dictionary
- Control Service
- Data Job
- Data Job Arguments
- Data Job Attempt / Data Job Run
- Data Job Deployment
- Data Job Execution
- Data Job Properties
- Data Job Step
- Data Job Source
- Data Job Secrets
- OpId, ExecutionId, AttemptId
- VDK
- VDK DAG
- VDK Plugins
The Control Service provides all the horizontal components required to configure and run data jobs on any cloud: the UI, and REST APIs for deployment, execution, properties, and secrets. Also job scheduling, logging, alerting, monitoring etc. It is tightly coupled with Kubernetes and relies on the Kubernetes ecosystem for many of its functionalities.
Data processing unit that allows data engineers to implement automated pull ingestion (E in ELT) or batch data transformation into Data Warehouse (T in ELT). At the core of it, it is a directory with different scripts and inside of it.
A Data Job Execution or Data Job Run can accept any number of arguments when started. Those are unique for each execution/run. They are usually used when Execution
A single run of a Data Job. Data Job run is usually referred to when a Data Job is executed locally. A job may have multiple attempts (or runs) in a job execution.
See Data Job Execution.
See opid-executionid-attemptid diagram.
Deployment takes both the build/code and the deployment-specific properties, builds and packages them and once a Data Job is deployed, it is ready for immediate execution in the execution environment. It can be scheduled to run periodically.
An instance of a running Data Job deployment is called an execution.
Data Job execution can run a Data Job one or more times. If a run (attempt) fails due to a platform error, the job can be automatically re-run (this is configurable by Control Service operators).
This is applicable only for executions in the "Cloud" (Kubernetes). Local executions always comprise of a single attempt.
See Data Job Attempt.
See opid-executionid-attemptid diagram.
is triggered manually by user or when user is developing locally.
Any saved state, configuration, and (low sensitive) secrets of a Data Job. Those are tracked per deployment. They can be used across different job executions. In the future, they should also be versioned.
They can be accessed using IProperties python interface within a data job or CLI vdk properties command.
A single unit of work for a Data Job. Which data job scripts or files are considered steps and executed by vdk is customizable.
By default (in vdk-core) there are 2 types of steps: SQL steps (SQL files) and Python steps (Python files implementing run(job_input) method).
By default (in vdk-core) steps are executed in an alphanumerical order of their file names.
Plugins can provide different types of steps or change execution order.
When installed vdk-notebook plugin provides support for running VDK productionized notebook files and cells as Data Job steps.
All Python, SQL files, and requirements.txt, and other files of the Data Job. These are versioned and tracked per job.
Used for any sensitive configuration data of a Data Job. Those are tracked per deployment. They can be used across different job executions.
They can be accessed using ISecrets python interface within a data job or CLI vdk secrets command.
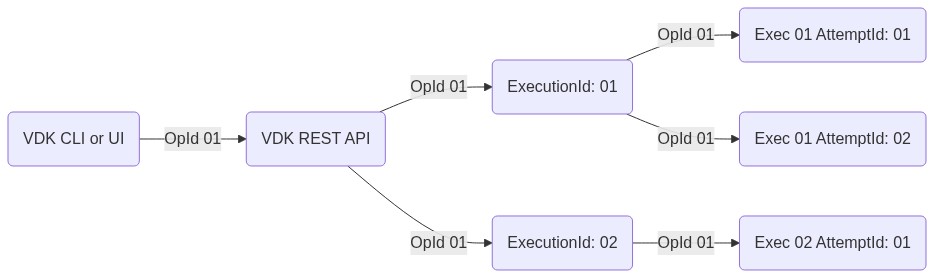
OpId identifies the trigger that initiated the job operation(s). OpID is similar to trace ID in open tracing. It enable tracing multiple operations across different services and datasets. For example, it is possible to have N jobs with the same OpID (if Job1 started Job2 then Job1.opId = Job2.opId). In HTTP requests it is passed as header 'X-OPID' by the Control Service. In SDK see OP_ID config option.
For ExecutionId - see definition of Execution.
For AttemptId - see definition of Attempt.
VDK is Versatile Data Kit SDK.
It provides common functionality for data ingestion and processing and CLI for managing lifecycle of a Data Job (see Control Service).
DAG stands for directed acyclic graph. It represents a structure of Data Jobs with dependencies between them.
The vdk-dag plugin allows job dependencies to be expressed in a DAG structure. See the example for more details.
Versatile Data Kit provides a way to extend or change the behavior of any SDK command using VDK Plugins. One can plugin into any stage of the job runtime. For a list of already developed plugins see plugins directory here. For how to install and develop plugin see plugin doc.