Object detection: when training, GPU utilization started high, and became low/idle later on #6840
Description
System information
- What is the top-level directory of the model you are using: \Tensorflow\models\research\object_detection
- Have I written custom code: No
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Windows Server 2016
- TensorFlow installed from (source or binary): binary
- TensorFlow version (use command below): 1.13.1
- Python version: 3.7.3
- CUDA/cuDNN version: 10/7.1
- GPU model and memory: Tesla V100 - 16 GB
- Bazel version: N/A
- Exact command to reproduce: N/A
Describe the current behavior
I am trying to train a face detector by using the Object Detection API. Specifically, I am using 4000 images from the Wider Faces data set for training/validation, and using faster_rcnn_resnet101_coco for fine-tuning. I split the train set images into 5 shards, and in the .config file, I changed the min_dimension and max_dimension to 300 and 512, respectively, in hopes of faster training.
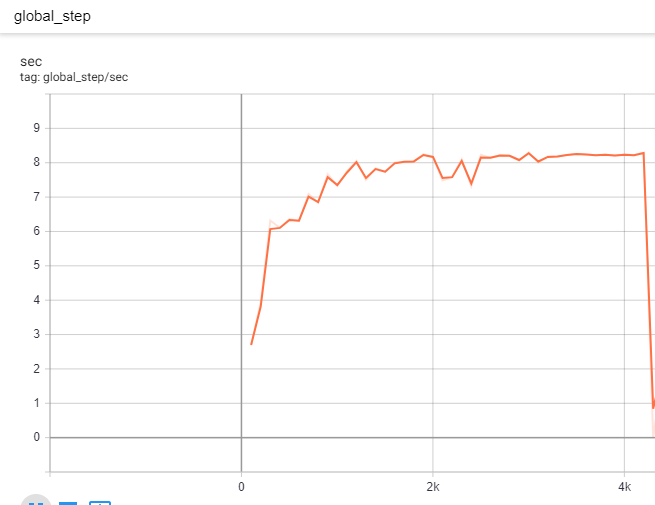
After I kicked off training, I noticed that the GPU memory usage was about 95%. GPU volatile-utilization and CPU utilization on the other hand were behaving oddly. Specifically, during the very first ~3k steps, GPU volatile-utilization was between 60% and 95%, and the CPU utilization was only around 8%. Global_step/sec essentially plateaued around 8 steps/sec within the first 3k steps.
From ~3k steps and onward, CPU utilization increased to 80-100% whereas GPU volatile utilization oscillated between 0% to 30% and for the most part, it was idle (0%). GPU memory usage continued to be high.
Starting from ~4k steps. global_step/sec dropped to around 1 step/sec (as shown below)
Unlike training, inference does seem to make use of GPU -- GPU volatile utilization is between 70%-100% during inference.
Describe the expected behavior
Given the initial high GPU volatile utilization rate, I was expecting the high util-rate to persist, so it was a bit strange to see that after the initial 3k steps, the training process only occasionally used the GPU, and mostly relied on the CPU.
Any pointers/help would be much appreciated. Thanks!