Add detectonlyperson.py which only detect person object and out put frame number into output.txt which person is detected, and save the video which only has person object
Hi, I'm Glenn Jocher, author of YOLOv5 🚀.
I'd like to invite you to attend the world's first-ever YOLO conference: #YOLOVISION22!
This virtual event takes place on September 27th, 2022 with talks from the world's leading vision AI experts from Google, OpenMMLab's MMDetection, Baidu's PaddlePaddle, Meituan's YOLOv6, Weight & Biases, Roboflow, Neural Magic, OctoML and of course Ultralytics YOLOv5 and many others.
Save your spot at https://ultralytics.com/yolo-vision!




English | 简体中文


YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.
See the YOLOv5 Docs for full documentation on training, testing and deployment.
Install
Clone repo and install requirements.txt in a Python>=3.7.0 environment, including PyTorch>=1.7.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installInference
YOLOv5 PyTorch Hub inference. Models download automatically from the latest YOLOv5 release.
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.Inference with detect.py
detect.py runs inference on a variety of sources, downloading models automatically from
the latest YOLOv5 release and saving results to runs/detect.
python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streamTraining
The commands below reproduce YOLOv5 COCO
results. Models
and datasets download automatically from the latest
YOLOv5 release. Training times for YOLOv5n/s/m/l/x are
1/2/4/6/8 days on a V100 GPU (Multi-GPU times faster). Use the
largest --batch-size possible, or pass --batch-size -1 for
YOLOv5 AutoBatch. Batch sizes shown for V100-16GB.
python train.py --data coco.yaml --cfg yolov5n.yaml --weights '' --batch-size 128
yolov5s 64
yolov5m 40
yolov5l 24
yolov5x 16
Tutorials
- Train Custom Data 🚀 RECOMMENDED
- Tips for Best Training Results ☘️ RECOMMENDED
- Multi-GPU Training
- PyTorch Hub 🌟 NEW
- TFLite, ONNX, CoreML, TensorRT Export 🚀
- NVIDIA Jetson Nano Deployment 🌟 NEW
- Test-Time Augmentation (TTA)
- Model Ensembling
- Model Pruning/Sparsity
- Hyperparameter Evolution
- Transfer Learning with Frozen Layers
- Architecture Summary 🌟 NEW
- Weights & Biases Logging
- Roboflow for Datasets, Labeling, and Active Learning 🌟 NEW
- ClearML Logging 🌟 NEW
- Deci Platform 🌟 NEW
- Comet Logging 🌟 NEW

| Comet ⭐ NEW | Deci ⭐ NEW | ClearML ⭐ NEW | Roboflow | Weights & Biases |
|---|---|---|---|---|
| Visualize model metrics and predictions and upload models and datasets in realtime with Comet | Automatically compile and quantize YOLOv5 for better inference performance in one click at Deci | Automatically track, visualize and even remotely train YOLOv5 using ClearML (open-source!) | Label and export your custom datasets directly to YOLOv5 for training with Roboflow | Automatically track and visualize all your YOLOv5 training runs in the cloud with Weights & Biases |
YOLOv5 has been designed to be super easy to get started and simple to learn. We prioritize real-world results.
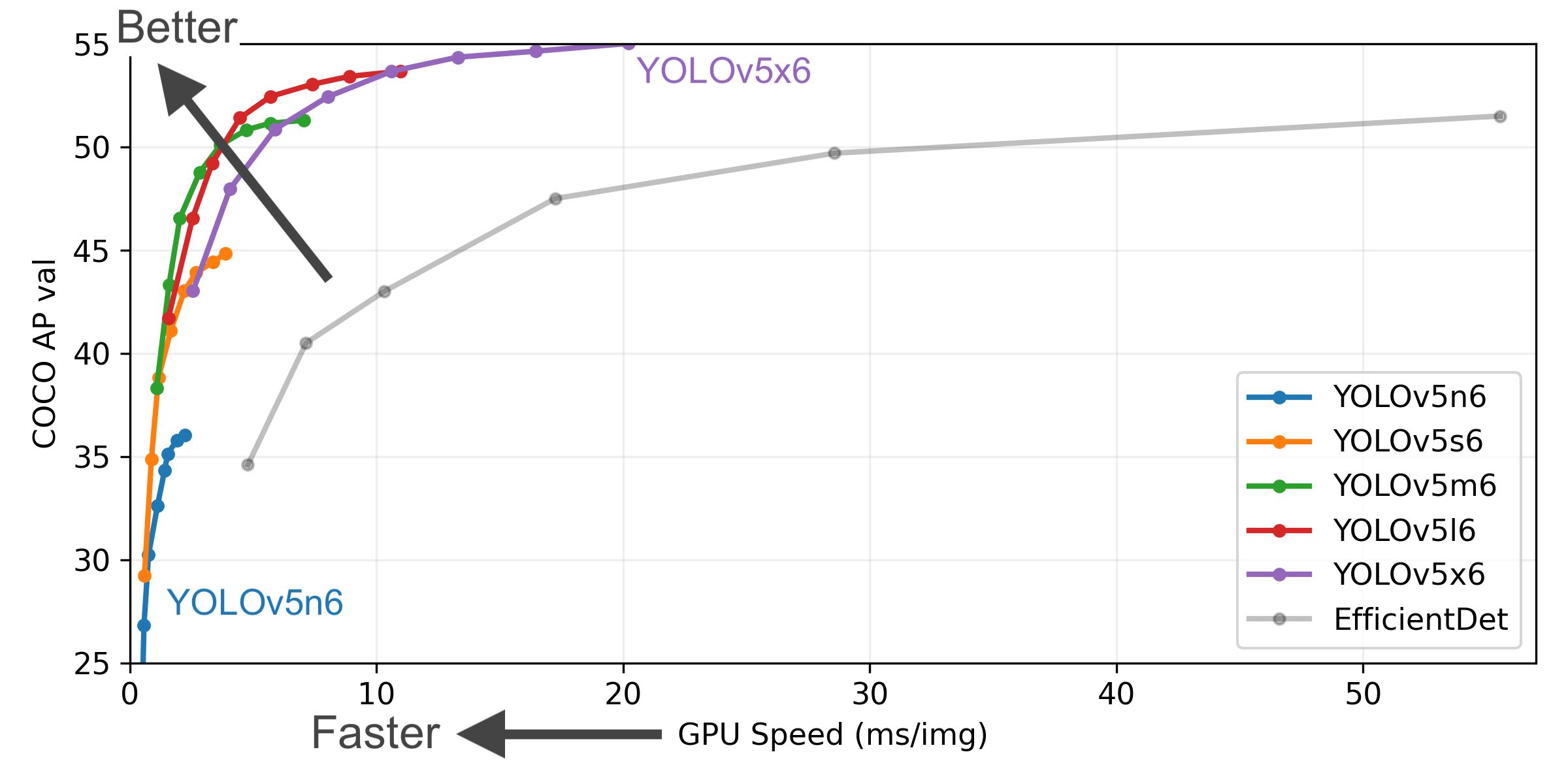
YOLOv5-P5 640 Figure (click to expand)
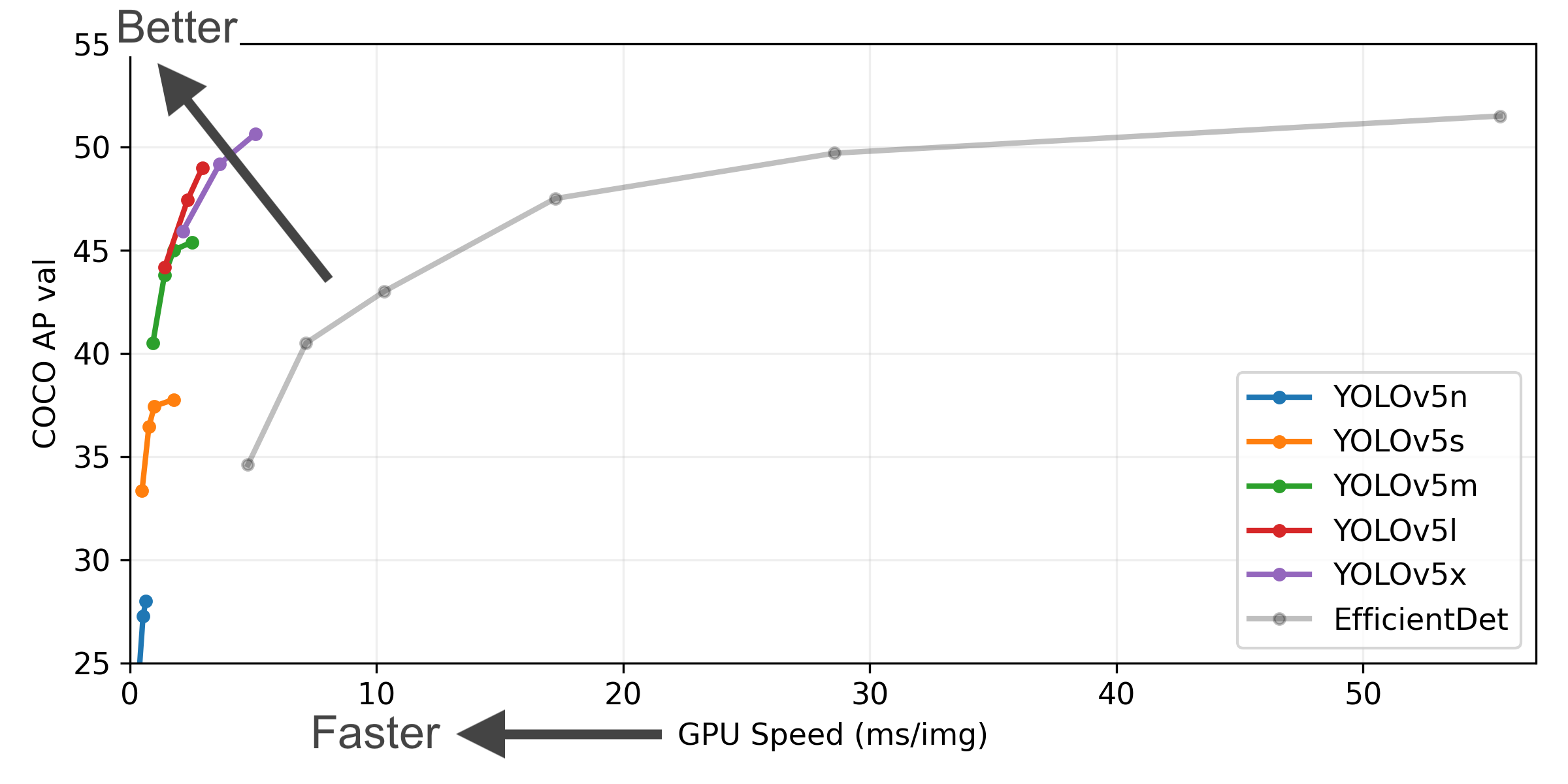
Figure Notes (click to expand)
- COCO AP val denotes mAP@0.5:0.95 metric measured on the 5000-image COCO val2017 dataset over various inference sizes from 256 to 1536.
- GPU Speed measures average inference time per image on COCO val2017 dataset using a AWS p3.2xlarge V100 instance at batch-size 32.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA |
1280 1536 |
55.0 55.8 |
72.7 72.7 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
Table Notes (click to expand)
- All checkpoints are trained to 300 epochs with default settings. Nano and Small models use hyp.scratch-low.yaml hyps, all others use hyp.scratch-high.yaml.
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - Speed averaged over COCO val images using a AWS p3.2xlarge instance. NMS times (~1 ms/img) not included.
Reproduce bypython val.py --data coco.yaml --img 640 --task speed --batch 1 - TTA Test Time Augmentation includes reflection and scale augmentations.
Reproduce bypython val.py --data coco.yaml --img 1536 --iou 0.7 --augment
YOLOv5 release v6.2 brings support for classification model training, validation, prediction and export! We've made training classifier models super simple. Click below to get started.
Classification Checkpoints (click to expand)
We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4xA100 instance, and we trained ResNet and EfficientNet models alongside with the same default training settings to compare. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google Colab Pro for easy reproducibility.
| Model | size (pixels) |
acc top1 |
acc top5 |
Training 90 epochs 4xA100 (hours) |
Speed ONNX CPU (ms) |
Speed TensorRT V100 (ms) |
params (M) |
FLOPs @224 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n-cls | 224 | 64.6 | 85.4 | 7:59 | 3.3 | 0.5 | 2.5 | 0.5 |
| YOLOv5s-cls | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
| YOLOv5m-cls | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
| YOLOv5l-cls | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
| YOLOv5x-cls | 224 | 79.0 | 94.4 | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
| ResNet18 | 224 | 70.3 | 89.5 | 6:47 | 11.2 | 0.5 | 11.7 | 3.7 |
| ResNet34 | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
| ResNet50 | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
| ResNet101 | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
| EfficientNet_b0 | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
| EfficientNet_b1 | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
| EfficientNet_b2 | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
| EfficientNet_b3 | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
Table Notes (click to expand)
- All checkpoints are trained to 90 epochs with SGD optimizer with
lr0=0.001andweight_decay=5e-5at image size 224 and all default settings.
Runs logged to https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2 - Accuracy values are for single-model single-scale on ImageNet-1k dataset.
Reproduce bypython classify/val.py --data ../datasets/imagenet --img 224 - Speed averaged over 100 inference images using a Google Colab Pro V100 High-RAM instance.
Reproduce bypython classify/val.py --data ../datasets/imagenet --img 224 --batch 1 - Export to ONNX at FP32 and TensorRT at FP16 done with
export.py.
Reproduce bypython export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224
Classification Usage Examples (click to expand)
YOLOv5 classification training supports auto-download of MNIST, Fashion-MNIST, CIFAR10, CIFAR100, Imagenette, Imagewoof, and ImageNet datasets with the --data argument. To start training on MNIST for example use --data mnist.
# Single-GPU
python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128
# Multi-GPU DDP
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3Validate YOLOv5m-cls accuracy on ImageNet-1k dataset:
bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validateUse pretrained YOLOv5s-cls.pt to predict bus.jpg:
python classify/predict.py --weights yolov5s-cls.pt --data data/images/bus.jpgmodel = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s-cls.pt') # load from PyTorch HubExport a group of trained YOLOv5s-cls, ResNet and EfficientNet models to ONNX and TensorRT:
python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224Get started in seconds with our verified environments. Click each icon below for details.
We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible. Please see our Contributing Guide to get started, and fill out the YOLOv5 Survey to send us feedback on your experiences. Thank you to all our contributors!

For YOLOv5 bugs and feature requests please visit GitHub Issues. For business inquiries or professional support requests please visit https://ultralytics.com/contact.