Remove sampling error from probability calculation #397
Description
What is the current behavior?
In many curve analysis subclasses, the fit quality is evaluated based on chi-squared value. However, sampling error calculated here
https://github.com/Qiskit/qiskit-experiments/blob/accc6ee71bf83714a44e2399a0b7e64ffada3596/qiskit_experiments/data_processing/nodes.py#L475-L481
tends to become smaller as counts increases. Then. this small error value (<<1) is taken into the fitting module,
https://github.com/Qiskit/qiskit-experiments/blob/accc6ee71bf83714a44e2399a0b7e64ffada3596/qiskit_experiments/curve_analysis/curve_fit.py#L141-L143
and will be squared and divide residuals. As a consequence, it unintentionally amplifies chi-squared value.
This is kind of a defect, because I can cheat, not limited to, Rabi Experiment.
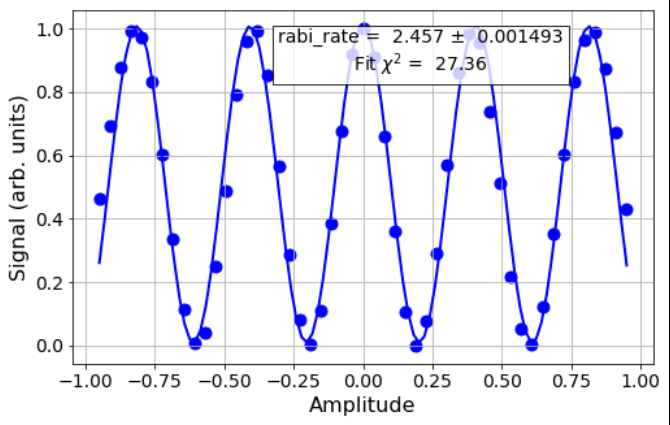
Here I just modified scan parameters so that the result contains more oscillation to get more data points around 1.
The fit quality of above experiment result becomes "bad" because one of criterias is chi-sq < 3.