiguous (in either copy or add). This
makes real perf tuning annoying to do. (since I cannot easily measure end-to-end
time in my python script)
My current kernel is blazing fast comparing to the original NCHW kernel in fp16,
since I avoided atomicAdd. I'll finish perf tuning after we merged some future
PR expanding NHWC support in the core.