Added kmeans++ initialization to clustering API #443
Conversation
|
@SaoirseARM: for ease of comparison, could you also copy over the prior |
|
Thanks @alanchiao , I have updated the description above. |
I believe we should run the experiment with the same number of clusters to get comparable results. It might be better for consistency to get the results for MobileNetV1 with 32 clusters using the linear initialization, instead of 64 with kmeans++ -- that way all the full model clustering experiments will have 32 clusters across the board. |
|
@SaoirseARM I suspect we did not use the same scripts for testing mobilenet_v1. Please let me know if you want to talk about this. |
|
@akarmi We had talked and the tests are in sync now. As mentioned by Stanley yesterday, the speed of convergence and the benefit for memory usage is also worth checking for k-means++. Saoirse is talking to him I believe. |
|
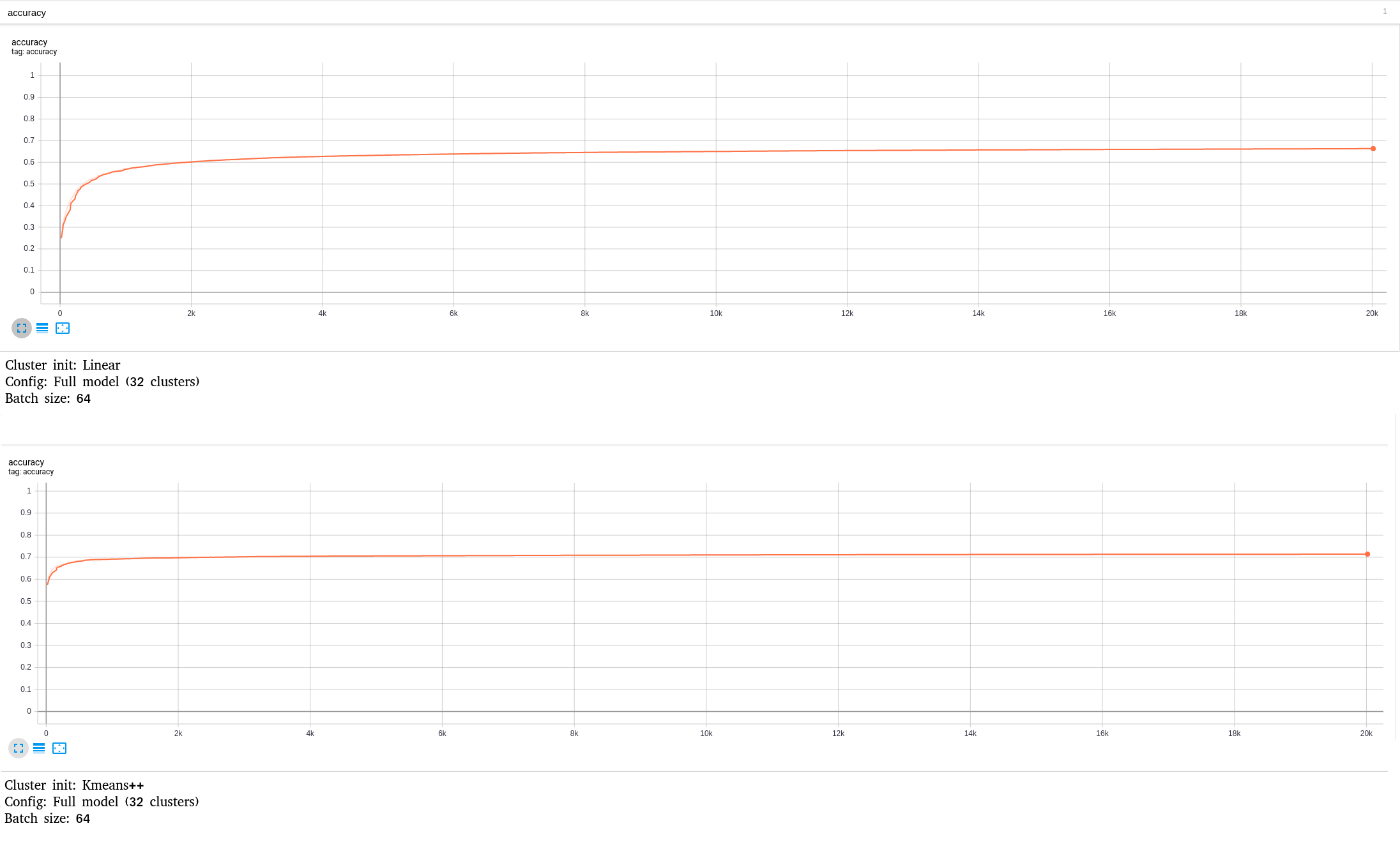
Hi, Updated the description to reflect test result updates and speed of convergence graph. Thanks. |
There was a problem hiding this comment.
Thank you. I think we should also add the relevant API documentation, e.g. to cluster_weights(). It looks good to me otherwise.
As discussed off-line, we are likely to hold off merging this change until after the initial release. In the meantime, @alanchiao, do you have any other comments on this?
704f9ab to
5e3cbf8
Compare
|
Looks good! |
163dea8 to
4042968
Compare
4042968 to
efe9af4
Compare
|
Please go ahead and attach the |
|
@SaoirseARM: I've noticed now that this change didn't come with an update to RELEASE.md (top-level directory) for release notes. Will merge now but please send a PR to update them. |
|
It'd also be good to follow with documentation changes. Keep in mind though that https://www.tensorflow.org/model_optimization/guide/clustering and other pages currently are not version specific, so the k-means functionality won't be available unless they install from source. |
Added Kmeans++ centroid initialization to the clustering API as an alternative configurable initialization method to density-based, linear and random.
Allowing the heuristic to determine the number of retries (num_retries_per_sample=-1) and a seed of 9 to match closely with the default scikit-learn kmeans++ implementation.
Experimental results:
MobileNet-V2 Linear vs. Kmeans++ convergence comparison