前端算法的学习
安装 nodejs v14+ ,安装 npm 或 yarn
- 安装依赖:
npm install或yarn install - 本地运行:
npm run dev或yarn dev,浏览器访问http://localhost:3000/
- 将数组旋转k步,如
[1,2,3,4,5,6,7]旋转3步得到[4,5,6,7,1,2,3]- 代码:array-rotate
- 判断字符串中括号匹配,如
{4}(2)[3],{d[sf(d)gd]f}是匹配的,{a(d[d)f]}s是不匹配的- 代码:match-bracket
- 重点:栈是使用,先进后出,和收盘子洗盘子一样,先收的盘子最后洗(左括号压栈,右括号判断出栈)
- 两个栈实现一个队列
- 代码:queue-with-two-stacks
- 使用一个类来编写,先进先出,两个栈倒腾
- 反转单向链表
- reverse-link-list
- 重点:使用数组创建链表结构,链表是查询慢增删快的有序数据结构
- 重点:使用三个指针同时平移,防止数据丢失

- 单向链表实现队列
- queue-with-link-list
- 重点:单独记录长度length,因为遍历需要O(n)
- 重点:从尾部添加,从头部删除,因为单向链表没有prev,从头部添加可以,但是从尾部删除,不知道尾部的上一个是谁
- 二分查找
- 代码:match-bracket
- 时间复杂度O(logn)
- 循环的速度会比递归的速度快,虽然它们都是相同的时间复杂度,但是递归是调用多次函数,每次调用开销都会大一点,而循环只调用了一次函数
- 有序数组查找两数之和,如在数组
[1,2,4,7,11,15.16]中找到两个数之和为22的,即[7,15]- 代码:two-numbers-sum
- 重点:嵌套循环时间复杂度O(n^2),双指针时间复杂度O(n)
- 理解:为什么可以双指针,例如先将
1和16相加,结果小于目标值22,此时如果希望相加的值变大一点点,只需要左侧往中间靠拢2和16相加,还是不行,证明还是太小了,左侧还要往里靠近一点,等到7和16的时候,大于目标值,这时候要小一点,需要右侧往里靠拢7和15
- 求斐波那契数列第n项的值
- 代码:fibonacci
- 重点:递归的时间复杂度为O(2^n),性能最差,当n达到50,大多数电脑就卡死了,循环的时间复杂度为O(n),一层循环
- 理解:使用循环,底层为二叉树思想,核心观念:动态规划,将大问题拆成小问题,向下逐级拆解,例如斐波那契数列[0,1,1,2,3,5,8,13,21...]第7项为
13,那f(7) = 13;那13怎么来的呢,其实f(7)=f(6)+f(5);而f(6)=f(5)+f(4),以此类推,f(n)=f(n-1)+f(n-2);这就将f(7)最后拆解成很多个f(1)+f(0);这就是动态规划;而这拆解成子问题的形象化如下图,是不是很像一个二叉树 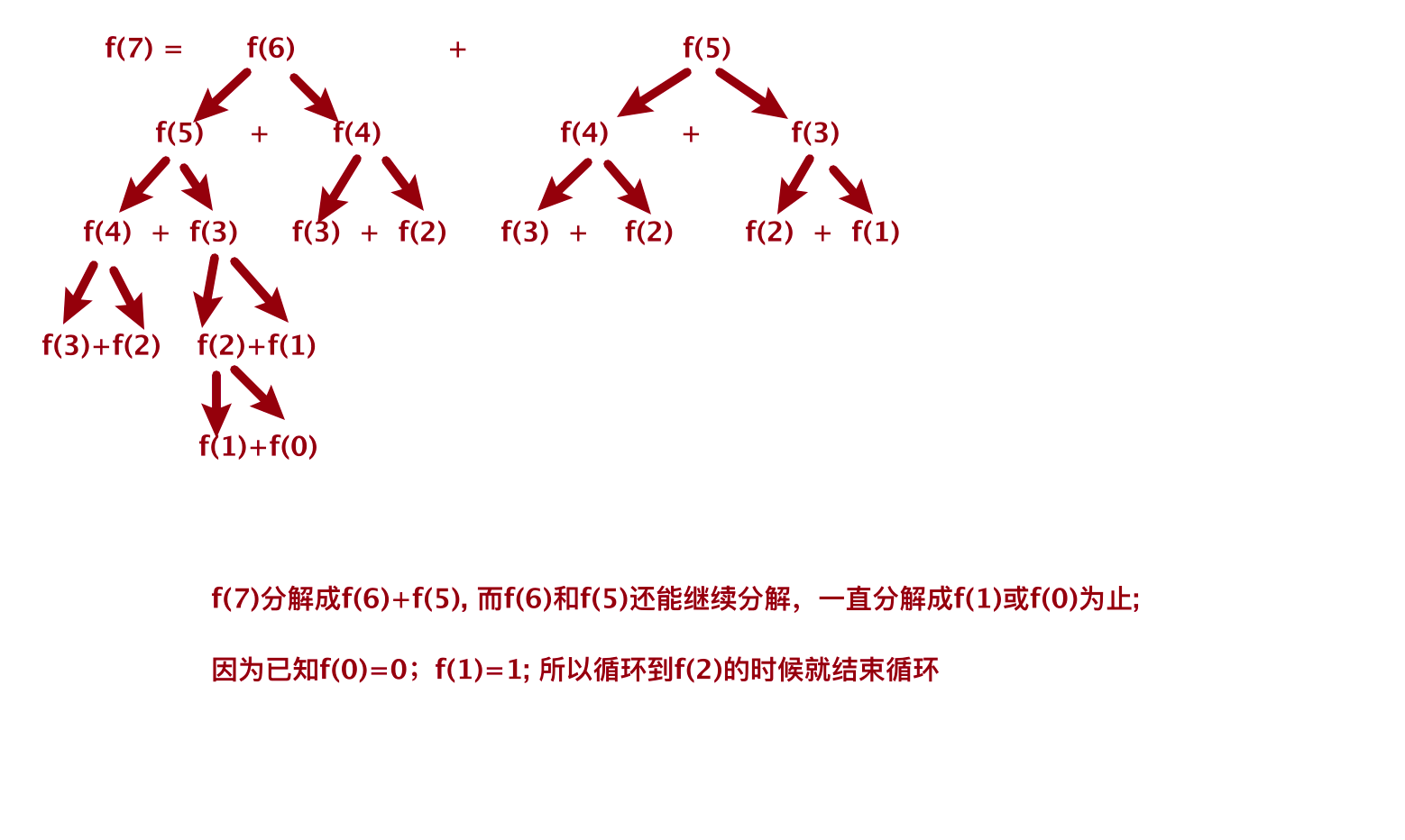
- 将数组中的0移动至数组末尾
- 代码:move-zero
- 重点: 使用循环和splice时间复杂度为O(n^2),不可用,需要使用双指针的方式
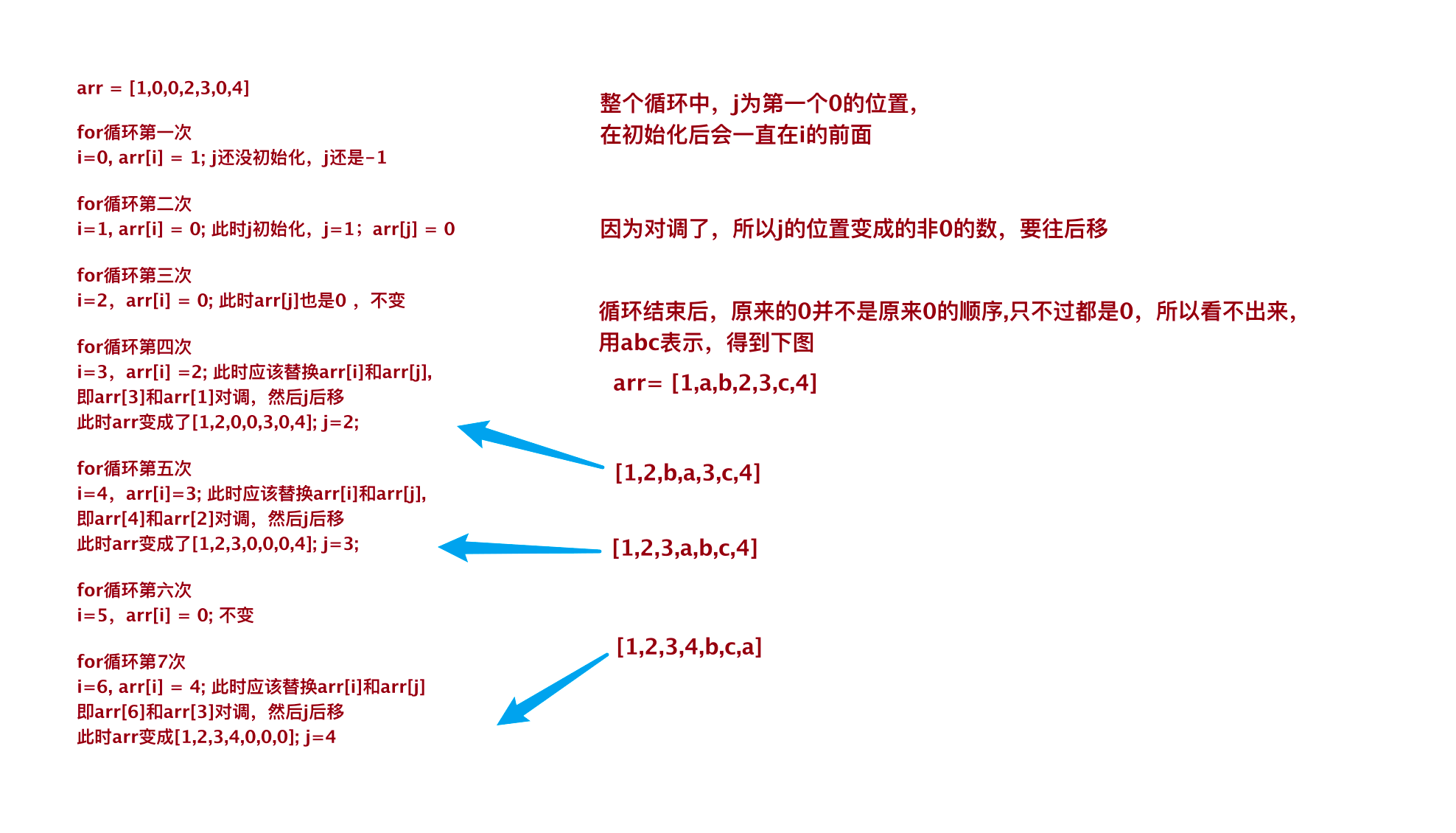
- 理解: 双指针方式,定义索引j记录数组的第一个0的索引(循环过程始终记录第一个0的位置),循环过程中遇到不是0的就与之替换,然后索引j后移
- 理解:在循环过程中,除非j还没初始化,否则j始终会在i的前面,而且j和i之间间隔有多少个0也不一定
- 求字符串中连续出现的最多的字符和次数,如
aabbbccccdde中,c出现最多为4- 代码:continuous-char
- 重点:嵌套循环和双指针都是O(n),因为嵌套循环使用了跳步,跳步演示参考(jumpFn循环)
- 理解:循环中,无论嵌套循环还是双指针,结尾都要-1,理由是循环走完,会+1,这是为了让指针对应;嵌套循环-1是为了下次进来是真正的下一个,双指针-1是为了让i能一开始和j相等,保证length至少=1。
- 快速排序
- 代码:quick-sort
- 重点:常规代码,使用二分法,时间复杂度O(nlogn)
- 理解:无论用splice还是slice,时间复杂度都是O(nlogn),差不多,原因是本身时间复杂度O(nlogn)就比较大,所以splice的影响被覆盖了,同时是二分法,splice的影响被二次摊薄了。
- 寻找1到max之间的回文数字【注:回文数字是具有对称性的数字,如
1``22``121``2332``34543】- 代码:palindrome-number
- 重点:有三种方法,三种方法都是一次遍历找到对称的数字进行比较,不同之处在于定义对称数时的方式
- 重点:数组的方法性能最差,因为数组要操作
reverse等是有性能问题的,字符串和数字的对比差不多,数字的方法最高效,因为计算机计算数字最直接 - 附:求翻转数的方法
getReverseNumber,不断将原数字的个位数拼接在自己后面(自己乘于10后加个位数),不断将原数字的个位数剔除(自己除于10后保留整数)
- 在10万量级的单词数组中匹配输入的单词前缀
- 解释:例如输入
app,apple都能匹配上,因为有这个开头的单词,但是输入aaaaa就不能匹配,因为没有单词以aaaaa开头 - 方法:将10万量级的单词数组提前格式化为哈希表(对象),通过哈希表的key查询,时间复杂度为O(n),因为单词有固定格式,所以可以格式化为以下格式,时间复杂度为O(m),m为单词长度,最长也就是十几二十的长度,而如果遍历,至少O(n)起步,n是10万的量级
- 注:哈希表是逻辑结构,js中使用物理结构 (Object | Map) 可以实现,其他语言有其他语言的物理结构来实现(如:c语言的
结构体,java的HashMap)
const arr = ['app','apple','boy'] // 很多很多,有10万个单词 // 格式化为哈希表 const obj = { a: { p: { p: { value: 'app', l:{ e:{ value:'apple' } } } } }, b: { o: { y: { value: 'boy' } } } } const isWord = obj.a.p.p.l.e // {value: 'apple'}
- 解释:例如输入
- 千分位格式化
- 代码:thousands-format
- 重点:可以用正则表达式,数组reverse后遍历,字符串遍历,性能最好是字符串
- 切换字符串中字母大小写
- 代码:switch-letter-case
- 重点:无论怎样都是要循环,可以用正则表达式判断当前字符串是不是字母,是大写字母还是小写字母,也可以用
ASCII码来判断是否是大写字母或者小写字母,判断结束后再通过toUpperCase或者toLowerCase切换大小写,使用ASCII码的性能会更好
- js计算浮点数的问题
- 代码:float-fn
- 重点:浮点数的计算是先转换为二进制,但是双精度的只能保留52位,所以被截断了,相加后再转换为10进制就会有一堆小数点,2.445使用第三方库
Mathjs或者Bignumberjs等
- 运行
npx jest src/路径查看单元测试情况 - 判断数组和对象使用
toEqual - 判断普通类型使用
toBe - 判断是否是null
toBeNull