Enable differentiable training and update cluster indices #519
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
Hi @alanchiao and @akarmi, I have just filled in all the results in the description. Could you please take a look at the PR and let me know your thoughts? Also, not sure how long the description should be? |
16ad7a9 to
a248f89
Compare
akarmi
approved these changes
Aug 26, 2020
|
As noted in the call, I'll take a look at this, but after it merges when I have the time. |
a248f89 to
51d4c22
Compare
|
@alanchiao, could you check what is holding up this PR please? |
|
Yes I am. |
|
Closed this PR since it had already been merged by a different commit. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
5 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Motivation:
In the current clustering implementation, the original weights of the clustered layers and the cluster indices are not updated during each training step. Tho the training process alters the values of the cluster centroids, due to the changes in other non-clustered layers, which are reflected in the gradients during training, the non-updated original weights will not always match the constantly updated cluster centroids and will create problems during training. In order to fix this issue, we want to update the original weights after the backpropagation. After that, using the updated centroids, the indices should be re-generated in the next training step. In this PR, changes are made and the unit tests for them are created too.
Details of the implementation:
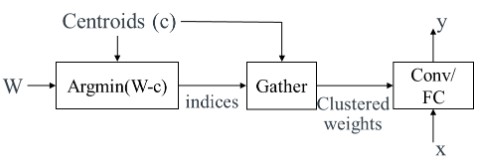
As shown in the figure below, in the forward pass of our current clustering implementation, first, it uses density-based or linear methods to initialize the centroids (c) for the weights of each layer. Then, the original set of weights (W) are grouped into several clusters using the centroid values. Afterward, the association between the weights and the centroids is calculated based on c and W as indices. Finally, for a single cluster, the centroid value will be shared among all the weights and used in the forward pass instead of the original weights.
In the current backpropagation, the clustered weights will get the gradients from the layer being wrapped. These gradients will be fed into the node gather. Then, the gather node groups all the gradients by indices and accumulates them as the gradients of the centroids. However, due to the non-differentiable node
tf.math.argmin, no gradients will be calculated for original weights W by automatic differentiation in TensorFlow.A small modification (gradient approximations using the straight-through estimator [1]) of the training graph is used to override the gradient during backpropagation like this:
clustered_weights = tf.gather(cluster_centroids, indices)*tf.sign(original_weights + 1e+6)In the forward pass, the
multiplyin the graph does not change the graph (tf.signgives out identity matrix) but in the backpropagation, the multiply is changed into add and thetf.signis changed into identity viatf.custom_gradient. Essentially, the graph becomes:clustered_weights = tf.gather(cluster_centroids, indices)+tf.identity(original_weights + 1e+6)In this way, original weights can be updated by the automatic differentiation in TensorFlow.
Indices are not differentiable themselves and they are calculated only in the forward pass during training. Therefore, they are updated using
tf.assignspecifically in the forward pass in thecallfunction. This will lead to some extra change for usingtf.distribute, which has not been covered in this PR.Result table:
As shown in the table below, the changes in this PR significantly improve the accuracy when the number of clusters is small and give limited benefit for other configurations.
Reference:
[1] Y. Bengio, N. Leonard, and A. Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432, 2013.