Google Spreadsheet data for human beings... and developers!
Jump to section: Resources | Features | Getting Started | Publishing your Google Spreadsheet to web | Include Spreadparser on your site. | Installation (for web projects) | Installation (for node projects) | Using it as a third party library | Live Examples | Documentation: getSpreadsheetUrl method | Documentation: parse method | How can you contribute? | License
Spreadparser turns a JSON endpoint from Google Spreadsheets into a easier to understand list of objects.
So, using Spreadparser could be useful for some goals such as:
- ✅ Small web projects
- ✅ Static generated websites
- ✅ Projects consuming government generated data
- ✅ Project prototyping
- ✅ Generate and share pages for visualizing third party data
- ✅ Studying project for frontend and backend developers
- ✅ Small companies online stores
- ✅ Allow non tech teams to provide data for tech teams
- ✅ Use Spreadsheet to create and maintain app config files
But it's probably not appropriate for:
- 🛑 Automatic spreadsheet update
- 🛑 Complex project based on relational database relations
- 🛑 Project with a huge amount of data
- 🛑 Google Spreadsheet data that can't be published to the web
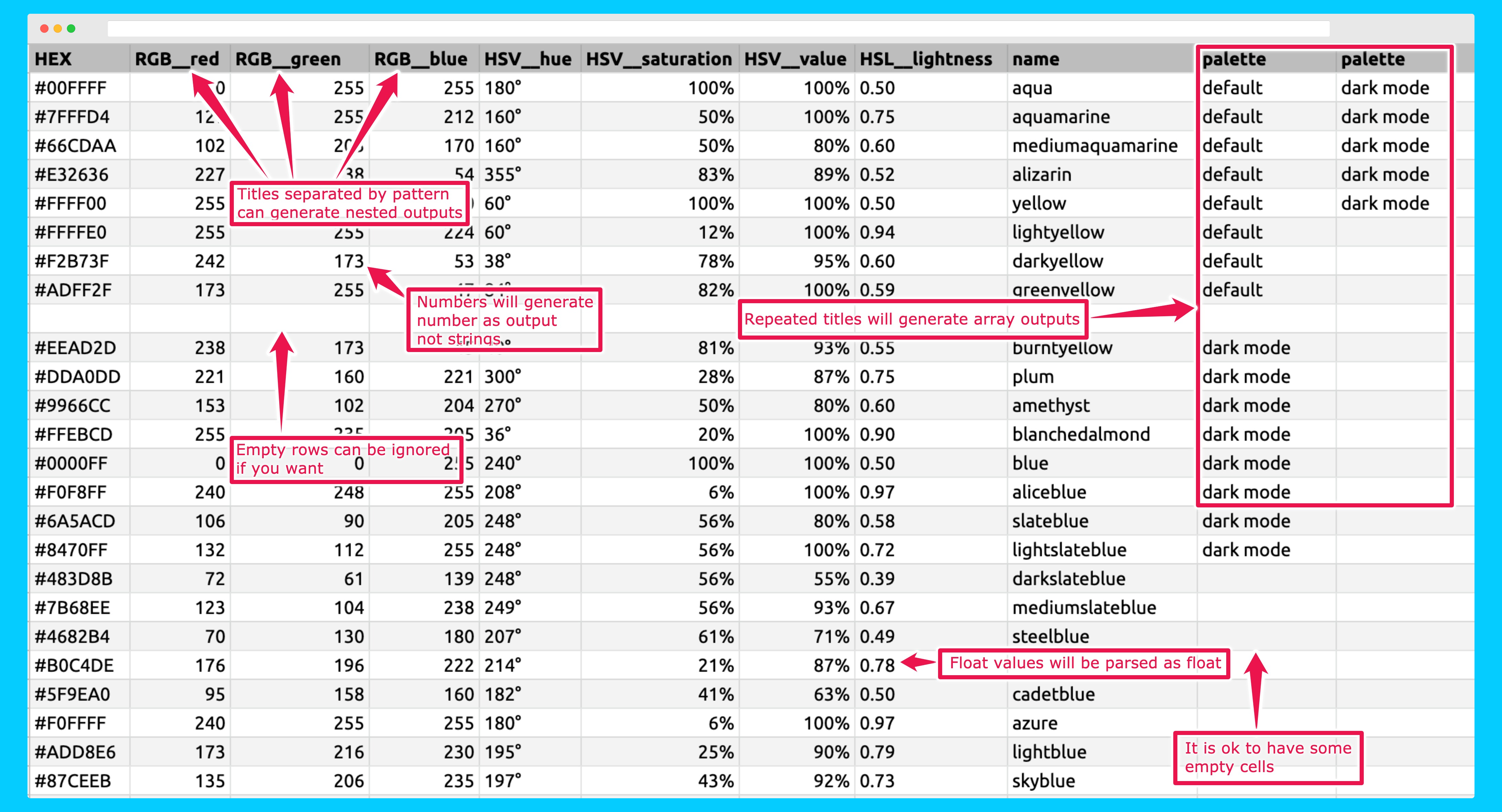
- 📦 Lightweigth: less than 2kb and zero dependencies
- 🧰 Versatile: Can be used for ES6/web projects, node project and as script tag
- 👍 Tested: Highly covered with unit testing, written with typescript
- 🎯 Understands your data as it is:
- ➡️
"TRUE","FALSE"strings and checkboxes become boolean valuestrueandfalse - ➡️ Integers and floats become real numbers like
10e0.33 - ➡️ Repeated title columns are parsed as arrays
- ➡️ Allow spreadsheet data to be parsed as nested objects with inner properties and value
- ➡️ Translate your data to your desired pattern like camel case or snake case
- ➡️
Compiled and production-ready code can be found in the dist directory. The src directory contains development code.
First of all you need to have a Google Spreadsheet with your data and publish it to the web.
Check how to 'Publish to the web' in 4 steps ⬇️
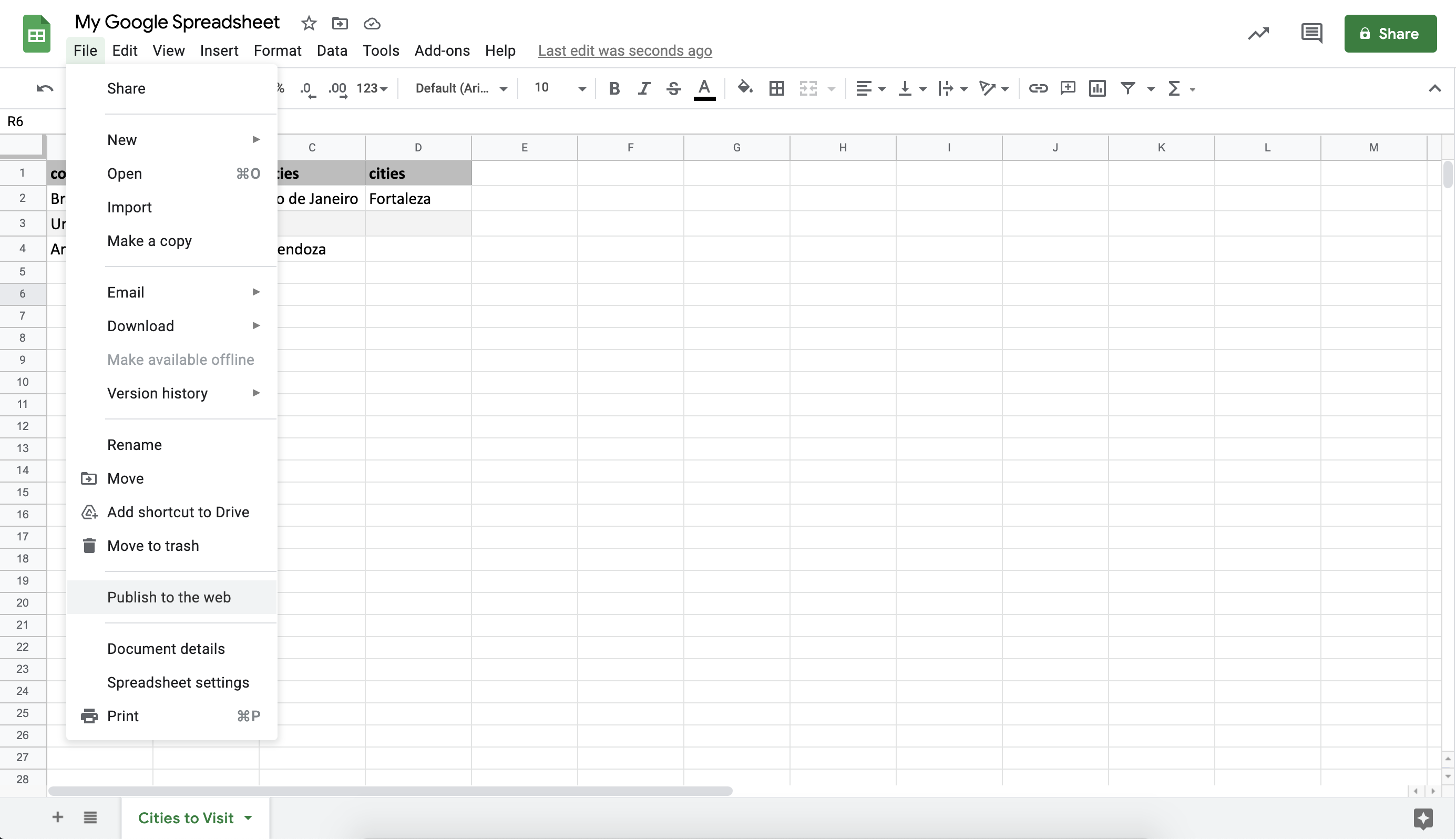
1. On your spreadsheet click on File > Publish to Web
2. In the following dialog click on 'Publish'
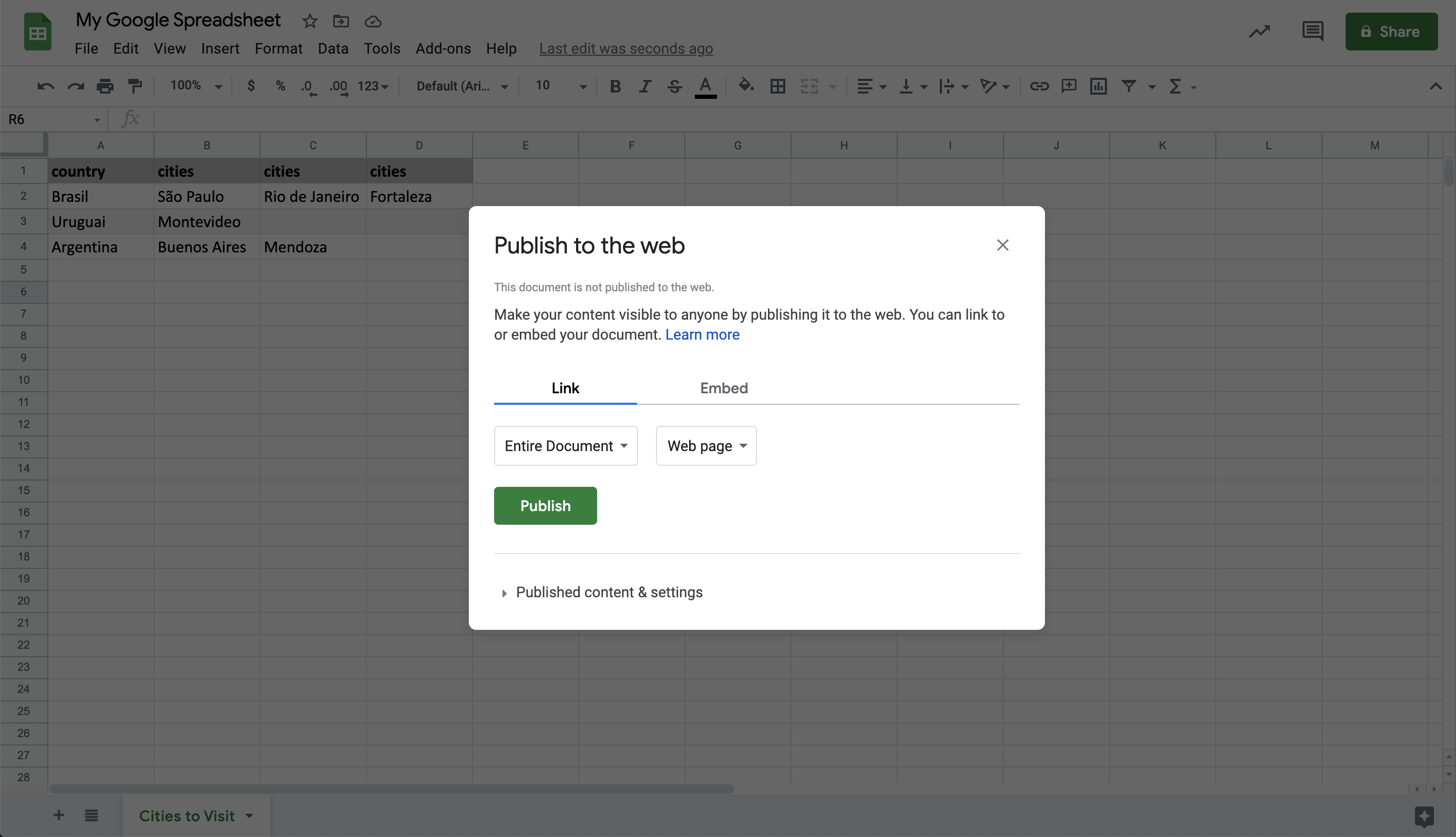
3. Its Published! You don't need to copy the generated url

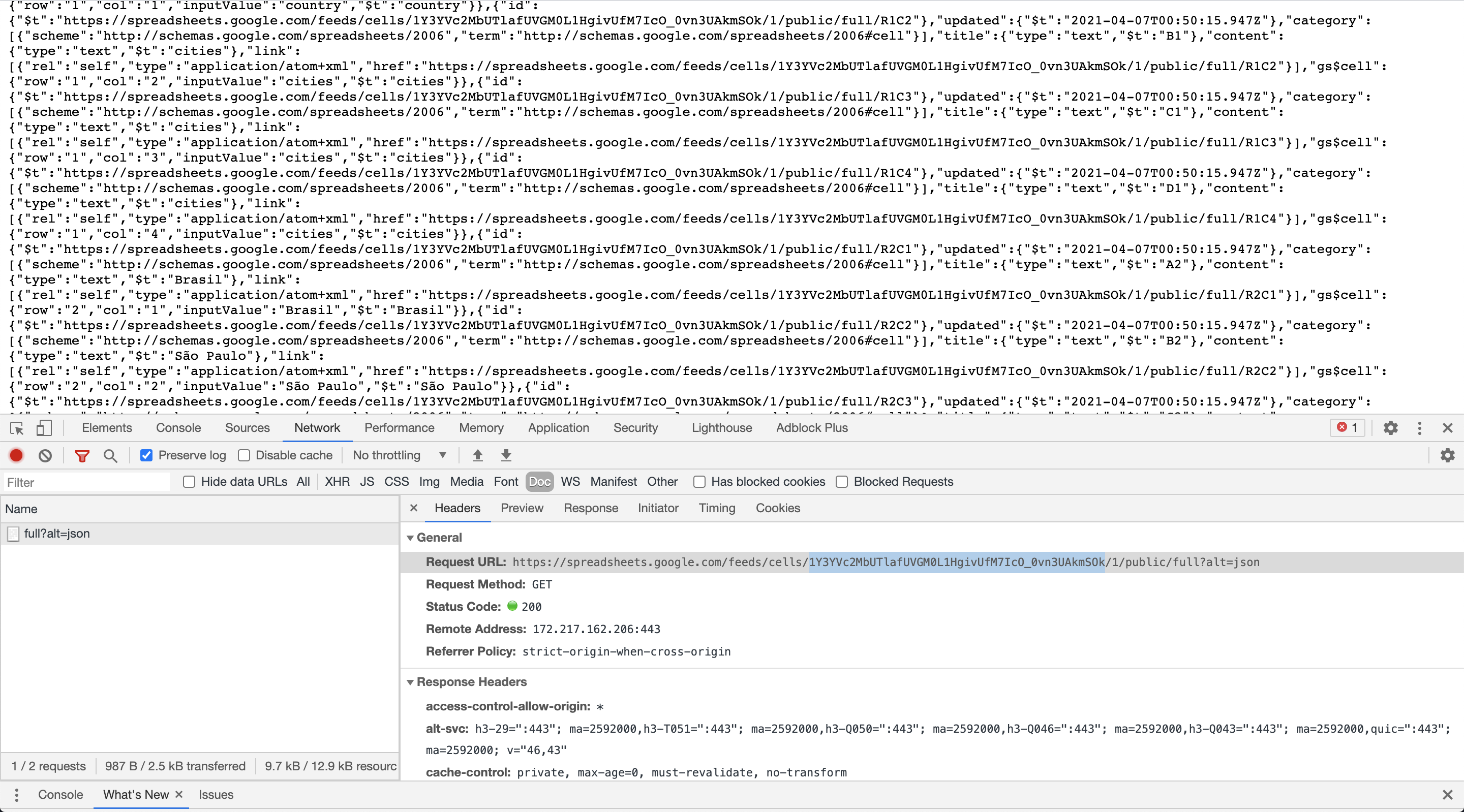
4. Open the JSON endpoint containing your data
The JSON url is made of your spreadsheet id, your spreadsheet id is part of your spreadsheet edition url.
For instance, if you have this spreadsheet edition url:
https://docs.google.com/spreadsheets/u/1/d/13FWF89zLCqKzeUzUfOwUqbRGhNSW3dLVHzItCe9WIAw/edit#gid=0
Your spreadsheet url is 13FWF89zLCqKzeUzUfOwUqbRGhNSW3dLVHzItCe9WIAw
Now that you have your spreadsheet JSON running let's use Spreadparser.
Direct Download
You can download the files directly from GitHub.
<script src="path/to/spreadparser.min.js"></script>CDN
You can also use the jsDelivr CDN. I recommend linking to a specific version number or version range to prevent major updates from breaking your site. Spreadparser uses semantic versioning.
<!-- Always get the latest version -->
<!-- Not recommended for production sites! -->
<script src="https://cdn.jsdelivr.net/npm/spreadparser/dist/spreadparser.min.js"></script>
<!-- Get minor updates and patch fixes within a major version -->
<script src="https://cdn.jsdelivr.net/npm/spreadparser@1/dist/spreadparser.min.js"></script>
<!-- Get patch fixes within a minor version -->
<script src="https://cdn.jsdelivr.net/npm/spreadparser@1.0/dist/spreadparser.min.js"></script>
<!-- Get a specific version -->
<script src="https://cdn.jsdelivr.net/npm/spreadparser@1.0.0/dist/spreadparser.min.js"></script>NPM
You can also use yarn (or your favorite package manager).
yarn add spreadparserNo extra configuration needed—just standard JavaScript.
fetch(Spreadparser.getSpreadsheetUrl("1Rr2y3ljAJPApYXcPyLXwxLciUCxz8XCu1Q0OnWH1l-U", 2))
.then(response => response.json())
.then(json => Spreadparser.parse(json, {titleCase: 'camelCase'}))
.then(spreadsheet => {
console.log(spreadsheet.data[0]); // You can see this console.log output bellow
});Giving us the following output:
{
"nome":"Água",
"hex":"#00FFFF",
"rgb":{
"red":0,
"green":255,
"blue":255
},
"hsv": {
"hue":"180°",
"saturation":"100%",
"value":"100%"
},
"nomeWeb":"aqua"
}Install it as a dependency:
yarn add spreadparser # or npm install spreadparserNow you can import Spreadparser as following:
import Spreadparser from "spreadparser";It is possible to use Spreadparser for server side projects using node. For instance you can create a 11ty blog or a command line tool with Spreadparser:
Install it as a dependency:
yarn add spreadparser # or npm install spreadparserNow you can import Spreadparser as following:
const Spreadparser = require("spreadparser/dist/umd/spreadparser.js");Spreadparser is available at jsDelivr CDN, for using it all you have to do is add proper url as script src to your HTML page:
<script src="https://unpkg.com/spreadparser">Spreadparser is also available on unpkg.com
In the next topic we provide live examples of Spreadpaser as thirdy party library combined with other frontend tools.
Here are some live examples for Spreadparser:
- A list of brazilian named colors - VueJS + Bulma + Spreadpaser
Spreadparser.getSpreadsheetUrl is a static method that receives two parameters: spreadsheetId and sheetNumber.
| Parameter | Type | Default | Required |
|---|---|---|---|
| spreadsheetId | string | undefined |
true |
| sheetNumber | number | 1 |
false |
Sample usage:
Spreadparser.getSpreadsheetUrl("1Rr2y3ljAJPApYXcPyLXwxLciUCxz8XCu1Q0OnWH1l-U")
// https://spreadsheets.google.com/feeds/cells/1Rr2y3ljAJPApYXcPyLXwxLciUCxz8XCu1Q0OnWH1l-U/1/public/full?alt=json
Spreadparser.getSpreadsheetUrl("1Rr2y3ljAJPApYXcPyLXwxLciUCxz8XCu1Q0OnWH1l-U", 2)
// https://spreadsheets.google.com/feeds/cells/1Rr2y3ljAJPApYXcPyLXwxLciUCxz8XCu1Q0OnWH1l-U/2/public/full?alt=jsonThis method does exists because Spreadparser intentionally doesn't have a method to fetch data. So you can get your Spreadsheet JSON url and fetch data in your own way.
Spreadparser.parse is a static method that receives two parameters: originalData and options.
| Parameter | Type | Required |
|---|---|---|
| originalData | object | true |
| options | object | false |
Right bellow theres documentation for Spreadparser.parse options.
The second parameter for Spreadparse.parse is an object with properties. These properties are described below:
| Option | Type | Default | Description |
|---|---|---|---|
| separator | string | '__' |
String portion used to separate nested objects |
| titleCase | string | 'none' |
Selected case style for data keys |
| headerRow | number | 1 |
Row number for title row |
| includeEmptyRows | boolean | false |
Use to include empty rows as part os data array |
Here are some complete options examples. Let's say we have a Google Spreadsheet as the following, we are going to asume that row column represents a real row number for each row:
| row | Person > Name | Adress > Street > Name | Adress > Street > Number | Hobbies | Hobbies |
|---|---|---|---|---|---|
| 5 | Benjamin | Yancy | 32 | Gym | Reading |
| 7 | Peter | Queens Street | 62 | Climb walls | Science |
For the above Google Spreadsheet, the title row is number 4 not 1 as usual. So, using the following options:
const persons = Spreadparser.parse(originalData, {
separator: '>',
titleCase: 'camelCase',
headerRow: 4,
includeEmptyRows: true
})The persons.data array will be:
[{
"row": 5,
"person": {
"name": "Benjamin"
},
"adress": {
"street": {
"name": "Yancy",
"number": 32
}
},
"hobbies": ["Gym", "Reading"]
}, {}, {
"row": 7,
"person": {
"name": "Peter"
},
"adress": {
"street": {
"name": "Queens Street",
"number": 62
}
},
"hobbies": ["Climb Walls", "Science"]
}]- Give a ⭐ to this project if you like it
- Trust it as npm dependency for some of your projects
- Help this project opening an issue, you may suggest a feature, documentation or share a bug
- Improve this project by creating a pull request
- Create a new live example using Spreadparser, maybe using codepen
- Spread the idea!
MIT - Jota Teles - 2021