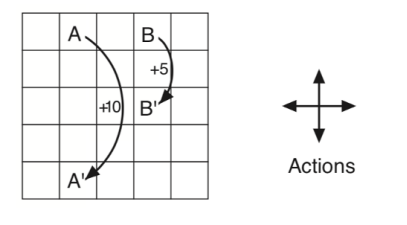
In it, for all the states (cells in the grid), each one of the actions (north, south, east, and west) is chosen with probability ¼. The agent then moves with probability 1 to the chosen direction. While moving, if the agent hits a wall, it cannot move and it receives a reward of -1; if moving to a cell in the grid, the reward is 0.; if it reaches cell A (1,2), it moves to cell A’ (5,2) and receives a reward +10; and, if it reaches cell B (1,4) it moves to cell B’ (3,4) and receives a reward +5.
** A linear solver to solve the system Ax=b.
** A dynamic programming approach (policy iteration or value iteration).