PGCODE started as (and it still is) - my personal, pet-project that I've been doing for years now.
Essentially, it is just another and development tool - for the PostgreSQL database..
The idea was and is to create a tool for myself - which I can personally use daily in my work.
So, I wasn't led be the idea to please everyone, or at least as many people as I can - but rather - to build myself a tool for my work that I'm doing (database development with PostgreSQL).
And also, I was completely free to experiment and even start all over a couple of times. Which is great because it gives me freedom, but it can lead to some unnecessary over-engineerings.
Given all that, it is safe to say that at this point - it has some pretty unique features that can hardly be found in similar tools.
I'll try to describe those in this blogpost in details, but here is just the screenshot for now (a picture says a thousand words):
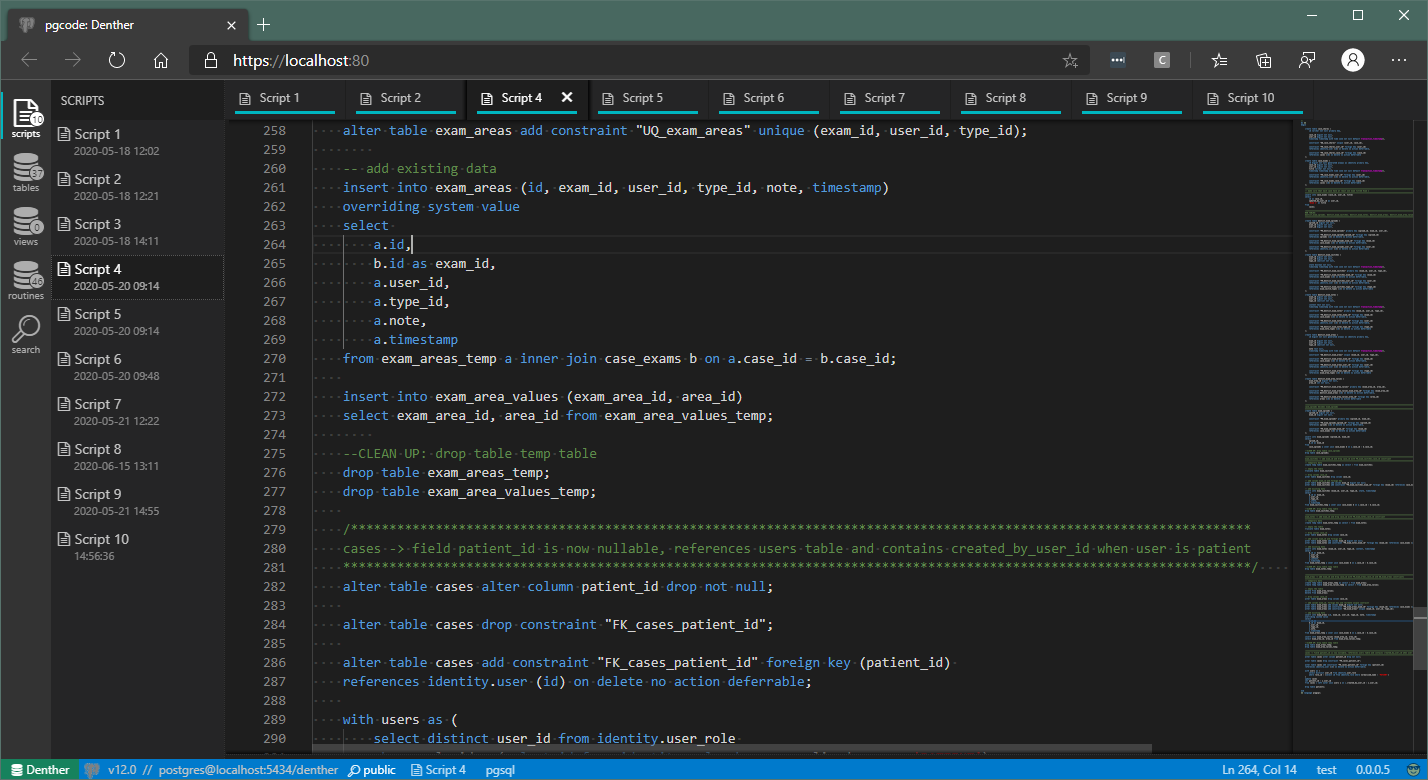
It all started with me playing around with the incredible monaco editor and it would be kind of an understatement to say it escalated real quick.
Monaco editor is an official editor component from Visual Studio Code which Microsoft turned into a free and open-source JavaScript component library available through NPM for everyone to use.
In my opinion - it is a light years ahead of anything available for editing PostgreSQL code or any code as Visual Studio Code users are aware. Well maybe I'm exaggerating a bit, I don't what editors are available for PostgreSQL out there, but nevertheless, the fact is that I started using it even before some crucial features are finished (like execution part for example). The editor is Fast and slick and incredibly flexible and extendable. There is a ton of editor features that can be built in to make any work on any code productive and fun.
So I started experimenting a bit with different concepts of how it would work best with having a .NET Core as backend.
I must admit, at that time I was suffering from heavy JavaScript fatigue so I've decided to go with just vanilla JavaScript without any popular frameworks of the day. And not only that, entire frontend code so far doesn't use a single 3rd party module, at all.
Building an IDE is no trivial task at all, so, maybe today I would choose a different path, perhaps Vue or even Blazor Web Assembly, but nevertheless, UI for the current prototype is incredibly fast and slick. and I like it very much.
I did, however, restarted the entire project at least three times for now, and I certainly not going to do it again and it even sprung a couple of other more or less successful side-projects (such as iHipsterJS JavaScript framework and Norm.net data access library.
I used to see it as just a training or learning experience, so I didn't mind doing it that way and I stuck with my vanilla JS decision.
In later iterations, I switched to TypeScript, which was, of course, a good thing. Also, because of my JS Framework fatigue, I didn't use a standard building mechanism such as WebPack. I've built my own, specifically for this project. It uses a slightly modified version of the JavaScript module loader found in Visual Studio Code and the Monaco editor.
Now, that may seem unreasonable and bit too much, but doing that, it offered some other possibilities I haven't even though of before.
Like for example - plugins. Lots of plugins. Add a JavaScript plugin module, for every part of the UI, would be incredibly easy and even fun.
But, of course, that is not all. Let's examine the basic concept first.
PGCODE is basically just another command-line program or CLI program.
And all you need to use to be able to use it is one, single, executable file (that can be copied and distributed among team members or where it might be needed, via physically copying file or otherwise).
You can have an optional configuration file to define your connections and other settings, but you can also use command-line parameters as in any other CLI program.
And when you do run it - you'll have pretty much standard console output as you might expect. The only thing that the last line will be something like this:
PGCODE, when run, will show an output something like this:
Listening on: https://localhost:80
Hit CTRL-C to stop the serverOf course, when you visit that URL - you can start using the web-based GUI for your PostgreSQL IDE (or just use --open switch do it automatically).
This is possible because there are a couple of things embedded inside executable. Like for example:
- Internal web server
- All other scripts needed for the entire Integrated Development Environment or IDE for your PostgreSQL server
Of course, there are separate build versions for Linux, OSX, and Windows systems as we can see on this console screenshot from my computer:
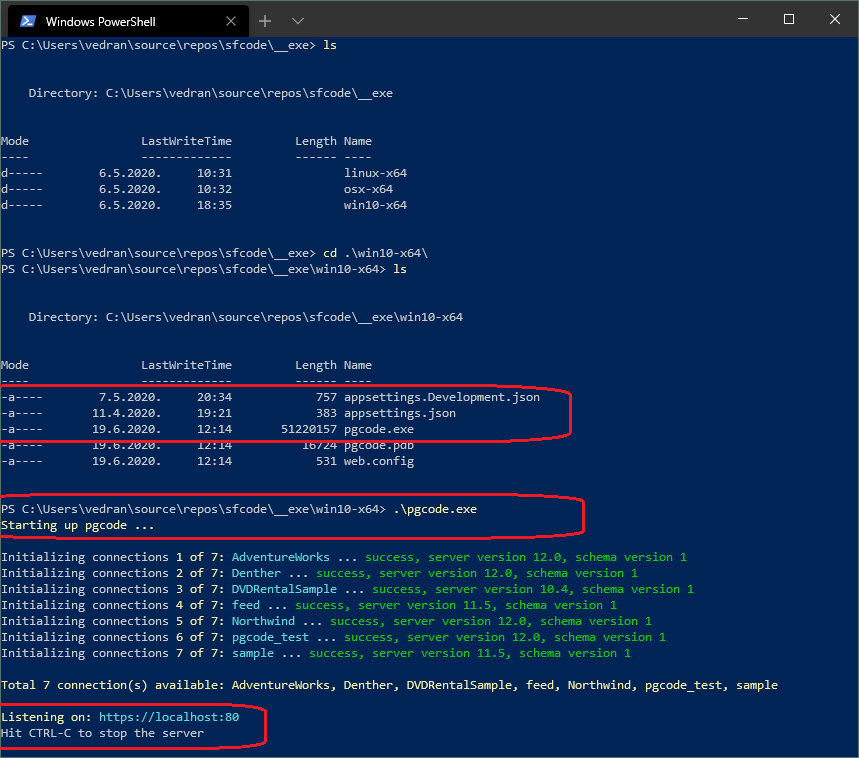
In this example, I started PGCODE command in my terminal and it initialized a total of 7 connections defined inside configuration file appsetting.json.
This concept gives me two possible usage scenarios:
The fact is that when you work on some software project - you already have your connections defined in your configuration files.
And you don't need to define them again.
Simplifies configuration because it makes it a part of a broader process.
You simply run the PGCODE command from your project root and it knows how to read your project configuration.
In this case, it is a JSON configuration file from .NET Core, but in the future, of course - it might be some other configuration schema as well, such as YAML files, etc.
Later in PGCODE, similar logic continues further so, for example, there is no save functionality at all. Every single thing from content to UI alignment is remembered instantly, so you may continue after the restart from the same place where you left off.
Naturally, you can save PGCODE executable to a remote server in your network - and configure the listening port and connections and let access to multiple users.
Executable is stand-alone and doesn't have any dependencies whatsoever and you don't need to install additional software like libraries or frameworks.
All you need to do is copy PGCODE executable file, define your connections (either in the configuration file or as CLI parameters) - and just run it.
You can even run it locally and open the PGCODE pre-configured port to other users in your network, as I said, all you need the executable.
It could even work in a cloud environment but it might be little memory usage intensive, especially for a larger number of concurrent users.
For example, a single script document that is opened with the editor maintains a corresponding PostgreSQL connection (to maintain the integrity of things like transactions and temporary tables), which takes around 50MB of memory. And that is just the connection alone.
User data, such as script content - are not saved to any file.
Instead, PGCODE uses the database itself.
When program runs and it initializes available connection. It will also check to see does your database has a special database schema (named pgcode) - and if it does not - it will create one for you.
All content is saved to tables inside that schema. And you can view or use them later easily in any other similar tool, such as psql command line (or any other like pgAdmin, etc) - on this screenshot:
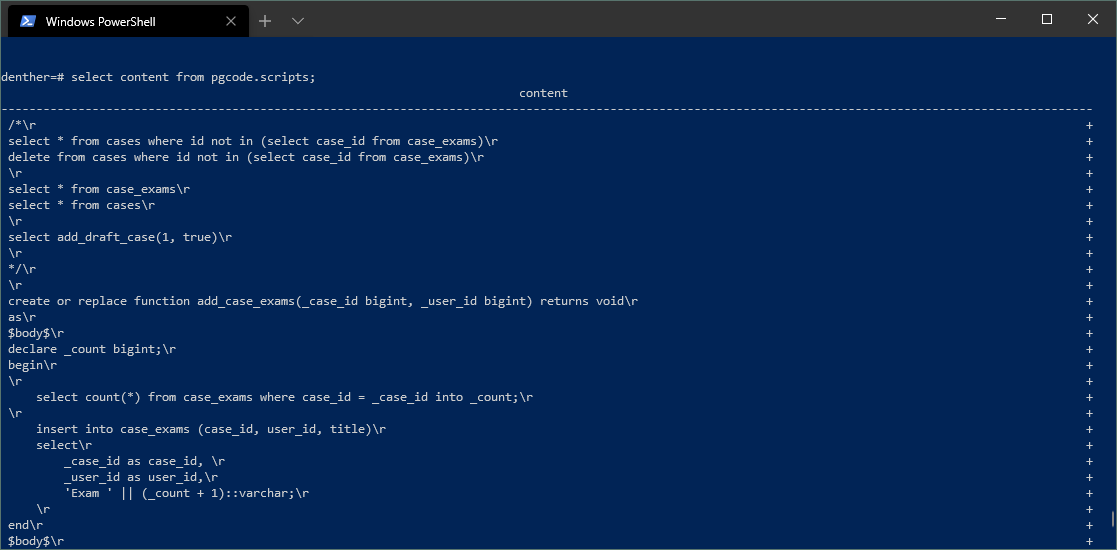
And since there is no saving feature, everything is remembered automatically, now, you don't even have to remember where is your work located. You can always access it easily just by using PostgreSQL connection with any tool available.
I find it to be a useful concept. I can't remember always where I have saved those scripts and scratch SQL files. Now, they are together with the same server instance they were originally written for.
In the future, this will greatly simplify the feature of sharing those scripts between users, and possibly, why not, working on the same script content by multiple users at the same time.
The single exe model simplifies the distribution model also.
All you need to do is copy the appropriate executable file for your system (which even doesn't have to have GUI interface), there are no additional software dependencies such as libraries or frameworks.
Of course, for an official release, standard command-line installers such as brew or *choco or similar can be used.
Since this is not primarily a technical post, I'll keep this section short as possible and provide some technical details:
-
Backend is implemented with .NET Core 3.1. (started at 1.1. if I remember correctly) - which takes care of data access and connections.
-
All data access for user-related meta-data is done trough the PostgreSQL functions layer that communicates with PostgreSQL internal data and as well with the special schema for pgcode and user data like scripts.
-
Client scripts (JavaScript from generated by TypeScript and CSS generated by SCSS) - are minified and bundled into EXE resource files upon each release build. I've described the technique in the following article.
-
To be able to do that I've built custom builder for the client scripts in NodeJS.
-
To achieve modularity and as well as TypeScript support I've used a modified JavaScript module loader from VS Code (and Monaco editor) which complies with the AMD standard.
-
No 3rd party dependencies are used to so far. Except for the builder part which requires modification libraries.
Given all that PGCODE is pretty extendable in every possible aspect:
-
At the data access layer, by extending or modifying PostgreSQL functions inside pgcode schema. For example, if you need to modify the logic of fetching or saving the user data.
-
At the backend layer by using a standard dependency injection mechanism. For example, it may be possible to inject additional .NET modules (by using DI and configuration files) that will do something upon command execution.
-
At the frontend in every possible part. All you would need is to create a JavaScript module (or generate one from TypeScript) that complies with the AMD specification, specify it as an extension in the configuration file - and the module loader would be able to load it dynamically when it is needed. This can extend the UI that can, for example, provide a simple way to introduce things like visualization and charting.
Before I dive into some of the UI features, please note that this is a prototype which means that some features may not be completely implemented at this point. Point of this article is to introduce this interesting project and hopefully receive some feedback from interested IT professionals.
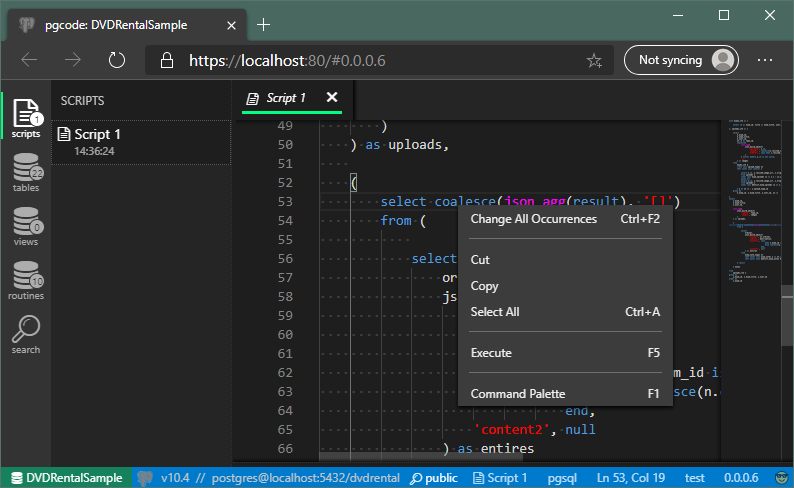
-
UI has a button bar, which acts like switches on the left side which controls the sidebar on the left. Pretty standard stuff.
-
The sidebar can be resized or collapsed and both - button bar and sidebar - can be moved to the right, depending on the user preferences.
-
All positions and states of all splitters (vertical or horizontal) are remembered instantly for the user and restored on restart.
-
All tabs are draggable and their position is re-arrangeable, and again, settings are remembered instantly for the user and restored on restart.
-
There is a built-in mechanism to change a theme (light or dark for now), but so far now only dark has been properly tested (this is a single-person side project after all). Lately, I was thinking to implement a feature that theme can depend on the selected connection. So it would be easy to visually distinguish connections as you work (it may have happened once or twice that I might mix up development from production).
-
The connection selection menu is that green part of the footer on the left side:
- Each connection has its unique color assigned and applied to the specific parts of the UI that are related to that color. In this example, the connection named DVDRentalSample on schema public is marked with bright green color and that reflects on current button switch (indicating that we are seeing tables for that connection) and current tab as well (indicating that script with that tab will run on that connection):
- Also, you may select the working schema from the footer menu:
- Switch buttons are also showing the number of contained objects in a button label. In this example 1 script, 22 tables, 0 views, and 10 routines. Very useful to get an idea of what's in there when you change your connection.

- All panes have a group menu and an individual menu for individual items (some functionalities may not be completely implemented at the moment of this writing):
- Scripts pane contains a list of script objects. It also displays a date and time of last modification and additional comments if any:
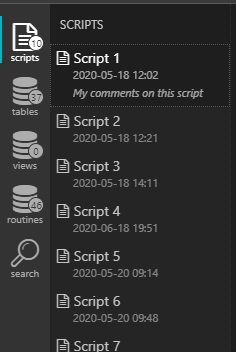
-
Note: currently editing script names and adding comments is not implemented. It is, however, in the previous, abandoned version as an inline edit feature. I'm still not exactly sure what it would be the better - and inline editor or a nice modal popup. This is an example where I'd like to hear some other opinions.
-
Table pane contains a list of available tables. It also displays table count estimation (table count from last analysis operation) and table comment if it exists in the database. A screenshot shows table items with table estimations and with one table comment on the table actor (created by using "comment on" PostgreSQL), together with the mouse hint for the first item.
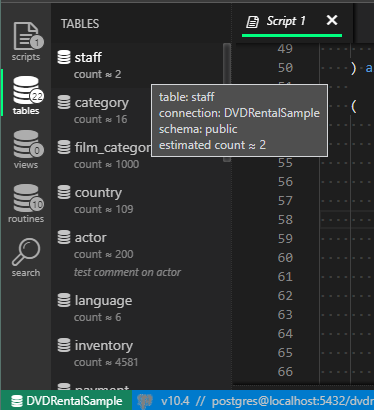
- Two notes on table items (and views):
-
Count estimates are exact at the time of last "analyze" command over each table.
-
Currently, a preview of the selected table (or view) isn't completely finished, but I'm in favor of the idea to just create a new script with a "create" statement. Once again, any feedback from the interested IT professionals is welcome.
- Similarly, switch routines works in a similar fashion - it shows a list of routines (functions or procedures) available on the connection. But this with a little more data, like - ** routine signature, language (SQL, PLPGSQL, C, JavaScript), type (FUNCTION or PROCEDURE), return type and optional comment**:
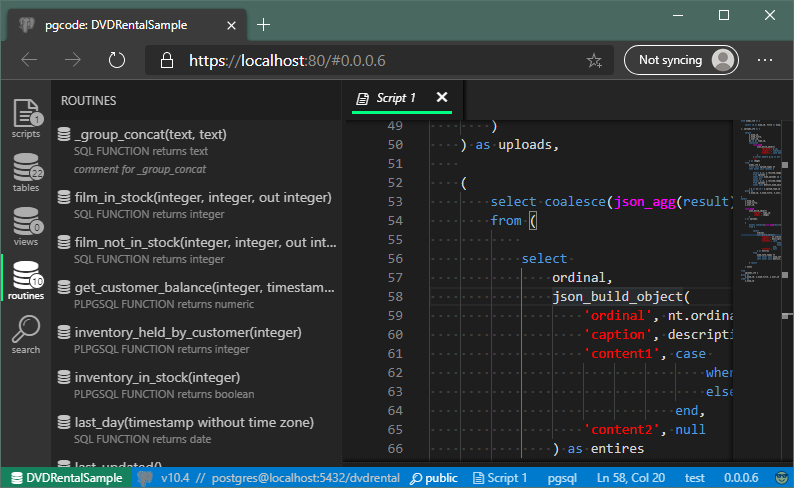
Next steps for this area of the application would be a couple of things still left unfinished, like
-
Filtering by any of those items, sorting, moving and keyboard navigation
-
Additional switches like temporary tables for the selected script/connection and script history.
However, a more important feature that should be next is - the execution.
I've been working on this project, with a couple of longer breaks for years now. I've been doing it before the regular working hours, after the regular working hours, over weekends and otherwise crazy times which I should be spending with my family and friends to be completely honest. And it was even abandoned and resurrected a couple of times. With some features even implemented in different versions.
Problem is that I can't let it go, because it is interesting and the prototype works so nice that I just want to be able to start using it properly.
Now, what I'd like to do is not just continue adding features, but also, as I add new ones share it with public and potentially interested IT professionals or anyone interested in this project.
As the feature itself goes, it is the execution part that is next.
My idea (and some doubts) are the following:
-
I'd allow the execution of only selected text. If someone wants to execute the entire script he or she would have to "select all" text in the script first.
-
If "execute" (F5) command is issued and no text is selected I'd want to have "select all" first automatically with a user message. If the user hits ESC at that moment he or she can resume editing without execution, otherwise, he or she needs to hit F5 (execute) again. Or maybe not, that's just an idea.
-
I'm not sure should I use HTML TABLE element or CSS GRID to render the results.
-
It should most definitely be done trough web sockets (SignalR) streaming, not to consume system resources too much. Or maybe even using the new gRPC-Web protocol, I don't know. I've worked with SingalR before, so...
-
This part should have a tab system as the first example of a plugin system. The idea is to be able to simply save a JavaScript file that complies with AMD standard in the same dir as executable and module loader should pick it up easily. Such a plugin could create new tabs on execution pane and/or hook to execution to produce some wonderful JavaScript charting and visualization.
As the progress for this project continues I tend to continue to produce new blogs in a hope that I'll get some feedback from the community. But, please understand that this is not my primary line of work because I'm mostly engaged in financially viable products.
PGCODE is open source and it shall remain as such.
I'll also strongly consider opening a crowdfunding page for this project if feedback indicates usefulness and viability.
Because there is nothing more I'd like than to make this project my full-time job.