![]()
Shelfie---Catalogue and price your used book collection based off images shot on your smart phone camera.
Shelfie is an app that uses data science to automatically price books that it finds in user submitted images of bookshelves. It was built in a little over three weeks as my demo project at Insight data science in early 2018.
Possible use cases
- Recent college graduates that are curious about how much money they can make off their college textbooks.
- Used book store workers that receive a large quantity of books that need to be priced quickly.
- Anyone else looking for some quick cash :)
website: shelfie.site
At a high level, shelfie uses a combination of computer vision, image processing, and natural language processing to detect books in images of bookshelves. Breaking it down a little further, these are the main steps involved. A more detailed description of each step in the algorithm is presented in the following sections.
shelfie's algorithm:
- Detect all instances of text in the image
- Group the text by automatically detecting book spines
- Perform a search on the grouped words for a match on the Amazon books marketplace
- Validate each match in order to remove false positives
- Present the validated list of books to the reader

The problem of detecting text in natural scenes is still an active area of research in computer science. Fortunately, for those of us simply interested in getting good results, companies like Google and Amazon have pre-baked APIs we can call on to do the heavy lifting. For this project, I used the Google cloud vision API, which ended up giving great results and was very easy to use. Since the API is proprietary technology, Google doesn't speak up about the underlying algorithms, but it without a doubt is using cutting-edge computer vision tools like convolutional neural networks.
The image is submitted to the API for processing, and after only a few seconds an annotation object is returned, which contains detected tokens and their positions.

The next step is to group the detected tokens by spine. This was achieved using image processing techniques to find all the spine edges in the image. Tokens in the same spine interval are grouped together.

A simple Google search is performed for each group of tokens, and the resulting HTML is parsed for Amazon books links using Beautiful Soup. Every link to an Amazon product contains a unique product ID as part of the URL, and this product ID happens to be the ISBN-10 number for books. The ISBN-10 number is extracted from the Amazon link. Then, this ISBN-10 number is queried on the Amazon Products API, which provides access to the book's title, authors, publishers, and price.
Every potential book match for the token groups found in the original image is then returned to the user.
The algorithm performed fairly well on the validation set considered (a collection of cell phone images of my office and home bookshelves).
There were two main types of errors present, non-identification and misidentification. Non-identification occurs when a book that is sitting on the shelf is 'missed' by the algorithm. This was pretty rare, occurring with only a 3% rate in the validation set. Misidentification occurs when a book that is not on the shelf is falsely inserted, usually when a stray token is not grouped up with any other tokens. Misidentification occurred at a much higher rate than non-identification, so it was the main type of error I considered.
The solution for dealing with misidentifications is to present the user with cautionary flags when shelfie thinks a book might be misidentified. This flagging occurs by calculating a 'score' for each book match, with matches having too low of a score flagged.
The book score metric I use is the negative log likelihood, which is essentially a measure of the probability of some random tokens finding a book match by chance. The score depends on both the number of words in the group and each word's rarity.
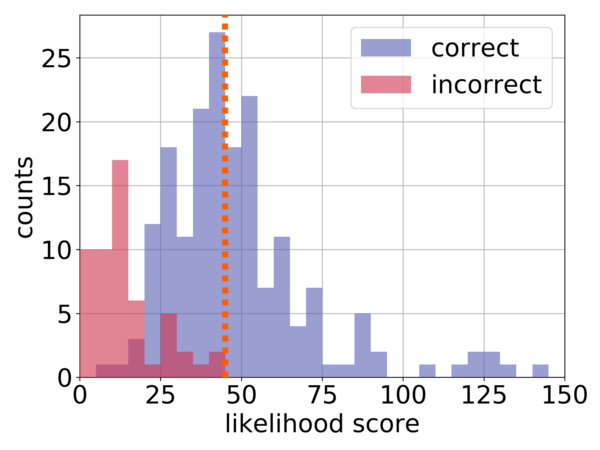
The score was calculated for each book match in the validation set. Based off the validation set, I chose a decision boundary for flagging books to focus on reducing the number of false positive occurrences. In the context of this problem, a false positive occurs when a book that is not present on the shelf is not flagged by the user; this outcome is really bad for the user, because it means they might accidentally list a book that they don't own.
With the decision boundary set, the book matches are scored and flagged as possible misidentifications if their score is too low, before finally being presented to the user.