Setting sample_weight in Poisson regression example #18059
Description
Describe the issue linked to the documentation
In the Poisson regression and non-normal loss example, we set the sample weight to the exposure, when we divided the count data by the exposure. We had this discussion regarding this here: https://github.com/scikit-learn/scikit-learn/pull/14300/files#r386066958
When looking at the reference paper (page 16) the example was based on, it handles this by using an offset:
glm(formula = ClaimNb ~ VehPowerGLM + VehAgeGLM + DrivAgeGLM +
BonusMalusGLM + VehBrand + VehGas + DensityGLM + Region +
AreaGLM, family = poisson(), data = learn, offset = log(Exposure))Which I think is the same as:
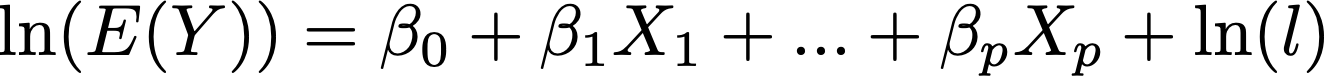
where l is the exposure. In our example, the target has been already divided by the exposure. If we want to match the narrative by the paper, is the sample_weight required?
Edit: I guess we are treating 4 event in 8 years to have a higher weight than 1 event in 2 years.