


Relational NLP Preprocessing (rnlp): A Python package and tool for converting text into a set of relational facts.
- Documentation: https://rnlp.readthedocs.io/en/latest/
- Questions?: Contact Alexander L. Hayes (hayesall)
Stable builds on PyPi
pip install rnlprnlp can be used either as a command line interface (CLI) tool or as an imported Python Package.
| CLI | Imported |
$ python -m rnlp -f example_files/doi.txt
Reading corpus from file(s)...
Creating background file...
100%|████████| 18/18 [00:00<00:00, 38it/s] |
from rnlp.corpus import declaration
import rnlp
doi = declaration()
rnlp.converter(doi) |
The relations created by rnlp include the following:
- Sentence's Relative Position in Block:
earlySentenceInBlock: Sentence occurs within the first third of a block.midWaySentenceInBlock: Sentence occurs between the first third and the last third of a block's length.lateSentenceInBlock: Sentence occurs within the last third of a block's length.
- Word's Relative Position in Sentence:
earlyWordInSentence: Word occurs within the first third of a sentence.midWayWordInSentence: Word occurs between a third and two-thirds of a sentence.lateWordInSentence: Word occurs within the last third of a sentence.
- Relative Position Between Items:
nextWordInSentence: Pointer from a word to its neighbor.nextSentenceInBlock: Pointer from a sentence to its neighbor.
- Existential Semantics:
sentenceInBlock: Sentence occurs in a particular block.wordInSentence: Word occurs in a particular sentence.
- Low-Level Information about words:
wordString: A string representation of a word.partOfSpeechTag: The word's part of speech (as determined by the nltk part-of-speech tagger).
---
Files contain a toy corpus (example files/) and an image of a BoostSRL tree for predicting if a word in a sentence is the word "you".
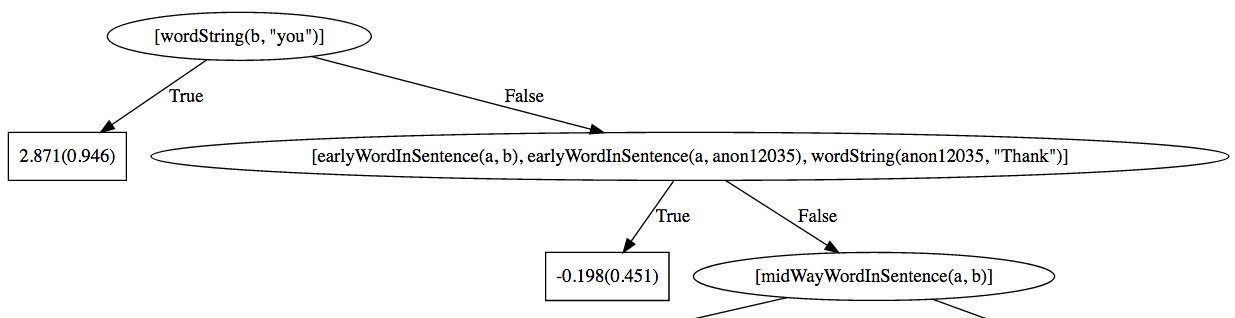
The tree says that if the word string contained in word 'b' is "you" then 'b' is the word "you" with a high probability. (This is of course true). A more interesting inference is the False branch that says that if word 'b' is an early word in sentence 'a' and word 'anon12035' is also an early word in sentence 'a' and if the word string contained in word 'anon12035' is "Thank", then the word 'b' has decent chance of being the word "you". (The model was able to learn that the word "you" often occurs with the word "Thank" in the same sentence when "Thank" appears early in that sentence).