Explain the differences between Java and JavaScript. You should include both topics related to the fact that Java is a compiled language and JavaScript a scripted language, and general differences in language features
You should include both topics related to the fact that Java is a compiled language and JavaScript a scripted language, and general differences in language features.
| Java | JavaScript | |
|---|---|---|
| Compiled vs Interpreted | Java is a compiled programming language. Java is compiled into bytecode and run on a virtual machine |
JavaScript is an interpreted scripting language. JavaScript can be interpreted directly by a browser in the syntax it is written. |
| Static vs Dynamic Type Checking | Java uses static type checking, where the type of a variable is checked at compile-time. The programmer must specify the type (integer, double, string, etc.) of any variable they create. | JavaScript, like most scripting languages, uses dynamic typing, where type safety is verified at runtime. It is not required for a programmer to specify the type of any variable they create. |
| Concurrency | Java makes use of multiple threads to perform tasks in parallel. | JavaScript, particularly as it exists as Node.js in server-side applications, handles concurrency on one main thread of execution via a queue system called the event loop, and a forking system called Node Clustering. |
| Class Based vs Prototype Based | Java follows class based inheritance—a top down, hierarchical, class-based relationship whereby properties are defined in a class and inherited by an instance of that class. | In JavaScript, inheritance is prototypal—all objects can inherit directly from other objects. Hierarchy is accomplished in JavaScript by assigning an object as a prototype with a constructor function. |
The "use strict" directive was new in ECMAScript version 5. It is not a statement, but a literal expression, ignored by earlier versions of JavaScript. The purpose of "use strict" is to indicate that the code should be executed in "strict mode". With strict mode, you can not, for example, use undeclared variables.
"Use strict" and linters are tools to protect us form ourselves. They warn us when our code contains a syntax error, and tells us if the variable we defined or assigned a value isn't being used. This improves the quality of our code, and may save time we would have use on debuging.
Hoisting means lifting up. A var declaration is lifted to the top of its scope.
console.log(x)
var x = 10is equivalent with
var x
console.log(x)
x = 10the declaration of x is hoisted not the assignment.
Like var declaration, a function is also hoisted
this in JavaScript typically refers to the function it is called in, while in Java it refers to the class.
function Car(make,model) {
this.make = make;
this.model = model;
this.show = function(){setTimeout(function(){ //This function gets it's own "this"
console.log(this.make + ", " + this.model);
},0)};
}
var car = new Car("Volvo","V70");
car.show();output
undefined, undefined
if a function is defined as a arrow function it does not get its own this
function Car(make,model) {
this.make = make;
this.model = model;
this.show = function(){setTimeout(()=>{ //This function doesn't gets it's own "this"
console.log(this.make + ", " + this.model);
},0)};
}
var car = new Car("Volvo","V70");
car.show();output
Volvo, V70
A closure is an inner function that has access to the outer (enclosing) function's variables—scope chain. The closure has three scope chains: it has access to its own scope (variables defined between its curly brackets), it has access to the outer function's variables, and it has access to the global variables.
The inner function has access not only to the outer function’s variables, but also to the outer function’s parameters. Note that the inner function cannot call the outer function’s arguments object, however, even though it can call the outer function’s parameters directly.
function showName (firstName, lastName) {
var nameIntro = "Your name is ";
// this inner function has access to the outer function's variables, including the parameter
function makeFullName () {
return nameIntro + firstName + " " + lastName;
}
return makeFullName ();
}
showName ("Michael", "Jackson");output
Your name is Michael Jackson
The Module pattern was originally defined as a way to provide both private and public encapsulation for classes in conventional software engineering.
In JavaScript, the Module pattern is used to further emulate the concept of classes in such a way that we're able to include both public/private methods and variables inside a single object, thus shielding particular parts from the global scope. What this results in is a reduction in the likelihood of our function names conflicting with other functions defined in additional scripts on the page.
var modularpattern = (function() {
// your module code goes here
var sum = 0 ;
return {
add:function() {
sum = sum + 1;
return sum;
},
reset:function() {
return sum = 0;
}
}
}());
console.log(modularpattern.add())
console.log(modularpattern.add())
console.log(modularpattern.reset())output
1
2
0
(function(){/*do stuff*/})()const names = ['Lars', 'Jan', 'Peter', 'Bo', 'Frederik']
names.prototype.myMap = function(callback){
let arr = []
for(let i = 0; i < this.length; i++){
arr.push(callback(this[i]))
}
return arr
}function myFilter(callback){
let arr = []
for(let i = 0; i < this.length; i++){
if(callback(this[i])){
arr.push(this[i])
}
}
return arr
}Array.prototype.map(): The map() method creates a new array with the results of calling a provided function on every element in the calling array.
const numbers = [2, 3, 4, 5]
const mappedNumbers = numbers.map((e) => e * 2)
console.log(mappedNumbers);output
[4, 6, 8, 10]
Array.prototype.filter(): The filter() method creates a new array with all elements that pass the test implemented by the provided function.
const names = ['Lars', 'Jan', 'Peter', 'Bo', 'Frederik']
const filteredNames = names.filter(name => name.length <= 3)
console.log(filteredNames)output
["Jan", "Bo"]
Array.prototype.reduce(): The reduce() method executes a reducer function (that you provide) on each member of the array resulting in a single output value.
The reducer function takes four arguments:
- Accumulator (acc)
- Current Value (cur)
- Current Index (idx)
- Source Array (src)
Your reducer function's returned value is assigned to the accumulator, whose value is remembered across each iteration throughout the array and ultimately becomes the final, single resulting value.
const numbers = [2, 3, 4, 5]
const reducer = (acc, cur, idx, src) => accumulator + currentValue)
console.log(numbers.reduce(reducer);output
14

Explain generally about node.js, when it “makes sense” and npm, and how it “fits” into the node echo system
Node.js is a platform built on Chrome's JavaScript runtime for easily building fast, scalable network applications.
It uses an event-driven, non-blocking I/O model that makes it lightweight and efficient, perfect for data-intensive real-time applications that run across distributed devices.
Node vs Java - similarities
- Runs on a Virtual Machine
- Runs on multiple platforms
- You must include packages before you can use them
- You must obtain packages not included in the base installation before you can use them
npm (short for Node.js package manager) is a package manager for the JavaScript programming language. It is the default package manager for the JavaScript runtime environment Node.js. It consists of a command line client, also called npm, and an online database of public and paid-for private packages, called the npm registry. The registry is accessed via the client, and the available packages can be browsed and searched via the npm website.
Many modules is designed to do one thing, the Node echo system encourages to use such modules instead of one module that does everything
Node.js is a single-threaded application, but it can support concurrency via the concept of event and callbacks. Every API of Node.js is asynchronous and being single-threaded, they use async function calls to maintain concurrency. Node uses observer pattern. Node thread keeps an event loop and whenever a task gets completed, it fires the corresponding event which signals the event-listener function to execute.
Node.js uses events heavily and it is also one of the reasons why Node.js is pretty fast compared to other similar technologies. As soon as Node starts its server, it simply initiates its variables, declares functions and then simply waits for the event to occur.
In an event-driven application, there is generally a main loop that listens for events, and then triggers a callback function when one of those events is detected.
Although events look quite similar to callbacks, the difference lies in the fact that callback functions are called when an asynchronous function returns its result, whereas event handling works on the observer pattern. The functions that listen to events act as Observers. Whenever an event gets fired, its listener function starts executing.
module.exports.makeCounter = function(){
let privateCounter = 0
function changeBy(val){
privateCounter += val
}
return {
increment: function(){
changeBy(1)
},
decrement: function(){
changeBy(-1)
},
value: function(){
return privateCounter
}
}
}Using Node.js as your server technology gives your team a great boost that comes from using the same language on both the front end and the back end. This, means that your team is more efficient and cross-functional, which, in turn, leads to lower development costs. In addition to that, it’s worth mentioning that JavaScript is the most popular programming language, so your application’s codebase will be easier to understand for more engineers. You can also reuse and share the code between the frontend and the backend parts of your application, which speeds up the development process. On top of that, the Node.js community is constantly growing – the number of StackOverflow questions is steadily increasing, so the knowledge base for the technology is widely available. The fact that the whole Node.js technology stack is open-source and free is also great news. Finally, Node offers a great package manager, npm, and the amount of available open-source tools in npm’s registry is massive and growing fast.
Explain the difference between “Debug outputs” and application logging. What’s wrong with console.log(..) statements in our backend-code.
One of the biggest disadvantages is that you can’t toggle logging on and off, not out of the box at least. You could wrap console and extend it to do this, but this is code you’ll have to write, and likely code that will have to overwrite the built-in console functions.
You might want to turn off logging if you’re in a development environment vs a production environment. Or even if you’re just testing locally on your machine or VM, if you’ve got a ton of logging for debug purposes or otherwise, that can really clutter up your console and you might want to just test with logging disabled for a bit.
Another disadvantage of console comes when you need to know log levels.
While it already has what appear to be log levels (see below), these are really just functions that route to stdout and stderr without providing true log levels.
console.log() --> writes to stdout
console.debug() --> writes to stdout
console.info() --> writes to stdout
console.error() --> writes to stderr
console.warn() --> writes to stderrSo in the Node console, you won’t be able to tell these logs apart unless you prepend a string with the level to the logs.
Popular Node logging frameworks like Winston and Bunyan allow for log levels, easy toggling logs on and off based on environment, and sometimes (in the case of Winston) support for custom log levels that you as a developer can define.
Logging frameworks will also (generally) support writing to more than just stdout/stderr
Logging using Winston:
const app = express()
const winston = require('winston')
const consoleTransport = new winston.transports.Console()
const myWinstonOptions = {
transports: [consoleTransport]
}
const logger = new winston.createLogger(myWinstonOptions)
function logRequest(req, res, next) {
logger.info(req.url)
next()
}
app.use(logRequest)
function logError(err, req, res, next) {
logger.error(err)
next()
}
app.use(logError)The debug module has a great namespace feature that allows you to enable or disable debug functions in groups. It is very simple–you separate namespaces by colons, like this:
debug('app:meta')('config loaded')
debug('app:database')('querying db...');
debug('app:database')('got results!', results);Enable debug functions in Node by passing the process name via the DEBUG environment variable. The following would enable the database debug function but not meta:
$ DEBUG='app:database' node app.js
To enable both, list both names, separated by commas:
$ DEBUG='app:database,app:meta' node app.js
Alternately, use the asterisk wildcard character (*) to enable any debugger in that namespace. For example, the following enables any debug function whose name starts with “app:":
$ DEBUG='app:*' node app.js
You can get as granular as you want with debug namespaces…
debug('myapp:thirdparty:identica:auth')('success!');
debug('myapp:thirdparty:twitter:auth')('success!');
Explain Pros & Cons in using Node.js + Express to implement your Backend compared to a strategy using, for example, Java/JAX-RS/Tomcat
Using Node.js for backend, you automatically get all the pros of full stack JavaScript development, such as:
- better efficiency and overall developer productivity
- code sharing and reuse
- speed and performance
- easy knowledge sharing within a team
- huge number of free tools
Consequently, your team is a lot more flexible, the development is less time-consuming and as a result you get fast and reliable software.
Despite a common belief, with full stack web development you are in no way limited to the traditional MEAN (MongoDB, Express.js, AngularJS, and Node.js) stack. The only must-have in this case is Node.js (there is no alternative in JavaScript for backend programming). The rest of the technologies within this stack are optional and may be replaced with some other tools providing similar functionality (read about the alternatives in our separate article).
When using a common language for both client- and server-side, synchronization happens fast, which is especially helpful for event-based, real-time applications. Thanks to its asynchronous, non-blocking, single-threaded nature, Node.js is a popular choice for online gaming, chats, video conferences, or any solution that requires constantly updated data.
Not only does app performance benefit from Node.js’ lightness, the team’s productivity will increase as well. Developers trained in frontend JavaScript can start programming the server side with the minimum learning curve. With the same language on both sides, you can reuse code on front-end and back-end by wrapping it into modules and creating a new level of abstraction.
Since it’s a lightweight technology tool, using Node.js for microservices architecture is a great choice. This architectural style is best described by Martin Fowler and James Lewis as “an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.”
Accordingly, breaking the application logic into smaller modules, microservices, instead of creating a single, large monolithic core, you enable better flexibility and lay the groundwork for further growth. As a result, it is much easier to add more microservices on top of the existing ones than to integrate additional features with the basic app functionality.
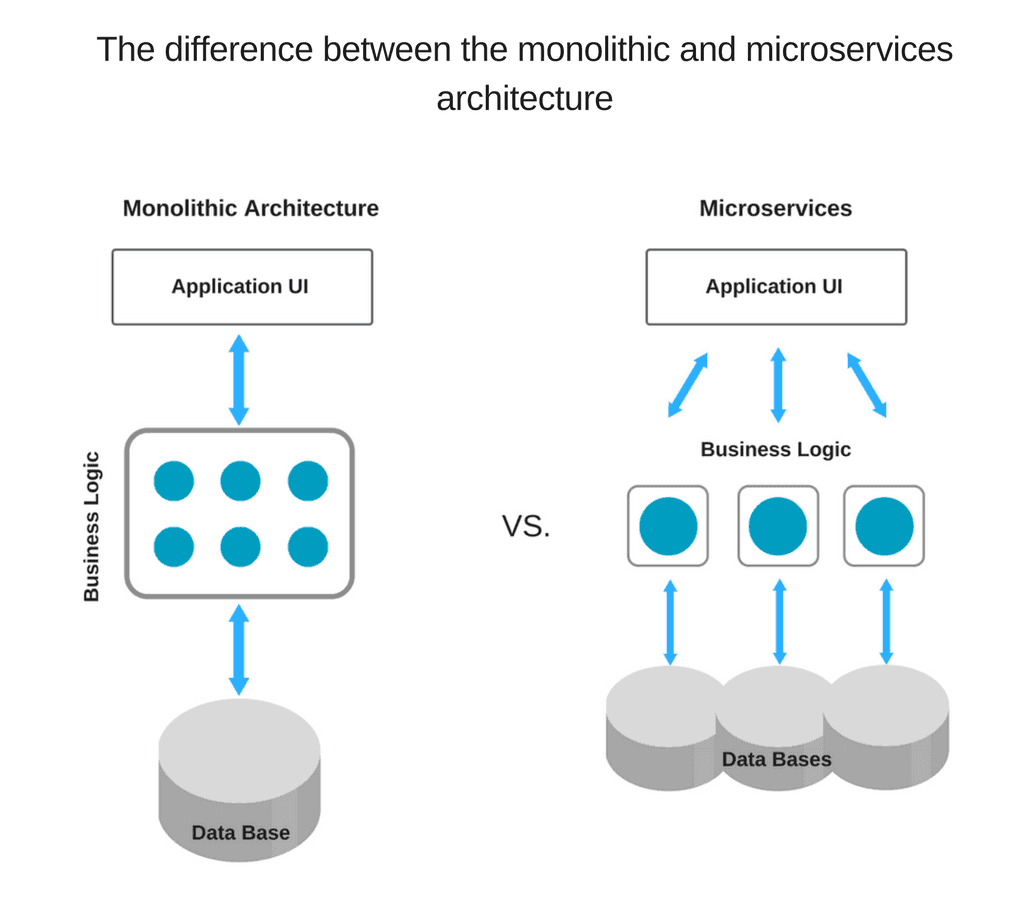
With each microservice communicating with the database directly through streams, such architecture allows for better performance and speed of application.
One word – npm, a default Node.js package manager, it also serves as a marketplace for open source JavaScript tools, which plays an important role in the advance of this technology. With about 350,000 tools available in the npm registry as of now, and over 10,000 new ones being published every week, the Node.js ecosystem is quite rich.
With such a vast variety of free tools accessible in a few clicks, there is a huge potential for the use of Node.js. At the same time, open source software enjoys a growing popularity as it allows you to build new solutions reducing the overall costs of development and time to market.
Two of the most argued about aspects of Node.js programming are its insufficiency with heavy computations and the so-called “callback hell”. Before we get into too many details, let’s figure out what’s what.
As we know, JavaScript (and, as a result, Node.js) is asynchronous by nature and has a non-blocking I/O (input/output) model. This means, it can process several simple tasks (for example, read/write database queries) queued in the background without blocking the main thread and do so quickly.
At the same time, Node.js is a single-threaded environment, which is often considered a serious drawback of the technology. Indeed, in some cases, a CPU-bound task (number crunching, various calculations) can block the event loop resulting in seconds of delay for all Node.js website users.
This represents a serious issue. That is why, to avoid it, it is recommended not to use Node.js with computation-heavy systems.
Due to its asynchronous nature, Node.js relies heavily on callbacks, the functions that run after each task in the queue is finished. Keeping a number of queued tasks in the background, each with its callback, might result in the so-called callback hell, which directly impacts the quality of code. Simply put, it’s a “situation where callbacks are nested within other callbacks several levels deep, potentially making it difficult to understand and maintain the code.”
Yet, this is often considered a sign of poor coding standards and lack of experience with JavaScript and Node.js in particular.
Although, the core Node.js modules are quite stable and can be considered mature, there are many tools in the npm registry which are either of poor quality or not properly documented/tested. Moreover, the registry itself isn’t structured well enough to offer the tools based on their rating or quality. Hence it might be difficult to find the best solution for your purposes without knowing what to look for.
The fact that the Node.js ecosystem is mostly open source, has its impact as well. While the quality of the core Node.js technology is supervised by Joyent and other major contributors, the rest of the tools might lack the quality and high coding standards set by global organizations.
Obviously, with all the listed Node.js advantages and disadvantages, the technology is no silver bullet. But neither is Java, .Net framework or PHP. Yet, there are specific cases where each one of the technologies perform best. For Node.js, these are real-time applications with intense I/O, requiring speed and scalability.
This might be social networks, gaming apps, live chats or forums as well as stock exchange software or ad servers, where speed is everything. Fast and scalable, Node.js is the technology of choice for data-intensive, real-time IoT devices and applications.
Due to its non-blocking architecture, Node.js works well for encoding and broadcasting video and audio, uploading multiple files, and data streaming.
Recently, Node.js has been actively used in enterprise-level software. While there is still much argument about this, many large companies and global organizations, such as NASA, have already adopted Node.js. And the enterprise Node.js ecosystem continues to mature.
Yet, you can’t choose a language or tool just because another super-successful company did. It makes no sense to look at the others when your product and your business is at stake. You need to get your priorities straight and clearly identify the benefits the technology will give you, without forgetting about the hidden drawbacks.
Node.js uses a Single Threaded Non-blocking strategy to handle asynchronous task. Explain strategies to implement a Node.js based server architecture that still could take advantage of a multi-core Server.
Node JS follows Single Threaded with Event Loop Model. Node JS Processing model mainly based on Javascript Event based model with Javascript callback mechanism.
As Node JS follows this architecture, it can handle more and more concurrent client requests very easily.
The main heart of Node JS Processing model is “Event Loop”. If we understand this, then it is very easy to understand the Node JS Internals.
- Clients Send request to Web Server.
- Node JS Web Server internally maintains a Limited Thread pool to provide services to the Client Requests.
- Node JS Web Server receives those requests and places them into a Queue. It is known as “Event Queue”.
- Node JS Web Server internally has a Component, known as “Event Loop”. Why it got this name is that it uses indefinite loop to receive requests and process them.
- Event Loop uses Single Thread only. It is main heart of Node JS Platform Processing Model.
- Even Loop checks any Client Request is placed in Event Queue. If no, then wait for incoming requests for indefinitely.
- If yes, then pick up one Client Request from Event Queue
- Starts process that Client Request
- If that Client Request Does Not requires any Blocking IO
- Operations, then process everything, prepare response and send it back to client.
- If that Client Request requires some Blocking IO Operations like interacting with Database, File System, External Services then it will follow different approach
- Checks Threads availability from Internal Thread Pool
- Picks up one Thread and assign this Client Request to that thread.
- That Thread is responsible for taking that request, process it, perform Blocking IO operations, prepare response and send it back to the Event Loop
- Event Loop in turn, sends that Response to the respective Client.

Explain briefly how to deploy a Node/Express application including how to solve the following deployment problems:
Deploying Node.js app on digital ocean
Use PM2
Use PM2
A single instance of Node.js runs in a single thread. To take advantage of multi-core systems, the user will sometimes want to launch a cluster of Node.js processes to handle the load.
The cluster module allows easy creation of child processes that all share server ports.
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
// In this case it is an HTTP server
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}Can be done by implementing a reverse proxy i.e. nginx
A middleware with no mount path will be executed every time the app recieves a request
var app = express()
app.use(function (req, res, next) {
console.log('Time:', Date.now())
next()
})A middleware function mounted on a path. The function is executed for any type of HTTP request on the path.
app.use('/user/:id', function (req, res, next) {
console.log('Request Type:', req.method)
next()
})A middleware function mounted on a path. The function is executed for HTTP requests with method GET on the path.
app.get('/user/:id', function (req, res, next) {
console.log('ID:', req.params.id)
next()
})Error-handling middleware
app.use(function (err, req, res, next) {
console.error(err.stack)
res.status(500).send('Something broke!')
})Explain, using relevant examples, how to implement sessions and the legal implications of doing this
var cookieSession = require("cookie-session");
app.use(
cookieSession({
name: "session",
secret: "I_should_never_be_visible_in_code",
// Cookie Options
maxAge: 30 * 60 * 1000 // 30 minutes
})
);Recital 30 of the GDPR states:
Natural persons may be associated with online identifiers provided by their devices, applications, tools and protocols, such as internet protocol addresses, cookie identifiers or other identifiers such as radio frequency identification tags.
This may leave traces which, in particular when combined with unique identifiers and other information received by the servers, may be used to create profiles of the natural persons and identify them.
In short: when cookies can identify an individual via their device, it is considered personal data.
Not complying to the laws will result in severe punishment.
Compare the express strategy toward (server side) templating with the one you used with Java on second semester.
Both JSP and EJS uses tags to embed Java and JavaScript respectively in HTML code
JSP tags:
<%!Variable declaration or method definition%><%=Java valid expression%><%Pure Java code%>
EJS tags:
<%'Scriptlet' tag, for control-flow, no output<%_‘Whitespace Slurping’ Scriptlet tag, strips all whitespace before it<%=Outputs the value into the template (HTML escaped)<%-Outputs the unescaped value into the template<%#Comment tag, no execution, no output<%%Outputs a literal '<%'%>Plain ending tag-%>Trim-mode ('newline slurp') tag, trims following newline_%>‘Whitespace Slurping’ ending tag, removes all whitespace after it
Demonstrate a simple Server Side Rendering example using a technology of your own choice (pug, EJS, ..).
Setting up route
var express = require("express");
var router = express.Router();
router.get("/joke", function(req, res, next) {
let counter = req.session.jokeCounter;
counter++;
req.session.jokeCounter = counter;
res.render("randomJoke", { title: "Joke", joke: jokes.getRandomJoke() });
});Rendering the site
<!DOCTYPE html>
<html>
<head>
<title><%= title %></title>
<link rel='stylesheet' href='/stylesheets/style.css' />
</head>
<body>
<a href='/'>Home Page</a>
<p><%= joke %></p>
</body>
</html>Explain, using relevant examples, your strategy for implementing a REST-API with Node/Express and show how you can "test" all the four CRUD operations programmatically using, for example, the Request package.
Implementing a REST-API with Express
var express = require("express");
var router = express.Router();
var jokes = require("../model/jokes");
/* GET home page. */
router.get("/", function(req, res, next) {
res.render("index", { title: "Express", userName: req.session.userName });
});
router.get("/login", function(req, res, next) {
res.render("login", { title: "Login" });
});
router.post("/login", function(req, res, next) {
res.render("index", { title: "Express" });
});
router.get("/joke", function(req, res, next) {
let counter = req.session.jokeCounter;
counter++;
req.session.jokeCounter = counter;
res.render("randomJoke", { title: "Joke", joke: jokes.getRandomJoke() });
});
router.get("/jokes", function(req, res, next) {
let counter = req.session.jokesCounter;
counter++;
req.session.jokesCounter = counter;
res.render("allJokes", { title: "Jokes", jokes: jokes.getAllJokes() });
});
router.get("/addjoke", function(req, res, next) {
res.render("addJoke", { title: "Add Joke" });
});
router.post("/storejoke", function(req, res, next) {
let counter = req.session.storeJokeCounter;
counter++;
req.session.storeJokeCounter = counter;
const joke = req.body.joke;
jokes.addJoke(joke);
res.render("addJoke", { title: "Add Joke" });
});
module.exports = router;Testing the REST-API
const expect = require("chai").expect;
const http = require('http');
const app = require('../app');
const fetch = require("node-fetch");
const TEST_PORT = 3344;
const URL = `http://localhost:${TEST_PORT}/api`;
const jokes = require("../model/jokes");
let server;
describe("Verify the Joke API", function() {
before(function(done){
server = http.createServer(app);
server.listen(TEST_PORT,()=>{
console.log("Server Started")
done()
})
})
after(function(done){
server.close();
done();
})
beforeEach(function(){
jokes.setJokes(["aaa","bbb","ccc"])
})
it("Should add the joke 'ddd",async function(){
var init = {
method: "POST",
headers : {"content-type": "application/json"},
body : JSON.stringify({joke: "ddd"})
}
await fetch(URL+"/addjoke",init).then(r => r.json());
//Verify result
expect(jokes.getAllJokes()).lengthOf(4);
expect(jokes.getAllJokes()).to.include("ddd")
})
}Explain, preferably using an example, how you have deployed your node/Express applications, and which of the Express Production best practices you have followed.
Babel is a JavaScript transpiler that converts edge JavaScript into plain old ES5 JavaScript that can run in any browser (even the old ones).
It makes available all the syntactical sugar that was added to JavaScript with the new ES6 specification, including classes, fat arrows and template literals.
ES6 modules allow the JavaScript developer to break their code up into manageable chunks, but the consequence of this is that those chunks have to be served up to the requesting browser, potentially adding dozens of additional HTTP requests back to the server — something we really ought to be looking to avoid. This is where webpack comes in.
Webpack is a module bundler. Its primary purpose is to process your application by tracking down all its dependencies, then package them all up into one or more bundles that can be run in the browser.
Explain about promises in ES-6 including, the problems they solve, a quick explanation of the Promise API and:
The Promise object represents the eventual completion (or failure) of an asynchronous operation, and its resulting value.
A Promise is a proxy for a value not necessarily known when the promise is created. It allows you to associate handlers with an asynchronous action's eventual success value or failure reason. This lets asynchronous methods return values like synchronous methods: instead of immediately returning the final value, the asynchronous method returns a promise to supply the value at some point in the future.
A Promise is in one of these states:
- pending: initial state, neither fulfilled nor rejected.
- fulfilled: meaning that the operation completed successfully.
- rejected: meaning that the operation failed.
A pending promise can either be fulfilled with a value, or rejected with a reason (error). When either of these options happens, the associated handlers queued up by a promise's then method are called.
If the promise has already been fulfilled or rejected when a corresponding handler is attached, the handler will be called, so there is no race condition between an asynchronous operation completing and its handlers being attached.
As the Promise.prototype.then() and Promise.prototype.catch() methods return promises, they can be chained.
Pyramid of Doom
doSomething(function(responseOne) {
doSomethingElse(responseOne, function(responseTwo, err) {
if (err) { handleError(err); }
doMoreStuff(responseTwo, function(responseThree, err) {
if (err) { handleAnotherError(err); }
doFinalThing(responseThree, function(err) {
if (err) { handleAnotherError(err); }
// Complete
}); // end doFinalThing
}); // end doMoreStuff
}); // end doSomethingElse
}); // end doSomethingSolution
doSomething()
.then(doSomethingElse)
.catch(handleError)
.then(doMoreStuff)
.then(doFinalThing)
.catch(handleAnotherError)var arrayOfPromises = [] // array containing promises
Promise.all(arrayOfPromises)
.then(function(arrayOfResults) {
/* Do something when all Promises are resolved */
})
.catch(function(err) {
/* Handle error is any of Promises fails */
})function get(url) {
return new Promise(function(resolve, reject) {
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function() {
if (req.status == 200) {
resolve(req.response); /* PROMISE RESOLVED */
} else {
reject(Error(req.statusText)); /* PROMISE REJECTED */
}
};
req.onerror = function() { reject(Error("Network Error")); };
req.send();
});
}Since both the success and error functions are optional, we can split them into two .then()s for better readability.
get(url)
.then(function(response) {
/* successFunction */
}, undefined)
.then(undefined, function(err) {
/* errorFunction */
})To make things even more readable, we make use of the .catch() method, which is a shorthand for a .then(undefined, errorFunction).
get(url)
.then(function(response) {
/* successFunction */
})
.catch(function(err) {
/* errorFunction */
})How it relates to promises and reasons to use it compared to the plain promise API.
Async Await is syntactic sugar that changes the .then notation to more readable syntax. Instead of making a . connection between the promises the keyword awaitcan be used instead.
function async myFunc() {
const res = await fetch(...)
const json = res.json()
// ...
}function async myFunc() {
try {
const res = await fetch(...)
const json = res.json()
// ...
} catch (err) {
new Error(err)
}
}Async/await makes asynchronous code look and behave like synchronous code
async function SerialFlow(){
let result1 = await doJob(1,1);
let result2 = await doJob(2,2);
let result3 = await doJob(3,3);
let finalResult = result1+result2+result3;
console.log(finalResult);
return finalResult;
}Explain the two strategies for improving JavaScript: ES6 (es2015) + ES7, versus Typescript. What does it require to use these technologies: In our backend with Node and in (many different) Browsers
ES6 and ES7 is newer implementations of JavaScript, which implements some new features, like async/await. Our browsers don't understand these new implementations, which means that in order for the browser to understand our code, it has to be transpiled into ES5, which all modern browser understand. The most used transpilers for JavaScript is Babel or Webpack.
TypeScript is a strict syntactical superset of JavaScript, and adds optional static typing to the language. As TypeScript is a superset of JavaScript, existing JavaScript programs are also valid TypeScript programs. TypeScript may be used to develop JavaScript applications for both client-side and server-side (Node.js) execution. TypeScript supports definition files that can contain type information of existing JavaScript libraries, this enables other programs to use the values defined in the files as if they were statically typed TypeScript entities. The TypeScript compiler, named tsc, is written in TypeScript. As a result, it can be compiled into regular JavaScript and can then be executed in any JavaScript engine (e.g. a browser). The compiler package comes bundled with a script host that can execute the compiler. It is also available as a Node.js package that uses Node.js as a host.
Provide examples and explain the es2015 features: let, arrow functions, this, rest parameters, de-structuring assignments, maps/sets etc.
With ES6 it is now possible to declare a variable that behaves more like we expect them to behave. While a var declaration is hoisted to the top of its scope a let or a const declaration is not hoisted and behaves like we know variable declarations from Java. The difference between a let and a const is that the let can be assigned a new value and the const can't.
// Defining a function
function addNumbers(a, b) {
return a + b;
}
// Using anonymous function
var addNumbers = function(a, b) {
return a + b;
}
// using Arrow Functions with return statement
var addNumbers = (a, b) => {
return a + b;
}
// Using Arrow Functions without return statements and without curly braces
var addNumbers = (a, b) => a + b; // implicit return statementthisis a unique keyword whose value changes depending on how it is called. When it is called outside a function, this refers to the Window object in the browser.
console.log(this) // WindowWhen this is called in a function, this is set to the global object.
function hello () {
console.log(this)
}
hello() // WindowWhen this is called in an object method, this would be the object itself.
let o = {
sayThis: function() {
console.log(this)
}
}
o.sayThis() // oWhen the function is called as a constructor, this refers to the newly constructed object.
function Person (age) {
this.age = age
}
let greg = new Person(22)
let thomas = new Person(24)
console.log(greg) // this.age = 22
console.log(thomas) // this.age = 24When used in an event listener, this is set to the element that fired the event.
let button = document.querySelector('button')
button.addEventListener('click', function() {
console.log(this) // button
})In arrow functions, this never gets bound to a new value, no matter how the function is called. this will always be the same this value as its surrounding code.
function f (x, y, ...rest) {
return (x + y) * rest.length
}
f(1, 2, "hello", true, 7) === 9Array Matching
var list = [ 1, 2, 3 ]
var [ a, , b ] = list // a === 1, b === 3
[ b, a ] = [ a, b ] // b === 1, a === 3Object Matching, Shorthand Notation
var { op, lhs, rhs } = getASTNode()Object and Array Matching, Default values
var obj = { a: 1 }
var list = [ 1 ]
var { a, b = 2 } = obj // a === 1, b === 2
var [ x, y = 2 ] = list // x === 1, y === 2let s = new Set()
s.add("hello").add("goodbye").add("hello")
s.size === 2 // no duplicate entries
s.has("hello") === true
for (let key of s.values()) // insertion order
console.log(key)let m = new Map()
let s = Symbol()
m.set("hello", 42)
m.set(s, 34)
m.get(s) === 34
m.size === 2
for (let [ key, val ] of m.entries())
console.log(key + " = " + val)Explain and demonstrate how es2015 supports modules (import and export) similar to what is offered by NodeJS.
// lib/math.js
export function sum (x, y) { return x + y }
export var pi = 3.141593
// someApp.js
import * as math from "lib/math"
console.log("2π = " + math.sum(math.pi, math.pi))
// otherApp.js
import { sum, pi } from "lib/math"
console.log("2π = " + sum(pi, pi))Provide an example of ES6 inheritance and reflect over the differences between Inheritance in Java and in ES6.
class Shape {
color;
constructor(color) {
this.color = color
}
}
class square extends Shape {
length;
constructor(color, length) {
super(color)
this.length = length
}
}JavaScript Object inheritance is Prototype based. ES6 classes are just syntactic sugar to make it look similar to OOP languages like Java. Behind the scene, no Class based inheritance but Prototype based inheritance.
Examples can be found here
Provide a number of examples to demonstrate the benefits of using TypeScript, including, types, interfaces, classes and generics
Examples can be found here
Explain the ECMAScript Proposal Process for how new features are added to the language (the TC39 Process)
Each proposal for an ECMAScript feature goes through the following maturity stages, starting with stage 0. The progression from one stage to the next one must be approved by TC39.
What is it? A free-form way of submitting ideas for evolving ECMAScript. Submissions must come either from a TC39 member or a non-member who has registered as a TC39 contributor.
What’s required? The document must be reviewed at a TC39 meeting (source) and is then added to the page with stage 0 proposals.
What is it? A formal proposal for the feature.
What’s required? A so-called champion must be identified who is responsible for the proposal. Either the champion or a co-champion must be a member of TC39 (source). The problem solved by the proposal must be described in prose. The solution must be described via examples, an API and a discussion of semantics and algorithms. Lastly, potential obstacles for the proposal must be identified, such as interactions with other features and implementation challenges. Implementation-wise, polyfills and demos are needed.
What’s next? By accepting a proposal for stage 1, TC39 declares its willingness to examine, discuss and contribute to the proposal. Going forward, major changes to the proposal are expected.
What is it? A first version of what will be in the specification. At this point, an eventual inclusion of the feature in the standard is likely.
What’s required? The proposal must now additionally have a formal description of the syntax and semantics of the feature (using the formal language of the ECMAScript specification). The description should be as complete as possible, but can contain todos and placeholders. Two experimental implementations of the feature are needed, but one of them can be in a transpiler such as Babel.
What’s next? Only incremental changes are expected from now on.
What is it? The proposal is mostly finished and now needs feedback from implementations and users to progress further.
What’s required? The spec text must be complete. Designated reviewers (appointed by TC39, not by the champion) and the ECMAScript spec editor must sign off on the spec text. There must be at least two spec-compliant implementations (which don’t have to be enabled by default).
What’s next? Henceforth, changes should only be made in response to critical issues raised by the implementations and their use.
What is it? The proposal is ready to be included in the standard.
What’s required? The following things are needed before a proposal can reach this stage:
- Test 262 acceptance tests (roughly, unit tests for the language feature, written in JavaScript).
- Two spec-compliant shipping implementations that pass the tests.
- Significant practical experience with the implementations.
- The ECMAScript spec editor must sign off on the spec text.
What’s next? The proposal will be included in the ECMAScript specification as soon as possible. When the spec goes through its yearly ratification as a standard, the proposal is ratified as part of it.
Explain, using relevant examples, concepts related to testing a REST-API using Node/JavaScript + relevant packages
We can test our code with mocha, and use chai's expect to make our tests more readable.
const expect = require("chai").expect;
describe("Calculator API", function() {
describe("Testing the basic Calc API", function() {
it("9 / 3 should return 7", function() {
expect(calc.divide(9, 3)).to.be.equal(3);
});
it("4 / 0 should throw error", function() {
expect(() => calc.divide(4, 0)).to.throw(/Attempt to divide by zero/);
});
});
describe("Testing the REST Calc API", function() {
before(function(done) {
calc.calcServer(PORT, function(s) {
server = s;
done();
});
});
it("4 + 3 should return 7", async function() {
const res = await fetch(URL + "add/4/3").then(r => r.text());
expect(res).to.be.equal("7");
});
after(function() {
server.close();
});
});
});It is important to note that arrow functions should not be used with mocha, due to the behavior of this and will not be able to access the mocha context
Explain, using relevant examples, about testing JavaScript code, relevant packages (Mocha etc.) and how to test asynchronous code.
We can test our code with Mocha, and we can make the asserts more readable with Chai's expect
const expect = require("chai").expect;
const calc = require("../calc");
describe("Calculator API", function() {
describe("Testing the basic Calc API", function() {
it("4 + 3 should return 7", function() {
const res = calc.add(4, 3);
expect(res).to.be.equal(7);
});
it("4 - 3 should return 1", function() {
const res = calc.subtract(4, 3);
expect(res).to.be.equal(1);
});
it("4 * 3 should return 12", function() {
const res = calc.muliply(4, 3);
expect(res).to.be.equal(12);
});
it("9 / 3 should return 7", function() {
const res = calc.divide(9, 3);
expect(res).to.be.equal(3);
});
it("4 / 0 should throw error", function() {
expect(() => calc.divide(4, 0)).to.throw(/Attempt to divide by zero/);
});
});
});Testing asynchronous code
const expect = require("chai").expect;
const calc = require("../calc");
const fetch = require("node-fetch");
const PORT = 2345;
const URL = `http://localhost:${PORT}/api/calc/`;
let server;
describe("Testing the REST Calc API", function() {
before(function(done) {
calc.calcServer(PORT, function(s) {
server = s;
done();
});
});
//testing asynchronous code
it("4 + 3 should return 7", async function() {
const res = await fetch(URL + "add/4/3").then(r => r.text());
expect(res).to.be.equal("7");
});
after(function() {
server.close();
});
});We can use nock to mock a website
const nock = require('nock');
describe("loadWiki()", function() {
before(function() {
//the website to be mocked
nock("https://en.wikipedia.org")
//the HTTP method and the path
.get("/wiki/Abraham_Lincoln")
//the response the mocked website should send
.reply(200, "Mock Abraham Lincoln Page");
});
it("Load Abraham Lincoln's wikipedia page", function(done) {
tools.loadWiki({ first: "Abraham", last: "Lincoln"}, function(html) {
expect(html).to.equal("Mock Abraham Lincoln Page");
done();
});
});
});A NoSQL database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases. Motivations for this approach include: simplicity of design, simpler "horizontal" scaling to clusters of machines, finer control over availability and limiting the Object-relational impedance mismatch. The data structures used by NoSQL databases (e.g. key-value, wide column, graph, or document) are different from those used by default in relational databases, making some operations faster in NoSQL. The particular suitability of a given NoSQL database depends on the problem it must solve. Sometimes the data structures used by NoSQL databases are also viewed as "more flexible" than relational database tables.
Many NoSQL stores compromise consistency in favor of availability, partition tolerance, and speed. Barriers to the greater adoption of NoSQL stores include the use of low-level query languages, lack of standardized interfaces, and huge previous investments in existing relational databases. Most NoSQL stores lack true ACID transactions, although a few databases have made them central to their designs.
Instead, most NoSQL databases offer a concept of "eventual consistency" in which database changes are propagated to all nodes "eventually" (typically within milliseconds) so queries for data might not return updated data immediately or might result in reading data that is not accurate, a problem known as stale reads. Additionally, some NoSQL systems may exhibit lost writes and other forms of data loss. Some NoSQL systems provide concepts such as write-ahead logging to avoid data loss. For distributed transaction processing across multiple databases, data consistency is an even bigger challenge that is difficult for both NoSQL and relational databases. Relational databases "do not allow referential integrity constraints to span databases". Few systems maintain both ACID transactions and X/Open XA standards for distributed transaction processing.
Explain Pros & Cons in using a NoSQL database like MongoDB as your data store, compared to a traditional Relational SQL Database like MySQL.
It is very fast to read data as you often avoid have to join tables. But it can also be slower to update because of the database is denormalized.
Since MongoDB on its own is schemaless, which can cause some troubles, using a layer on top like mongoose makes it possible also to reference documents in other collections inside a document
Explain, using your own code examples, how you have used some of MongoDB's "special" indexes like TTL and 2dsphere
MongoDB 2dsphere
const User = require("../models/user")
async function addUser(user) {
return await User.create(user)
}
async function addJobToUser(userId, job) {
return await User.findByIdAndUpdate(userId, {
$push: {
job
}
}, {new: true})
}
async function getAllUsers() {
return await User.find({})
}
async function findByUserName(userName) {
return await User.findOne({
userName
})
}
module.exports = {
addUser,
addJobToUser,
getAllUsers,
findByUserName
}Explain the benefits of using Mongoose, and demonstrate, using your own code, an example involving all CRUD operations
Since MongoDB on its own is schemaless, which can cause some troubles, using a layer on top like mongoose makes it possible also to reference documents in other collections inside a document.
Explain the “6 Rules of Thumb: Your Guide Through the Rainbow” as to how and when you would use normalization vs. denormalization.
rule 1 Favor embedding unless there is a compelling reason not to.
rule 2 Needing to access an object on its own is a compelling reason not to embed it.
rule 3 Arrays should not grow without bound. If there are more than a couple of hundred documents on the “many” side, don’t embed them; if there are more than a few thousand documents on the “many” side, don’t use an array of ObjectID references. High-cardinality arrays are a compelling reason not to embed.
rule 4 Don’t be afraid of application-level joins: if you index correctly and use the projection specifier (as shown in part 2) then application-level joins are barely more expensive than server-side joins in a relational database.
rule 5 Consider the write/read ratio when denormalizing. A field that will mostly be read and only seldom updated is a good candidate for denormalization: if you denormalize a field that is updated frequently then the extra work of finding and updating all the instances is likely to overwhelm the savings that you get from denormalizing.
rule 6 As always with MongoDB, how you model your data depends – entirely – on your particular application’s data access patterns. You want to structure your data to match the ways that your application queries and updates it.
reference 6 Rules of Thumb
Demonstrate, using your own code-samples, decisions you have made regarding → normalization vs denormalization
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
let JobSchema = new Schema({
type: String,
company: String,
companyUrl: String
});
let UserSchema = new Schema({
firstName: String,
lastName: String,
userName: {
type: String,
unique: true,
required: true
},
password: {
type: String,
required: true
},
email: {
type: String,
required: true,
unique: true
},
job: [JobSchema],
created: {
type: Date,
default: Date.now
},
lastUpdated: Date
});a user have a one-to-few job. therefore we have embedded the job data into user
Explain, using a relevant example, a full JavaScript backend including relevant test cases to test the REST-API (not on the production database)
the testing of the database could look like this:
const assert = require("assert")
const blogFacade = require("../facade/blogFacade")
const LocationBlog = require("../models/LocationBlog")
const User = require("../models/User")
const connect = require("../dbConnect")
connect(require("../settings").TEST_DB_URI);
describe("LocationBlogFacade", function () {
var testUser1
var testBlog1
beforeEach(async function () {
testUser1 = new User(
{
firstName: "Jenne",
lastName: "Teste",
userName: "jenn",
password: "1234",
email: "jenn@",
})
await testUser1.save()
testBlog1 = new LocationBlog({
info: "Very Nice blog i wrote here",
pos: { longitude: 22, latitude: 23 },
author: testUser1
})
await testBlog1.save()
})
afterEach(async function () {
await User.deleteMany({})
await LocationBlog.deleteMany({})
})
it("should should add the locationblog", async function () {
const blog = await blogFacade.addLocationBlog("Nice blog i wrote here", { longitude: 24, latitude: 23 }, testUser1)
assert.equal(blog.author, testUser1)
})
it("should add the user to the liked list", async function () {
const blog = await blogFacade.likeLocationBlog(testBlog1, testUser1)
assert.ok(blog.likedBy[0].equals(testUser1))
})
it("should not be able to have the same user to like twice", async function () {
const blog = await blogFacade.likeLocationBlog(testBlog1, testUser1)
await blogFacade.likeLocationBlog(blog, testUser1)
assert.equal(blog.likedByCount, 1)
})
})Geo-data, GeoJSON, Geospatial Queries with MongoDB, React Native/Expo’s Location and MapView Components
se miniprojekt del 3
se miniprojekt del 3
se miniprojekt del 3
Explain and demonstrate a REST API that implements geo-features, using a relevant geo-library and plain JavaScript
se miniprojekt del 3
Explain and demonstrate a REST API that implements geo-features, using Mongodb’s geospatial queries and indexes.
se miniprojekt del 3
se miniprojekt del 3
Demonstrate both server and client-side, of the geo-related parts of your implementation of the mini project
se miniprojekt del 3
se miniprojekt del 4
se miniprojekt del 4
se miniprojekt del 4
se miniprojekt del 4
Explain shortly about GraphQL Schema Definition Language, and provide a number of examples of schemas you have defined.
se miniprojekt del 4
Provide a number of examples demonstrating data fetching with GraphQL. You should provide examples both running in a Sandbox/playground and examples executed in an Apollo Client
se miniprojekt del 4
Provide a number of examples demonstrating creating, updating and deleting with Mutations. You should provide examples both running in a Sandbox/playground and examples executed in an Apollo Client.
se miniprojekt del 4
Explain the Concept of a Resolver function, and provide a number of simple examples of resolvers you have implemented in a GraphQL Server.
se miniprojekt del 4
Explain the benefits we get from using a library like Apollo-client, compared to using the plain fetch-API
se miniprojekt del 4
se miniprojekt del 4
se miniprojekt del 4
se miniprojekt del 4
se miniprojekt del 4
Demonstrate and highlight important parts of a “complete” GraphQL-app using Express and MongoDB on the server side, and Apollo-Client on the client.
se miniprojekt del 4