Add Bfloat16 optimizer with Kahan summation option for high precision updates #52
Conversation
There was a problem hiding this comment.
Looks good overall, couple of comments inline.
Let's also add unittests as part of this to ensure correctness and robustness. For example, we could have a test to ensure full parity with the AdamW optimizer when none of the kahan/bf16 specific stuff is going on?
|
This is very awesome, @lessw2020! would it be possible to use some more intuitive mnemonic for its name - I'm not sure how BFF came to be - perhaps call it BF16Adam? What does BFF stand for? Unless this is an attempt to be future proof and down the road easily adapt to even lower precision dtypes and thus not wanting to hardcoded BF16? so FP8 Adam next? |
Hi @stas00 - thanks for the kind feedback! (note I did change from BFF_Optimizer to BFF_AdamW to note that the core algo is still AdamW, just with Kahan summation and flexible dtypes. Have also tested a bit with stochastic rounding but results were not impressive enough to move forward with so far.) Re BFF = it was just a play on Best Friends Forever and BFloat lol, meaning the optimizer would continue to improve over time as a platform optimizer with additional iterations. |
|
Thank for sharing the commentary, @lessw2020. That helps to understand the choices. If I may propose |
src/optimizers/bff_optimizer.py
Outdated
| @@ -4,7 +4,7 @@ | |||
| # This source code is licensed under the BSD-style license found in the | |||
| # LICENSE file in the root directory of this source tree. | |||
|
|
|||
| # Flexible_Precision_AdamW: a flexible precision AdamW optimizer | |||
| # FlexiblePrecision_AdamW: a flexible precision AdamW optimizer | |||
There was a problem hiding this comment.
probably best not to mix CamelCase and foo_bar styles for class names, no?
There was a problem hiding this comment.
Hi @stas00 - yes you are right. I checked the PEP8 guidelines and it is a no go:
"Class | Start each word with a capital letter. Do not separate words with underscores."
I was going for better readability by breaking apart things, but will keep it correct.
Thanks for flagging this!
There was a problem hiding this comment.
Hi @stas00 - after discussion with @rohan-varma, we are going with "MixedPrecisionAdamW".
This actually meshes well, as the main use case is with FSDP Mixed Precision, and based on some research I've been doing, the easy "I just want to change two lines and free up GPU memory and train faster" is simply plugging it in with the default mixed precision settings.
You can still set it to pure mode and run all BF16 and with or without Kahan summation for extra precision.
Thanks again for all the feedback here!
There was a problem hiding this comment.
This might get confused with the mixed precision concept of AMP, and it's not quite the same conceptually. The concept of mixed precision refers to the different parts of the fwd/bwd/step stages performed in 2 different precisions.
I have absolutely no attachment to the name I proposed earlier, but I'm suggesting to use any new name with self-explainable mnemonics, rather than overload the existing one.
And since it supports any precision, including FP32, it's hard to see how this is mixed.
The logical concept here is more ANY, rather than AND (mixed = more than one) - perhaps AnyPrecisionAdamW?
There was a problem hiding this comment.
Hi @stas00 - agreed, and we're changing to your proposed "AnyPrecisionAdamW" :)
Thanks again for all the feedback on this!
|
@pytorchbot merge |
|
Is the usage documentation missing on purpose? i.e. not in https://pytorch.org/torchdistx/latest/ - if you want feedback and users don't know new features were added how would they know to try them out? Also, won't it be good to move the source from and not the "headless": Thank you. |
|
Just checking out this PR. Thanks @stas00, it is certainly a bug. All Python files should reside under |
|
If I'm not mistaken it should be just |
|
The full path where it should reside is https://github.com/pytorch/torchdistx/tree/main/src/python/torchdistx. If I don't hear back from Rohan or Less by EOD, I can fix this quickly. I will keep you posted. |
|
oh, I see - because the code then gets moved to |
|
@stas00 here you go: #60. Apparently we also don't have any tests for |
|
Apologies for late response - it looks like @cbalioglu already moved the directory. There is a follow up task to add unittests: #57 - @lessw2020 would you have time to work on this? |
|
and docs please if it's not too much trouble. Thank you! |
| momentum_dtype = dtype for momentum (default: BFloat32) | ||
| variance_dtype = dtype for uncentered variance (default: BFloat16) | ||
| compensation_buffer_dtype = dtype for Kahan summation | ||
| buffer (default: BFloat16) |
There was a problem hiding this comment.
why is the default bf16 and not fp16? won't it be more precise than bf16? Thanks!
There was a problem hiding this comment.
Hi @stas00 - BF16 is a drop in replacement for FP32 b/c it has the same dynamic range.
FP16 requires scaling due to the lower than FP32 dynamic range.
Technically FP16 does have greater precision, but the fact that the range of it is so poor means you need to rescale in order to effectively use. (hence all the grad_scaler you see, and the reason many have given up on FP16 for LLM training).
Thus, I use BF16 here since it is a drop in replacement (though yes with lower precision than FP16 and FP32) for FP32, and no rescaling (aka guessing) needed.
Hope that helps!
There was a problem hiding this comment.
Thank you for the follow up, Less
But the compensation buffer is to save the error that didn't get added up. If the error is smaller than what bf16 can handle, aren't we getting "an error" on "an error" here? I mean the compensation buffer could get zero'ed out as well in such cases.
And of course you're right that the compensation buffer is also used in this code to add the big numbers - fp16 could easily overflow - yes. Perhaps only the error should be stored in a higher precision format and be added and not be added to?
Would it be a "safer" default to use fp32? And let the user decide if they want the error to be not fully carried over.
On the other hand if the grads are in bfloat16 then there will be no loss if the compensation buffer is in bf16 I think.
There was a problem hiding this comment.
Hi Stas,
I see what you mean here - it is possible that fp32 might improve the precision for the comp buffer. The flip side is that of course increases the memory, and and we also have overhead from up and downcasting.
Originally I was focused on creating a pure bfloat16 pipeline (i.e. model, optimizer, etc) all in pure bfloat16 so that was really the main focus.
With that accomplished, we could review additional optimizations like customizing the comp buffer. Note that I had tried using stochastic rounding to remove the need for the buffer, but that did not work as well and so dropped that.
I also did some work with int8 quantized (dynamic block quantization) as the buffer, but seemed to be problematic when used for fine tuning.
I could test out some different alternatives to try and compare impact - do you have one or two recommended models/training examples that would be representative of your users most typical use cases?
That way I can setup and we can plug in different comp options and compare the tradeoffs.
There was a problem hiding this comment.
Thank you for sharing the background story, Less
I don't have any specific examples at the moment.
But I have just trained from scratch OPT-1.3b in fp16/fp32/bf16 - mixed precision for non-fp32 - using the exact same setup otherwise. As you can see bf16 gives a much much slower loss curve.
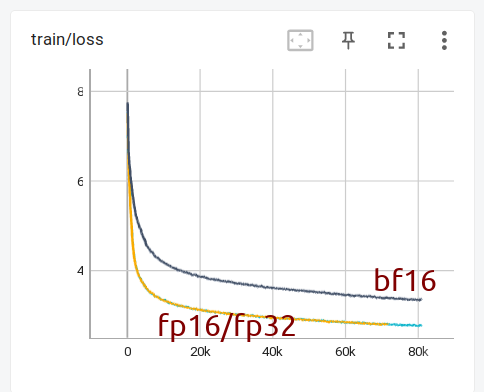
In order to catch up with fp16/fp32 I need to feed 10x more batchsize to bf16 setup.
This of course isn't the same situation, but it's quite telling how bf16, while really helpful at avoiding instabilities when training huge models, is a much much slower training regime otherwise. Hence the concerns of having it as the default.
There was a problem hiding this comment.
and so the goal is to show that bf16-pure/anyprecision(bf16) trains as fast as fp16/amp/adamw - which currently isn't the case (at least with opt-1.3)
There was a problem hiding this comment.
I tried on a larger server but still each card is A10 23GB...seems you are expecting A100s and 40GB? Not sure what the trainer is doing exactly but this would easily run with FSDP.
Can you clarify the expected hardware to run this?
There was a problem hiding this comment.
You can see the details here: #52 (comment)
As I suggested let's switch to opt-125m instead
There was a problem hiding this comment.
I updated the instructions here: huggingface/transformers#21312 to include 125m - 10x smaller - should fit into 24GB card no problem.
There was a problem hiding this comment.
Hi @lessw2020 - we are still interested in your suggestion that you were able to train pure bf16 faster than fp16/amp.
how do I reproduce it?
|
ok, so I first checked that I got the math right for opt-1.3B Theoretical memory allocation for optim states, weights, grads Real memory allocation: (got by adding So the theoretical and actual numbers check out memory wise. the runs were: a. bf16 mixed precision: b. bf16 pure: the only difference between a and b is b has: And to support |
|
Now the problem is that I get the same loss curve with a and b. Less, you suggested that pure-bf16 should do better than mixed bf16, but I get identical outcomes. fp16/mixed precision learns much faster than bf16 here on opt-1.3b |
|
@lessw2020 @stas00 did either of you manage to get pure bf16 training working as well as mixed prec? I see above that Stas was finding it less effective in his tests last year, although I see that pure bf16 training is part of llama-recipes nowadays so I figure it must have had some successful runs? |
|
I haven't retried since my attempt since I haven't heard back from Less since then. My hunch is that pure bf16 should train at a slower pace, given the same number of consumed samples, as the steps are less precise, but since lots of memory and gpu resources are freed it can go overall faster and perhaps converge at about the same wallclock speed (or even faster)? Also see NVIDIA/nccl#1026 where we have been discussing the lossy nccl reduction of grads which I guess fits well with training in pure bf16 as everything is lossier there. Because if you do bf16 mixed precision you most likely want to reduce in fp32. Which adds even more overhead. |
|
Thank you for your reply, Stas. Do you know how mixed precision interacts with lora -- is it keeping fp32 copies only of the adaptor weights (which AFAICT is all that's needed); if so, then I guess for lora mixed precision might end up quite a bit better. |
|
I don't know, but let me tag the LORA expert @younesbelkada. Younes could you please help answer Jeremy's question. Thank you! |
|
Hi @stas00 and @jph00 ! |
|
Thanks a lot, Younes! |
|
By default, the weights of lora layers are in FP32. In practice, when using QLoRA with BF16, they are cast to BF16, which works fine. The relevant code snippet is here: https://github.com/artidoro/qlora/blob/7f4e95a68dc076bea9b3a413d2b512eca6d004e5/qlora.py#L396-L405 |
|
Important: as communicated by Less elsewhere so look for updates in there. |
|
Message ID: ***@***.***>Whilst it's true that it it should keep fp32 copies only of the adapter weights, I wonder if there's some problem happening, because in practice when I use llama-recipes, with fsdp cpu offloading, going from pure bf16 to mixed precision nearly doubles CPU RAM usage from 46->83GB, and per-GPU RAM usage increases from 27->32GB.
This is training a 34B model on 8 A6000 GPUs.
|
What does this PR do? Please describe:
This adds a pure BFloat16 AdamW optimizer (BFF_Optimizer) with user controllable dtypes for momentum and variance states, and available Kahan summation for high precision weight updates for training in pure BFloat16. The Kahan summation buffer also has user selectable dtype.
All states and buffers default to BFloat16.
This allows for experimentation with optimizer states in various dtypes (notably BF16, but also a mix of dtypes) and allows high precision updates via Kahan summation for running with pure BFloat16 training.
Running with momentum and variation = torch.float32 and Kahan_summation=False reverts you to traditional AdamW optimizer for easy comparisons.
Fixes #{issue number}
Not a fix, but related to pytorch/pytorch#82513
Does your PR introduce any breaking changes? If yes, please list them:
No, it is a drop in replacement for AdamW optimizer but with pure BF16 / customizable dtypes and precision.
Check list: