Well known mime types and Composite metadata extension #635
Conversation
8a32371 to
4caa9ca
Compare
| try { | ||
| knownType = WellKnownMimeType.fromMimeType(customOrKnownMimeType); | ||
| } | ||
| catch (IllegalArgumentException iae) { |
There was a problem hiding this comment.
this should be done this with an if/else instead of catching an exception
5a936d6 to
f536cf0
Compare
| * @return the decoded {@link Entry} | ||
| */ | ||
| public static Entry decodeIncrementally(ByteBuf buffer, boolean retainMetadataSlices) { | ||
| Object[] entry = CompositeMetadataFlyweight.decodeNext(buffer, retainMetadataSlices); |
There was a problem hiding this comment.
This should return ByteBufs, and the Entry type should be a flyweight. We shouldn't need to allocate any objects when we read this
There was a problem hiding this comment.
so ByteBuf[2]? in this case I'm thinking we can expose the mime buffer this way:
- if the mime is an encoded id, a 1 byte long
ByteBufthat represents the still encoded id (raw slice from the original buffer, need to do further bit manipulation) - if the mime is as custom string, a 2 to 129 bytes long
ByteBuf, a slice of the underlying buffer that encompasses both the length byte and the mime string itself.
Since the mime string slide would have no more readable bytes than necessary to decode the string, the first byte could simply be discarded. Yet without it there would be a corner case ambiguity for 1 byte long buffer`, which can either be:
- the case of a 1 byte encoded id
- the case of a 1 byte long String
So reading the mime buffer is a matter of checking its size is 1 byte and applying the mask OR size is 2+ bytes and skipping 1 byte then reading as CharSequence.
Does that sound good?
There was a problem hiding this comment.
note: the second ByteBuf would be a simple sliced of the original part that contains the metadata content, so its readableBytes reflect the size of the "content" (not including the encoded length)
| * @param compositeMetadataBuffer the composite buffer to which this metadata piece is added | ||
| * @param metadataEntry the {@link Entry} to encode | ||
| */ | ||
| public static void encodeIncrementally(ByteBufAllocator allocator, CompositeByteBuf compositeMetadataBuffer, Entry metadataEntry) { |
There was a problem hiding this comment.
We shouldn't need an Entry object to create an entry. This should be done with a method so we don't need to allocate an object.
There was a problem hiding this comment.
i.e.
encodeIncrementally(ByteBufAllocator allocator, CompositeByteBuf compositeMetadataBuffer, String key, String value)
encodeIncrementally(ByteBufAllocator allocator, CompositeByteBuf compositeMetadataBuffer, WellKnownMimeTypes type, String value)
and so on
|
@robertroeser I modified the PR to have cleaner separation of concerns between |
8fba106 to
b0b0eb3
Compare
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
The flyweight also exposes a method to decode Composite Metadata to a Map. Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
The API is intended as a readonly way of listing the composite metadata mime-buffer pairs, as well as accessing metadata pairs by mime type or index, including the case where a mime type is associated with several metadata entries (`List<Entry> getAll(String)`)... Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Instead has 2 special enums. int parsing allows detection of potentially legit type that is still unknown to the current implementation, which could help making it more future-proof. Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Encoding becomes a mirror of decoding, purely based on Entry. Accommodate 3 flavors of mime type decoding: - compressed well known with id matching an enum - uncompressed custom string - compressed but known as reserved for future use (future proofness) The later can be decoded into a special Entry that will allow re encoding it and transmitting it to other nodes as it was. Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
- the flyweight deals with low-level encoding/decoding with minimal garbage and only uses exceptions in the encoding path -- encoding a non-ASCII custom mime type OR -- encoding an out of range byte - the CompositeMetadata is an _option_ for a higher level Iterable-based API, but which instantiates new types Signed-off-by: Simon Baslé <sbasle@pivotal.io>
b0b0eb3 to
4364262
Compare
Entry is now the only high-level abstraction, will need a way to decode into a List<Entry>. Signed-off-by: Simon Baslé <sbasle@pivotal.io>
9f4ec1a to
6a77dd2
Compare
|
6a77dd2 : removed the highest abstraction
|
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
|
@robertroeser @rstoyanchev I think this is finally in a good state, taking your respective comments into account. |
|
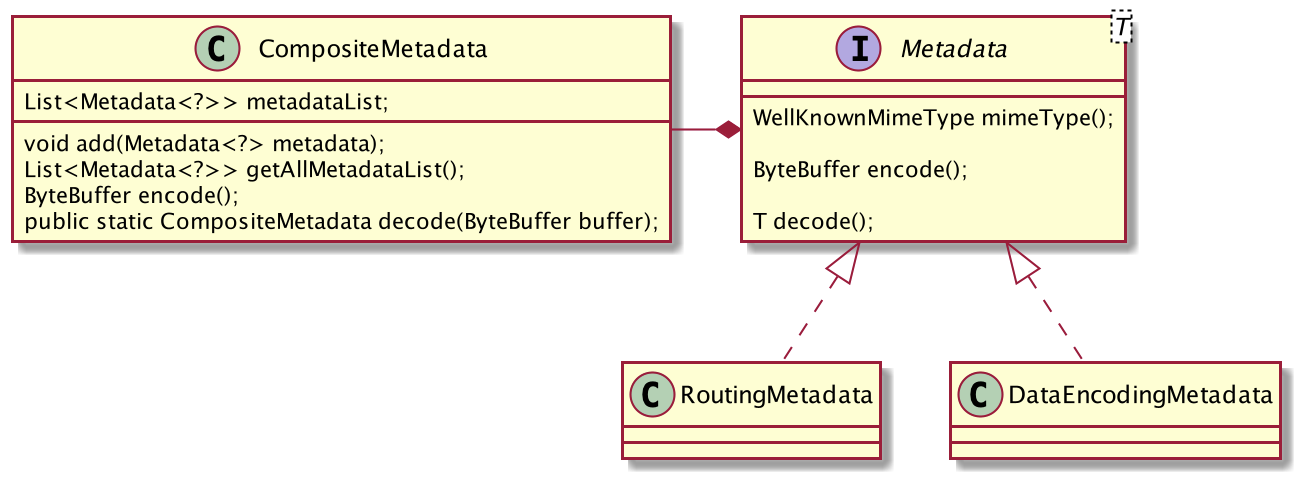
@simonbasle a quick question, could we add some open classes to operate metadata easy. I found Metadata class from Spring Cloud gateway, https://github.com/spring-cloud/spring-cloud-gateway/blob/master/spring-cloud-gateway-rsocket/src/main/java/org/springframework/cloud/gateway/rsocket/support/Metadata.java, but this Metadata.java just for routing, not abstract Metadata. The following just my thoughts. :)
|
| * is merely reserved but unknown to this implementation. | ||
| */ | ||
| public static WellKnownMimeType fromId(int id) { | ||
| if (id < 0 || id > 127) { |
There was a problem hiding this comment.
Checkout out how FrameType looks up FrameType via its code:
https://github.com/rsocket/rsocket-java/blob/develop/rsocket-core/src/main/java/io/rsocket/frame/FrameType.java#L209
You can pre-compute the values into an array so you can look up using an array index instead of a for loop
There was a problem hiding this comment.
thanks for the pointer, done 👍
it looks like the same for the String based lookup could be improved with a static Map<String, WellKnownMimeType>:
Benchmark Mode Cnt Score Error Units
WellKnownMimeTypePerf.fromStringMapLookup thrpt 10 43906830.064 ± 1775994.988 ops/s
WellKnownMimeTypePerf.fromStringValuesLoopLookup thrpt 10 2041048.116 ± 42704.445 ops/s
wdyt?
There was a problem hiding this comment.
yeah - that's a big difference
| // the encoded length is assumed to be kept at the start of the buffer | ||
| // but also assumed to be irrelevant because the rest of the slice length | ||
| // actually already matches _decoded_length | ||
| flyweightMimeBuffer.skipBytes(1); |
There was a problem hiding this comment.
Does this adjust the readIndex? One the RSocket frames do is not adjust the read index to the call because it leads to weird problems when use the frames else.
Also I thought the first bit not the first byte was what in was what determined length- so if the first bit is 0 do you need to skip anything?
There was a problem hiding this comment.
it indeed increases the readerIndex(). the first bit encodes the flag wether or not the remaining 7 bits represent a length or a mime id (if I interpreted the spec correctly, cc @nebhale). But since the previous step in decoding produced a buffer slice that has exactly stringMimeTypeLength + 1 readableBytes(), we can assume this whole byte is A) starting with 1 and B) irrelevant to decode again.
The idea behind including this extra byte in the buffer was to avoid ambiguity between 2 possible 1-byte cases: 1 byte representing a compressed mime id vs 1 byte representing a 1-char mime string. By including it, the minimum length for the string case is 2 bytes, and thus we can differentiate by simply looking at readableBytes().
There was a problem hiding this comment.
note that I assumed it was ok to move the readerIndex() when decoding and slicing?
(I rely on said index having moved when further decoding the next entry in the composite metadata buffer)
There was a problem hiding this comment.
Generally we've found its not okay to leave it changed once you're done with the flyweight. If you look at the RSocket frames they all reset the index afterwards to leave the bytebuf in the same state they found it.
| static ByteBuf encodeMetadataHeader( | ||
| ByteBufAllocator allocator, String customMime, int metadataLength) { | ||
| ByteBuf mimeBuffer = allocator.buffer(customMime.length()); | ||
| mimeBuffer.writeCharSequence(customMime, CharsetUtil.UTF_8); |
There was a problem hiding this comment.
It's probably easier to use ByteBufUtil.writeAscii(allocator, customMime); to create the mimeBuffer
There was a problem hiding this comment.
I pushed a change that simplifies that encode method, avoiding the use of a CompositeByteBuf. But I think UTF8 writing is still required to detect non-ASCII chars, as writeAscii silently removes such characters (see commit message)
| * content buffer, or one of the zero-length error constant arrays | ||
| */ | ||
| public static ByteBuf[] decodeMimeAndContentBuffers( | ||
| ByteBuf compositeMetadata, boolean retainSlices) { |
There was a problem hiding this comment.
Where is the flyweight for the items in this array?
There was a problem hiding this comment.
only the first of the two buffers needs to be decoded (IF it exists, as the array can be empty in case of malformed composite), and the methods to do so are in the same CompositeMetadataFlyweight:
decodeMimeIdFromMimeBufferin casereadableBytes() == 1decodeMimeTypeFromMimeBufferotherwise
There was a problem hiding this comment.
The way I was thinking about doing this was Iterator that kept track of indexes and then a flyweight you would place over the ByteBuf slices the iterator emitted. You'd have an EntryFlyweight with a couple static methods.
There was a problem hiding this comment.
Ok I see - the CompositeMetadata is the flyweight for an indiviual entry(?). How do you tell the demaraction between CompositeMetadata? Like if you have 8 metadatas and you want to iterator over them?
There was a problem hiding this comment.
that's where the new CompositeMetadata comes in, with hasNext / decodeNext. alternatively the flyweight method returns an empty array when all was decoded
There was a problem hiding this comment.
ok I see - you mutate the read index. That doesn't work like any of the other frames/payloads in RSocket. They all reset there read indexes are finished- they change the state of the ByteBuf to back where it was. We've found it's a lot easier to deal with ByteBufs that way, and update the read indexes as a side-effect makes the code harder to debug.
There was a problem hiding this comment.
does that apply to slices? decodeMime[Type|Id]FromMimeBuffer both work from a slice of the original whole metadata buffer, so that skipBytes(1) in decodeMimeTypeFromMimeBuffer doesn't move the readerIndex of the whole composite metadata...
That said, the main decoding method does indeed move the full metadata buffer's readerIndex(). I thought it was unavoidable since the approach was to decode a subset of the whole buffer, without state keeping, and the length of the slices (metaheader and metacontent) can't be known without decoding.
But maybe that state can be externalized, as a startFromIndex parameter to decodeMimeAndContentBuffers? It would be a burden put on the user to keep track of the next startFromIndex to read from, though... She would have to do something like (see below for comment on edit)index = index + slices[0].readableBytes() + slices[1].readableBytes() + 1...
This can of course be done inside the CompositeMetadata "iterator", but for low level decoding it can be more work.
There was a problem hiding this comment.
note The best way to compute the next entry index is to provide a flyweight util method, since the decoded slices are not necessarily covering contiguous portions of the orignal full metadata buffer (namely currently they don't include the 3 bytes content length)
There's an CompositeMetadata composite = new CompositeMetadata(fullByteBuf);
while(composite.hasNext()) {
composite.decodeNext();
String mimeType = composite.getCurrentMimeType(); //returns null if reserved compressed id
byte mimeId = composite.getCurrentMimeId(); //returns -1 if not compressed
ByteBuf metadata = composite.getCurrentMetadata();
//do something with each element, like decode the actual metadata content
if (WellKnownMimeType.APPLICATION_JSON.getIdentifier() == mimeId) {
addDecodedMetadata(decodeJsonMetadata(metadata));
}
} |
|
@robertroeser what do you think about |
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
…benchmark to validate perf increase Signed-off-by: Simon Baslé <sbasle@pivotal.io>
- avoid the use of a CompositeByteBuf - length can be safely predicted due to requirement that custom mime type be ASCII only - still using UTF8 writing and ByteBufUtil.isText(ASCII) to detect non-ascii text as: - writeAscii would not reject non-ascii chars but replace with `?` - ISO-8859 chars (eg. Latin-1) could be considered valid when only checking the number of written bytes - use of ByteBufUtil.writeUtf8 to simplify encoding the mime into the preallocated buffer - release the buffer if there is an encoding exception Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
The CompositeMetadata wraps a ByteBuf and exposes a hasNext/decodeNext API (reminiscent of the Iterator API) as a facade over the flyweight's methods. Each round decodeNext() is correctly invoked, the CompositeMetadata state is updated and the getters can be used to retrieve decoded entry components. Signed-off-by: Simon Baslé <sbasle@pivotal.io>
This is a qol method that will first check if the String passed can be mapped to a WellKnownMimeType (and thus compressed to a 1 byte representation). Signed-off-by: Simon Baslé <sbasle@pivotal.io>
|
@linux-china @rstoyanchev @robertroeser the two changes discussed in my last comments have now been implemented. |
|
looks good - probably last thing is to switch the mime-types to hex numbers to match @nebhale's pull request - rsocket/rsocket#270 |
|
@robertroeser I've been working with @simonbasle and @rwinch on the usage side of the |
This implies that the index from which to decode and slice the next entry MUST be provided by the user. To that end, we provide a method to compute the next entry's index, given the pair of ByteBuf slices returned by decodeMimeAndContentBuffers. Also renamed that method to decodeMimeAndContentBufferSlices, to make it more obvious that it produces slices (readerIndex impact and slices nature are mentioned in the javadoc). CompositeMetadata now keeps the nextEntryIndex as state and uses that for hasNext / decodeNext. Signed-off-by: Simon Baslé <sbasle@pivotal.io>
Previously, the implementation of CompositeMetadata resulted in a mutable type that didn't fit in with either imperative (for) or reactive (fromIterable) iteration strategies. This change updates the type to implement Iterable, and return an Iterator that lazily traverses the ByteBuf. There are also some improvements to the Flyweight in order to support this iteration style. Signed-off-by: Ben Hale <bhale@pivotal.io>
ffa3fb2 to
5d76e10
Compare
Signed-off-by: Simon Baslé <sbasle@pivotal.io>
This PR intends to cover the basics of the composite metadata and well known mime types spec extensions, currently incubating and originally defined in rsocket/rsocket#254
Essentially, the mime types are enumerated, while the composite metadata encoding and decoding is implemented as a package-private flyweight, all under the
metadatapackage.The
CompositeMetadataexposes the composite components, although the iteration / access API can probably be improved.It also exposes methods to encode individual metadata components into a
ByteBuf, as well as to decode aCompositeMetadata. The flyweightdecodeNextmethod could also be made public as an even lower-level API.Open questions and improvement points:
decodeNextmethod be public API?WellKnownMimeTypelookups should probably avoid throwing exceptions?CompositeMetadata#get*accessors throw exceptions too?should we introduce a more generic class instead of=> matter for another issueEntry, something like Micrometer'sTagandTags, but with a generic value:Keyed<T>would have aStringkey and a<T>value,ByteBuffor the composite metadata.