Disable the mkldnn for conv2d in some special cases #40610
Conversation
|
This pull request was exported from Phabricator. Differential Revision: D22250817 |
💊 CI failures summary and remediationsAs of commit 6b9e2e1 (more details on the Dr. CI page): 💚 💚 Looks good so far! There are no failures yet. 💚 💚 This comment was automatically generated by Dr. CI (expand for details).Follow this link to opt-out of these comments for your Pull Requests.Please report bugs/suggestions on the GitHub issue tracker or post in the (internal) Dr. CI Users group. This comment has been revised 3 times. |
|
After #35937 is resolved, we may revert this change. |
There was a problem hiding this comment.
Sure, seems like the testing is reasonably comprehensive.
cc @VitalyFedyunin @Jianhui-Li would be good to follow up on why mkldnn is slower in the first place for small kernels
also @robieta - it might be a good example to try out the benchmarking script to see whether it confirms this heuristic
|
All the benchmarks here are for batch size 1 - results for bigger batch sizes might be different, so it makes sense to add batchsize to heuristics. Also, it's unclear if benchmark results hold in multi-threaded setting. |
Just ran the batchsize larger than 1. It seems with small image input, the mkldnn is faster. For large image, the native is better. We need an ML model to predict. :) Anyway, It make sense to constrain the batchsize >1 to avoid any surprise. |
Alas, I think the answer is much simpler; TH conv doesn't respect thread limits. When I run the following snippet it uses all 24 cores on the machine that I'm using. By contrast, if I set This is on a fresh conda env and built from a fresh checkout of Master. I made an implementation of your benchmark with the |
It actually does not use 24 cores in my side if i set num_of_thread=1. It could migrate from one core to another core, but the utilization is one core. You can put taskset to freeze it on one cpu. |
Yeah, that's what I'm doing now. It's strange to me that setting num_threads works on your setup but not mine. My PyTorch info is: Compared to They're basically identical except for a slightly different GCC version. |
|
In yet another surprising twist, turns out that nnpack does not respect thread settings, and build info above indicates that nnpack is enabled. If I set batch size to 8 in @robieta's script to not trigger nnpack pytorch/aten/src/ATen/native/Convolution.cpp Line 253 in 4c25428 cc @t-vi who added nnpack support. |
|
@ngimel So when I brought this back, we used to use first OpenMP's pytorch/aten/src/ATen/native/NNPACK.cpp Lines 89 to 91 in 4c25428 |
|
@robieta I was talking about my benchmark script, it just uses one CPU core. It seems I can also reproduce the issue by your script. |
|
@t-vi thanks for checking! So you are right, #37243 was reapplied in b7e044f. Even when I revert it, I still get more than 1 thread, because NNPACK.cpp does not include Parallel.h and INTRA_OP_PARALLEL ends up underfined. I'll open a separate issue to track it. |
|
@CaoZhongZ @pinzhenx similar issue to #35937.. @lly-zero-one aside from the standalone benchmark for conv2d, could you provide more info of the model? In case the operators from the model is supported by mkldnn blocked memory format, you can use |
@mingfeima It is a complex internal model, which has trunk and heads. We actually quantize the trunk with int8. So it is using FBGEMM library. Then we dequantize the trunk output and plug it into different heads, which is under fp32. I think in order to lower the subgraph into mkldnm to avoid the layout transform cost, we need to a lot of hacks to the user model and data layout transforms back and forth. By the way, do you have ETA for #35937? |
@lly-zero-one Funny you should mention that... I've been polishing this script (requires #38338), which runs trials on 50,000 different Tensor and kernel pairs which are similar to those in the original benchmark script. (Still missing groups and strides, but otherwise quite comprehensive.) Note that I'm using With a LOT of feature engineering, I was able to get the following decision tree out for deciding whether to use MKL or TH:
Without this magic Overall, the takeaway that I see in this is:
|
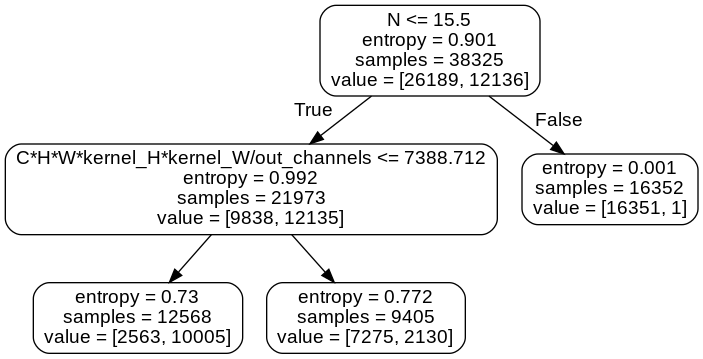
|
Note that the >=16 limit to use nnpack is there very much for historical reasons and the first thing I did when porting PyTorch to Android in 2018 was to use NNPack for any batch size. The fallback TH implementation can be very memory hungry even for batch size 1.
So if you are interested in finding decision boundaries, that one might be worth looking at, too.
|
|
@mingfeima @t-vi I apologize, I misspoke. MKL consistently faster than NNPACK, not the other way around.
Something really strange is going on. ("clowny" as @dzhulgakov would say...) |
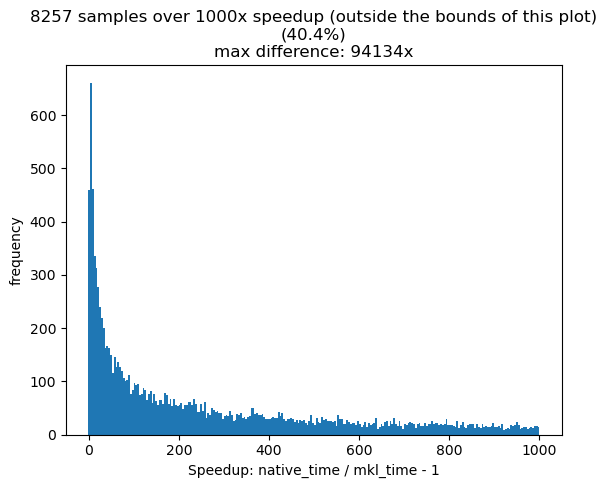
Summary: Pull Request resolved: pytorch#40610 We have benchmarked several models, which shows the native implementation of conv2d is faster mkldnn path. For group conv, the native implementation does not batch all the groups. Test Plan: ``` import torch import torch.nn.functional as F import numpy as np from timeit import Timer num = 50 S = [ # [1, 1, 100, 40, 16, 3, 3, 1, 1, 1, 1], # [1, 2048, 4, 2, 512, 1, 1, 1, 1, 0, 0], # [1, 512, 4, 2, 512, 3, 3, 1, 1, 1, 1], # [1, 512, 4, 2, 2048, 1, 1, 1, 1, 0, 0], # [1, 2048, 4, 2, 512, 1, 1, 1, 1, 0, 0], # [1, 512, 4, 2, 512, 3, 3, 1, 1, 1, 1], # [1, 512, 4, 2, 2048, 1, 1, 1, 1, 0, 0], # [1, 2048, 4, 2, 512, 1, 1, 1, 1, 0, 0], # [1, 512, 4, 2, 512, 3, 3, 1, 1, 1, 1], # [1, 512, 4, 2, 2048, 1, 1, 1, 1, 0, 0], # [1, 2048, 4, 2, 512, 1, 1, 1, 1, 0, 0], # [1, 512, 4, 2, 512, 3, 3, 1, 1, 1, 1], # [1, 512, 4, 2, 2048, 1, 1, 1, 1, 0, 0], # [1, 2048, 4, 2, 512, 1, 1, 1, 1, 0, 0], # [1, 512, 4, 2, 512, 3, 3, 1, 1, 1, 1], # [1, 512, 4, 2, 2048, 1, 1, 1, 1, 0, 0], # [1, 2048, 4, 2, 512, 1, 1, 1, 1, 0, 0], # [1, 512, 4, 2, 512, 3, 3, 1, 1, 1, 1], # [1, 512, 4, 2, 2048, 1, 1, 1, 1, 0, 0], [1, 3, 224, 224, 64, 7, 7, 2, 2, 3, 3, 1], [1, 64, 56, 56, 128, 1, 1, 1, 1, 0, 0, 1], [1, 128, 56, 56, 128, 3, 3, 1, 1, 1, 1, 32], [1, 128, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1], [1, 64, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1], [1, 256, 56, 56, 128, 1, 1, 1, 1, 0, 0, 1], [1, 128, 56, 56, 128, 3, 3, 1, 1, 1, 1, 32], [1, 128, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1], [1, 256, 56, 56, 128, 1, 1, 1, 1, 0, 0, 1], [1, 128, 56, 56, 128, 3, 3, 1, 1, 1, 1, 32], [1, 128, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1], [1, 256, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1], [1, 256, 56, 56, 256, 3, 3, 2, 2, 1, 1, 32], [1, 256, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1], [1, 256, 56, 56, 512, 1, 1, 2, 2, 0, 0, 1], [1, 512, 28, 28, 256, 1, 1, 1, 1, 0, 0, 1], [1, 256, 28, 28, 256, 3, 3, 1, 1, 1, 1, 32], [1, 256, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 28, 28, 256, 1, 1, 1, 1, 0, 0, 1], [1, 256, 28, 28, 256, 3, 3, 1, 1, 1, 1, 32], [1, 256, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 28, 28, 256, 1, 1, 1, 1, 0, 0, 1], [1, 256, 28, 28, 256, 3, 3, 1, 1, 1, 1, 32], [1, 256, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 28, 28, 512, 3, 3, 2, 2, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 512, 28, 28, 1024, 1, 1, 2, 2, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1], [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32], [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 1024, 3, 3, 2, 2, 1, 1, 32], [1, 1024, 7, 7, 2048, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 14, 14, 2048, 1, 1, 2, 2, 0, 0, 1], [1, 2048, 7, 7, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 7, 7, 1024, 3, 3, 1, 1, 1, 1, 32], [1, 1024, 7, 7, 2048, 1, 1, 1, 1, 0, 0, 1], [1, 2048, 7, 7, 1024, 1, 1, 1, 1, 0, 0, 1], [1, 1024, 7, 7, 1024, 3, 3, 1, 1, 1, 1, 32], [1, 1024, 7, 7, 2048, 1, 1, 1, 1, 0, 0, 1], ] for x in range(105): P = S[x] print(P) (N, C, H, W) = P[0:4] M = P[4] (kernel_h, kernel_w) = P[5:7] (stride_h, stride_w) = P[7:9] (padding_h, padding_w) = P[9:11] X_np = np.random.randn(N, C, H, W).astype(np.float32) W_np = np.random.randn(M, C, kernel_h, kernel_w).astype(np.float32) X = torch.from_numpy(X_np) g = P[11] conv2d_pt = torch.nn.Conv2d( C, M, (kernel_h, kernel_w), stride=(stride_h, stride_w), padding=(padding_h, padding_w), groups=g, bias=True) class ConvNet(torch.nn.Module): def __init__(self): super(ConvNet, self).__init__() self.conv2d = conv2d_pt def forward(self, x): return self.conv2d(x) model = ConvNet() def pt_forward(): with torch.no_grad(): model(X) torch._C._set_mkldnn_enabled(True) t = Timer("pt_forward()", "from __main__ import pt_forward, X") print("MKLDNN pt time = {}".format(t.timeit(num) / num * 1000.0)) torch._C._set_mkldnn_enabled(False) t = Timer("pt_forward()", "from __main__ import pt_forward, X") print("TH pt time = {}".format(t.timeit(num) / num * 1000.0)) OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python bm.py ``` output: ``` [1, 3, 224, 224, 64, 7, 7, 2, 2, 3, 3, 1] MKLDNN pt time = 5.891108009964228 TH pt time = 7.0624795742332935 [1, 64, 56, 56, 128, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 1.4464975893497467 TH pt time = 0.721491202712059 [1, 128, 56, 56, 128, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 1.4036639966070652 TH pt time = 3.299683593213558 [1, 128, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.3908068016171455 TH pt time = 2.227546200156212 [1, 64, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.226586602628231 TH pt time = 1.3865559734404087 [1, 256, 56, 56, 128, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.31307839602232 TH pt time = 2.4284918047487736 [1, 128, 56, 56, 128, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 1.5028003975749016 TH pt time = 3.824346773326397 [1, 128, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.4405963867902756 TH pt time = 2.6227117888629436 [1, 256, 56, 56, 128, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.405764400959015 TH pt time = 2.644723802804947 [1, 128, 56, 56, 128, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 1.5220053866505623 TH pt time = 3.9365867897868156 [1, 128, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.606868200004101 TH pt time = 2.5387956015765667 [1, 256, 56, 56, 256, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 6.0041105933487415 TH pt time = 5.305919591337442 [1, 256, 56, 56, 256, 3, 3, 2, 2, 1, 1, 32] MKLDNN pt time = 1.4830979891121387 TH pt time = 7.532084975391626 [1, 256, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.025687597692013 TH pt time = 2.2185291908681393 [1, 256, 56, 56, 512, 1, 1, 2, 2, 0, 0, 1] MKLDNN pt time = 3.5893129743635654 TH pt time = 2.696530409157276 [1, 512, 28, 28, 256, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.8203356079757214 TH pt time = 2.0819314010441303 [1, 256, 28, 28, 256, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.8583215996623039 TH pt time = 2.7761065773665905 [1, 256, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.9077288135886192 TH pt time = 2.045416794717312 [1, 512, 28, 28, 256, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.805021796375513 TH pt time = 2.131381593644619 [1, 256, 28, 28, 256, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.9023251943290234 TH pt time = 2.9028950072824955 [1, 256, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.1174601800739765 TH pt time = 2.275596000254154 [1, 512, 28, 28, 256, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.100480604916811 TH pt time = 2.399571593850851 [1, 256, 28, 28, 256, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.9321337938308716 TH pt time = 2.886691205203533 [1, 256, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.065785188227892 TH pt time = 2.1640316024422646 [1, 512, 28, 28, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 5.891813579946756 TH pt time = 4.2956990003585815 [1, 512, 28, 28, 512, 3, 3, 2, 2, 1, 1, 32] MKLDNN pt time = 0.9399276040494442 TH pt time = 4.7622935846447945 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.2426914013922215 TH pt time = 2.3699573799967766 [1, 512, 28, 28, 1024, 1, 1, 2, 2, 0, 0, 1] MKLDNN pt time = 3.0341636016964912 TH pt time = 2.6606030017137527 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.991385366767645 TH pt time = 2.6313263922929764 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7330256141722202 TH pt time = 3.008321188390255 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.880081795156002 TH pt time = 2.289068605750799 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.9583285935223103 TH pt time = 2.6302105747163296 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7322711870074272 TH pt time = 2.8230775892734528 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.8620235808193684 TH pt time = 2.4078205972909927 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.828651014715433 TH pt time = 2.616014201194048 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7084695994853973 TH pt time = 2.8024527989327908 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.7884829975664616 TH pt time = 2.4237345717847347 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.89030060172081 TH pt time = 2.5852439925074577 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.724627785384655 TH pt time = 2.651805803179741 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.249914798885584 TH pt time = 2.0440668053925037 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.722136974334717 TH pt time = 2.531316000968218 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7164162024855614 TH pt time = 2.8521843999624252 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.8891782090067863 TH pt time = 2.436912599951029 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.0049769952893257 TH pt time = 2.649025786668062 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7299130037426949 TH pt time = 2.67714099958539 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.799382768571377 TH pt time = 2.4427592009305954 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.0201382003724575 TH pt time = 2.6285660080611706 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.6983320042490959 TH pt time = 2.9118607938289642 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.8802538104355335 TH pt time = 2.385452575981617 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.9600497893989086 TH pt time = 2.594646792858839 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.5688861943781376 TH pt time = 2.5941073894500732 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.7758505940437317 TH pt time = 2.336081601679325 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.6135251857340336 TH pt time = 2.3902921937406063 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.6303061917424202 TH pt time = 2.6228136010468006 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.8868251852691174 TH pt time = 2.5620524026453495 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.057632204145193 TH pt time = 2.691414188593626 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7316274009644985 TH pt time = 3.14683198928833 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.2674955762922764 TH pt time = 2.602821197360754 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.0993166007101536 TH pt time = 2.609328981488943 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7257938012480736 TH pt time = 2.9255208000540733 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.3086097799241543 TH pt time = 2.544360812753439 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.0537622049450874 TH pt time = 2.6343842037022114 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7194169983267784 TH pt time = 2.9009717889130116 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.6461398042738438 TH pt time = 2.3600555770099163 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.6328082010149956 TH pt time = 2.415131386369467 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.6832938082516193 TH pt time = 2.6299685798585415 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.9594415985047817 TH pt time = 2.509857602417469 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.956229578703642 TH pt time = 2.691046390682459 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7222409918904305 TH pt time = 2.938339803367853 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.9467295855283737 TH pt time = 2.4219116009771824 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.0215882137417793 TH pt time = 2.7782391756772995 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.719242412596941 TH pt time = 2.8529402054846287 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.8062099777162075 TH pt time = 2.9951974004507065 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.1621821969747543 TH pt time = 2.5330167822539806 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.690075010061264 TH pt time = 2.5531245954334736 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.832614816725254 TH pt time = 2.339891381561756 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.7835668064653873 TH pt time = 2.513139396905899 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7026367820799351 TH pt time = 2.796882800757885 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.6479675993323326 TH pt time = 2.4971639923751354 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.9846629686653614 TH pt time = 2.4657804146409035 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.5969022028148174 TH pt time = 2.697007991373539 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.7602720074355602 TH pt time = 2.4498093873262405 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.963611613959074 TH pt time = 2.6310251839458942 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7004458084702492 TH pt time = 2.9164502024650574 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.887732572853565 TH pt time = 2.4575488083064556 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.8350806050002575 TH pt time = 2.23197178915143 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.5626789852976799 TH pt time = 2.704860605299473 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.6168799959123135 TH pt time = 2.2481359727680683 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.5654693879187107 TH pt time = 2.2636358067393303 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.6836861930787563 TH pt time = 2.825192976742983 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.7971909940242767 TH pt time = 2.471243590116501 [1, 1024, 14, 14, 512, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.8480279818177223 TH pt time = 2.553586605936289 [1, 512, 14, 14, 512, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.7191735878586769 TH pt time = 2.6465672068297863 [1, 512, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 2.7811027877032757 TH pt time = 2.457349617034197 [1, 1024, 14, 14, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 5.434317365288734 TH pt time = 4.639615211635828 [1, 1024, 14, 14, 1024, 3, 3, 2, 2, 1, 1, 32] MKLDNN pt time = 0.9400106035172939 TH pt time = 2.9971951991319656 [1, 1024, 7, 7, 2048, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 4.494664408266544 TH pt time = 3.478870000690222 [1, 1024, 14, 14, 2048, 1, 1, 2, 2, 0, 0, 1] MKLDNN pt time = 4.8432330042123795 TH pt time = 3.6410867795348167 [1, 2048, 7, 7, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 4.779010973870754 TH pt time = 3.4093930013477802 [1, 1024, 7, 7, 1024, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.8385192044079304 TH pt time = 3.0921380035579205 [1, 1024, 7, 7, 2048, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 3.9088409766554832 TH pt time = 3.130124807357788 [1, 2048, 7, 7, 1024, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 4.0072557888925076 TH pt time = 2.977220807224512 [1, 1024, 7, 7, 1024, 3, 3, 1, 1, 1, 1, 32] MKLDNN pt time = 0.8867520093917847 TH pt time = 3.1505179964005947 [1, 1024, 7, 7, 2048, 1, 1, 1, 1, 0, 0, 1] MKLDNN pt time = 4.118196591734886 TH pt time = 3.46621660515666 ``` Reviewed By: dzhulgakov Differential Revision: D22250817 fbshipit-source-id: 200f7807e26d2e97dc56e1285ce93f05d90631d4
63f1104 to
6b9e2e1
Compare
|
This pull request was exported from Phabricator. Differential Revision: D22250817 |
I'm confused for two reasons. First, when I run this script (which is just your script with some more bookkeeping) on the latest master with Let's touch base in the morning since it's somewhat urgent to wrap this up. |
|
This pull request has been merged in 48d6e2a. |
Summary: We have benchmarked several models, which shows the native implementation of conv2d is faster than mkldnn path. For group conv, the native implementation does not batch all the groups.
Test Plan:
output:
Differential Revision: D22250817