DeferredShading
接下来开始在SRP中实现一下分块延迟渲染功能。
首先列一下分块延迟渲染的流水线:
- 渲染一遍场景生成GBuffer
- 对屏幕进行分块(例如16x16/32x32 pixel),从这些Tile出发,可以将视锥分割成相同数目的子视锥
- 对场景灯光包围盒与Tile对应的子视锥进行相交测试,建立起每个Tile对应的灯光索引列表
- 在最后的LightPass中,读取GBuffer中的信息、以及像素对应的灯光信息,进行光照着色计算
也即:
Rendering GBuffer -> Tile Light Culling -> Light Pass
本文会分几个部分讨论:
- GBuffer的生成和Normal的Pack
- LightPass进行光照着色
- 使用ComputeShader实现屏幕分块光源剔除(只考虑PointLight)
- 实现过程中的一些疑问
先放个动图吧,Gif压的很残,就表达个意思。这里放了256盏Point Light.

GBuffer实际上由多张RenderTexture构成,每张RT中存储的数据通常要根据后期着色的需求进行填充,但大致会包括Normal、Albedo。如果是PBR光照模型的话,还会包括Metalness,Roughness等等。
为了能在一个Pass中,把这么多数据同时渲染到多张RT中,就需要GPU支持MRT(Multiple Render Targets)这个功能。
在Unity中,我们可以通过 SystemInfo.supportedRenderTargetCount来确定设备是否支持我们所需要的MRT。
当然也有人尝试把所有的数据压缩到一张RT里,这样就不再需要MRT的支持,但是最终效果如何只能实际测试看效果了。
在SRP中设置MRT比较简单,只要申请多张相应格式的RT,然后通过接口
CommandBuffer.SetRenderTarget(RenderTargetIdentifier[] colors, RenderTargetIdentifier depth);进行设置即可。
在本Demo中,对GBuffer的规划如下:
普通模式:
GBuffer1 - |Albedo(24bit)|metalness(8bit)|
GBuffer2 - |Normal(24bit)|roughness(8bit)|
高精度法线模式:
GBuffer1 - |Albedo(24bit)|metalness(8bit)|
GBuffer2 - |PackedNormal(32bit)|
GBuffer3 - |暂无用(24bit)|roughness(8bit)|
可以看出现在数据还是比较简单的,后期根据渲染需求可能还要增加AO、Emissive等数据。GBuffer中没有Position数据,因为Position在后期可以通过Depth和UV重建出来。
GBuffer Pass的Shader实现也是非常简单的,首先定义Frag的输出结构。
struct GBufferOutput
{
half4 GBuffer0 : SV_Target0;
half4 GBuffer1 : SV_Target1;
half4 GBuffer2 : SV_Target2;
half4 GBuffer3 : SV_Target3;
};然后在片段着色器里,读取物体的各种属性,填充入GBufferOutput即可。
例如GBuffer0的填充代码如下:
GBufferOutput o;
o.GBuffer0 = half4(pbrInput.albedo,pbrInput.metalness);往GBuffer中填充法线信息的时候,最直接的一种方式自然是xyz三个分量各用8bit存储。转换公式如下:
///将normal分量从[-1,1]映射到[0,1]
static half3 PackNormal(half3 normalWS){
return normalWS * 0.5 + 0.5;
}
//将c的分量从[0,1]映射到[-1,1]
static half3 UnpackNormal(half3 c){
return c * 2 - 1;
}这种方式虽然简单,但是每个分量只能表达256阶,法线精度是很差的。在实际的渲染效果里,高光效果会有很明显的块状现象,如下:

为了解决这个问题,人们想了很多算法来把法线信息以尽量高精度的方式存储到有限的GBuffer中。在[1]A Survey of Efficient Representations for Independent Unit Vectors, 2014这篇paper中,列举了很多种法线映射算法,比对测试了它们的误差以及Encode/Decode性能,值得一看。作者最后得出的结论是Oct映射和Spherical映射是比较好的算法。因此这里着重说一下Oct映射算法,本Demo也会用此算法来实现。
Oct法线映射算法用一张图来表示如下:
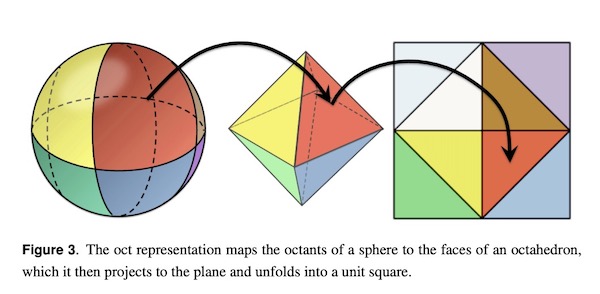
我们用单位球面上的一个点来表示一个单位方向向量。第一步先将这个点映射到一个八面体上。假设p为球面上的点,v为其映射到八面体上的点,那么它们满足映射公式如下:
第二步是将八面体上的点映射到一个2x2的正方形内,这一步可以想象成是UV展开。很明显(这里我们视z轴朝上),当v.z > 0时,v.xy就是正方形内的映射坐标(想象成把八面体上半部分拍平到xy平面上)。而八面体的下半部分,即v.z < 0时,则按对角线翻转到外侧。
假设正方形内的映射点为w,那么v和w满足映射公式如下:
if(v.z > 0){
w = v.xy;
}else{
half2 signValue = (v.xy > 0? 1:-1);
w = (1 - abs(v.yx)) * signValue;
}注意根据v.xy正负号的不同,signValue有(1,1),(1,-1),(-1,1),(-1,-1)四种情况,对应了四个象限的展开。
以上映射公式实际上可以给出更详尽的推导过程,以后有空再专门开一篇写好了。这里给出完整的Encode和Decode代码:
static half2 PackNormalOct(half3 normalWS){
half l = dot(abs(normalWS),1); //l = abs(x) + abs(y) + abs(z)
half3 normalOct = normalWS * rcp(l); //投影到八面体
if(normalWS.z > 0){ //八面体的上部分投影到xy平面
return normalOct.xy;
}else{ //八面体下部分按对角线翻转投影到xy平面
return (1 - abs(normalOct.yx)) * SignNotZero(normalOct.xy);
}
}
static half3 UnpackNormalOct(half2 e){
half3 v = half3(e.xy,1 - abs(e.x) - abs(e.y));
if(v.z <= 0){
v.xy = SignNotZero(v.xy) *(1 - abs(v.yx));
}
return normalize(v);
}
上面的代码还可以改写成性能更好(但阅读性更差)的版本,但本项目以学习思路为主,因此优先照顾可读性。
使用Oct映射,法线信息被映射到两个分量。我们可以用16+16 = 32bit来保存这两个分量(对应的GBuffer格式为RG32),也可以使用12+12=24bit来保存这两个分量(需要手动Pack到RGB分量中)。本项目直接使用了32bit来保存。
高精度的法线高光效果,如丝般顺滑:

在GBuffer填充完毕之后,为了测试GBuffer Encode和Decode的正确性,我们通常会实现一个DebugPass,将GBuffer中保存的信息Decode出来,每个分量单独渲染到画面上进行Debug。
例如测试场景的Albedo信息输出如下:

Normal信息如下

Metalness:

还roughness,position等等就不贴了。
接下来我们需要在LightPass中,利用Gbuffer中的这些数据,来计算光照着色。
我们通常往全屏绘制一个方块来开始Light Pass阶段着色。 在SRP中可以通过如下方式向全屏绘制一个方块:
public void Execute(ScriptableRenderContext context){
if(!_lightPassMat){
_lightPassMat = new Material(Shader.Find("Hidden/SRPLearn/DeferredLightPass"));
}
if(!_fullScreenMesh){
_fullScreenMesh = Utils.CreateFullscreenMesh();
}
_commandbuffer.Clear();
_commandbuffer.SetViewProjectionMatrices(Matrix4x4.identity,Matrix4x4.identity);
_commandbuffer.DrawMesh(_fullScreenMesh,Matrix4x4.identity,_lightPassMat,0,0);
context.ExecuteCommandBuffer(_commandbuffer);
}_lightPassMat为LightPass阶段要使用的材质。
在Deferred Shading里,平行光的实现是比较简单的,因为它会影响屏幕中的所有像素,因此也就无需考虑灯光裁剪之类的。
在Light Pass Shader的Frag中,我们首先从GBuffer中提取PBR渲染需要的数据:
float2 uv = input.uv;
float depth = _XDepthTexture.Sample(sampler_pointer_clamp,input.uv).x;
half4 g0 = _GBuffer0.Sample(sampler_pointer_clamp,input.uv);
half4 g1 = _GBuffer1.Sample(sampler_pointer_clamp,input.uv);
half4 g2 = _GBuffer2.Sample(sampler_pointer_clamp,input.uv);
half4 g3 = _GBuffer3.Sample(sampler_pointer_clamp,input.uv);
PBRShadeInput shadeInput;
float3 positionWS = ReconstructPositionWS(uv,depth);
shadeInput.positionWS = positionWS;
DecodeGBuffer(shadeInput,g0,g1,g2,g3);然后拿到平行光的数据,只需要方向和颜色(这里还加入了阴影计算):
ShadeLightDesc mainLightDesc = GetMainLightShadeDescWithShadow(shadeInput.positionWS,shadeInput.normal);然后进行标准的PBR着色就可以了。
//着色点几何信息
DECLARE_SHADE_POINT_DESC(sPointDesc,shadeInput);
//pbr材质相关
DECLARE_PBR_DESC(pbrDesc,shadeInput);
//平行光
ShadeLightDesc mainLightDesc = GetMainLightShadeDescWithShadow(shadeInput.positionWS,shadeInput.normal);
color = PBRShading(pbrDesc,sPointDesc,mainLightDesc);
很明显,我们不能将所有的像素和所有的点光源进行一一对比计算。因为点光源的影响范围通常是有限的,它只能照亮局部的像素。如果将全屏的像素都与其做比较,且不说存在大量无用计算,当同屏的点光源达到数百级别时,我们也不大可能在pixel shader里写出for 100这种代码。
对这种局部光源(包括Spot Light)的优化思路,其中之一是通过一种叫Light Volume Stencil Buffer的方式去做。其思路其实跟Shadow Volume有点类似,都是利用Stencil Buffer去模拟计算视线穿过Light Volume的情况。如果视线对于Light Volume只进不出,那么说明这个像素是被光照亮的,否则不受光源影响。

完整的思路可以看这篇[2] Yuriy O'Donnell, Rendering deferred lights using Stencil culling algorithm, 2009
Light Volume + Stencil Buffer的方案缺陷在于一个像素可能会产生多次对GBuffer的读取。
URP的最新版本里也实现了Deferred Shading,目前是用Light Volume的方案实现的,我瞄了一下源码,发现Tile Based方案也在路上了,只不过还没开放出来。
Tile Based方案的思路是,将屏幕分割成许许多多的小格子,然后针对每个格子做光源剔除,这样就为每个格子得到了Visible Lights列表。在LightPass阶段,我们只要判断当前像素属于哪个格子,仅与当前格子的灯光列表做光照计算即可。
这个Tile based Light Culling,即可以由CPU做,也可以由GPU做。例如URP中正在实现的方案,是用JobSystem多线程CPU去剔除的,因为URP这个管线的目标就是通用化,需要照顾设备兼容性,因此不会采用ComputeShader。
在支持ComputeShader的GPU上,更常见的应该是使用ComputeShader进行光源剔除。这也是本项目的实现方案。
方案主要参考为[3] Johan Andersson, DirectX 11 Rendering in BF3, 2012
我们首先会从CPU端提供一份全局点光源信息:
StructuredBuffer<float4> _LightPositionAndRanges;
StructuredBuffer<half4> _LightColors;
uniform uint _LightCount基础版本流程如下:
- 将屏幕按照16x16 pixel分块,每个ThreadGroup的线程数量也为16x16x1。因此每个ThreadGroup对应一个Tile。
- 在Stage1,每个Thread代表一个像素。读取DepthTexture,然后利用InterlockedMin/InterlockedMax可以计算出每个Tile的Min/Max Depth
- 在Stage2,每个Thread代表一个Light,因此一次性可以进行16x16=256盏灯光与Tile的相交测试。如果超出256,就for一下。
- 在Stage3,每个Thread代表一个像素,与stage2中生成的光照列表进行着色计算,写入到RenderTexture中。
每个ThreadGroup在share空间定义如下变量来记录该tile的相交光源索引:
groupshared uint tileVisibleLightCount = 0;
groupshared uint tileVisibleLightIndices[MAX_LIGHT_COUNT];剔除过程用伪代码表示如下:
[numthreads(THREAD_NUM_X,THREAD_NUM_Y,1)]
void CSMain (uint3 id : SV_DispatchThreadID,uint3 groupId:SV_GROUPID, uint groupIndex:SV_GROUPINDEX){
//1. 初始化groupshared 变量
if(groupIndex == 0){
InitGroupSharedVars();
}
GroupMemoryBarrierWithGroupSync();
//2. 计算tile的min/max depth
InterlockedMin(tileDepthMin,asuint(linearDepth));
InterlockedMax(tileDepthMax,asuint(linearDepth));
GroupMemoryBarrierWithGroupSync();
//3. 切换到每个线程代表一个灯光,与tile进行求交,如果灯光超过256,就分多个pass计算
uint passCnt = ceil(totalLightCount / THREAD_COUNT);
for(uint passIdx = 0; passIdx < passCnt; passIdx ++){
uint lightIndex = passIdx * THREAD_COUNT + groupIndex;
if(lightIndex < totalLightCount){
float4 lightSphere = _Lights[lightIndex];
if(Intersect(tileFrustum,lightSphere)){
uint offset;
InterlockedAdd(tileVisibleLightCount,1,offset);
tileVisibleLightIndices[offset] = lightIndex;
}
}
}
GroupMemoryBarrierWithGroupSync();
//4. 切换到每个线程代表一个像素,进行光照计算
half4 color = 0;
GBuffer gbuffer = ReadGBuffer(id.xy);
for(uint i = 0;i < tileVisibleLightCount; i ++){
LightInfo lightInfo = GetLightInfo(tileVisibleLightIndices[i]);
color += PBRShading(gbuffer,lightInfo);
}
_OutTexture[id.xy] = color;
}在原版的方案里,光照着色是直接用Compute Shader实现的,也就是在以上的Light Culling完成之后,直接在ComputeShader里读取GBuffer进行光照着色计算。
我们也可以把光照剔除结果写入RWBuffer后,交给Graphic Pipeline去实现光照着色。
本项目两种方案都会进行实现,后面会同步罗列一下遇到的问题。
我们使用16x16 pixel作为一块,那么屏幕可以总共被分割为如下多块。
var screenWidth = camera.pixelWidth;
var screenHeight = camera.pixelHeight;
var tileCountX = Mathf.CeilToInt(screenWidth * 1f / tileSizeX);
var tileCountY = Mathf.CeilToInt(screenHeight * 1f / tileSizeY);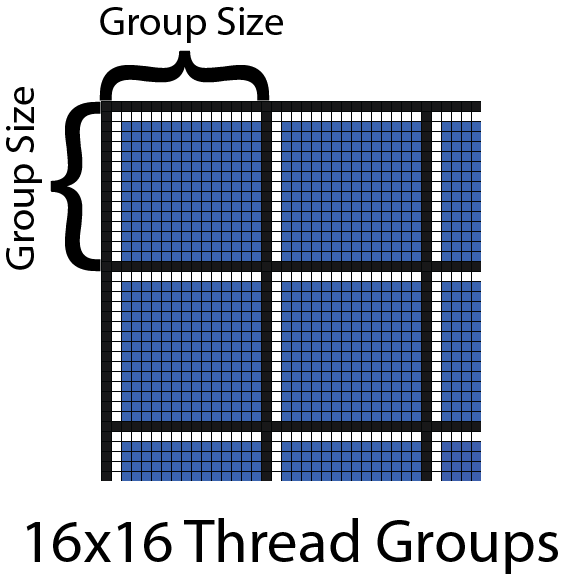
为了建立起每个块对应的视锥信息,我们需要对摄像机近平面进行相同的分割。
首先我们可以拿到近平面的宽高信息:
var camera = cameraDes.camera;
var nearPlaneZ = camera.nearClipPlane;
var nearPlaneHeight = Mathf.Tan(Mathf.Deg2Rad * camera.fieldOfView * 0.5f) * 2 * camera.nearClipPlane;
var nearPlaneWidth = camera.aspect * nearPlaneHeight;然后在ViewSpace拿到近平面左下角坐标:
var CameraNearPlaneLB = new Vector3( - nearPlaneWidth/2,-nearPlaneHeight/2,nearPlaneZ);以及近平面水平和垂直两个方向向量,向量长度对应一个Tile的大小:
var basisH = new Vector2(tileSizeX * nearPlaneWidth / screenWidth,0);
var basisV = new Vector2(0,tileSizeY * nearPlaneHeight / screenHeight);这样我们就能构建出近平面的Tile分割
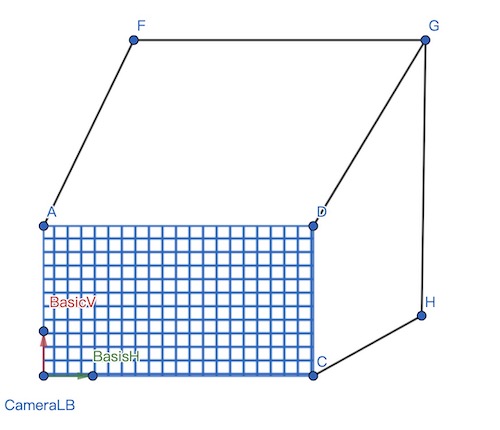
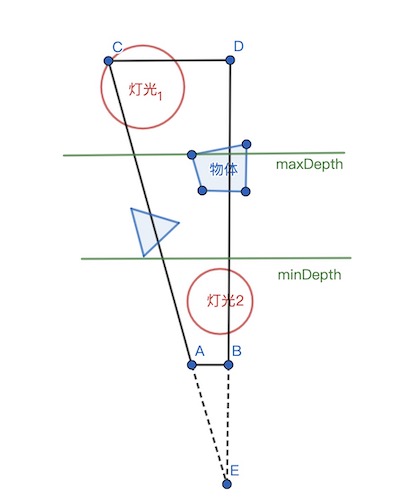
利用视锥相似三角形的特性,我们同样可以得到每个Tile对应的远平面的4个顶点。
但是如果直接使用摄像机近/远平面构建Tile视锥包围盒的话,裁剪效率不会很高,
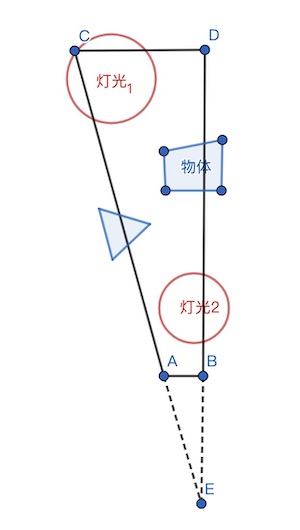
例如在一个Tile视锥里,场景物体实际上只分布于局部的深度范围,如果我们用摄像机的近/远平面构建包围盒与灯光求交,就会得到大量无用的灯光,例如上图中的灯光1和灯光2。
为了优化这个问题,于是就引入了Min/Max Depth计算。
这个过程是比较简单的,首先Group中的每个线程代表一个像素,从DepthTexture中读取它们对应的深度值,与groupshared变量进行InterlockedMin/InterlockedMax计算即可。注意这里要将depth转到LinearEyeSpace。
bool inScreen = (float)id.x < _ScreenParams.x && (float)id.y < _ScreenParams.y;
//stage 2. 计算tile的min/max depth
float depth = 0;
float linearDepth = 0;
if(inScreen){
depth = _XDepthTexture[id.xy].r;
#if UNITY_REVERSED_Z
linearDepth = LinearEyeDepth(1 - depth);
#else
linearDepth = LinearEyeDepth(depth);
#endif
InterlockedMin(tileMinDepthInt,asuint(linearDepth));
InterlockedMax(tileMaxDepthInt,asuint(linearDepth));
}
GroupMemoryBarrierWithGroupSync();有了Min/Max Depth,我们就知道了每个Tile中物体的深度分布情况:
我们利用min/max depth作为Tile视锥的近/远平面构建包围盒与灯光求交,这样就能排除掉很多无用的灯光。
对于点光源,我们可以对其建立球形包围盒。因此这个问题就等于视锥体与球形包围盒求交计算。
首先,由于近/远平面是坐标轴对齐的,因此我们可以快速的通过z轴先进行第一遍过滤:
//tileFrustumCorners是tile视锥minDepth平面的4个顶点
bool Intersect(float3 tileFrustumCorners[4],float4 lightSphere){
float tileDepthMin = asfloat(tileMinDepthInt);
float tileDepthMax = asfloat(tileMaxDepthInt);
float lightRadius = lightSphere.w;
float lightDepthMin = lightSphere.z - lightRadius;
float lightDepthMax = lightSphere.z + lightRadius;
if(lightDepthMin > tileDepthMax || lightDepthMax < tileDepthMin){
return false;
}
//....
}接下来就是侧方的4个平面。一种思路是依次计算球心到4个平面的有向距离,看其是否大于球半径。如果是,那么不相交,否则认为相交。
单个侧平面相交性计算代码如下:
//p1,p2与摄像机(0,0,0)三点构成了视锥侧平面
bool IntersectSide(float3 p1,float3 p2,float4 lightSphere){
float3 n = -normalize(cross(p1,p2));
float d = dot(lightSphere.xyz,n);
return d < lightSphere.w;
}4个平面合起来就是:
IntersectSide(tileFrustumCorners[0],tileFrustumCorners[1],lightSphere)
&& IntersectSide(tileFrustumCorners[1],tileFrustumCorners[2],lightSphere)
&& IntersectSide(tileFrustumCorners[2],tileFrustumCorners[3],lightSphere)
&& IntersectSide(tileFrustumCorners[3],tileFrustumCorners[0],lightSphere);如果我们把每个Tile相交的灯光数量用灰度渲染出来,效果图如下:
可以发现其实误差还是一些的,在球体很大而视锥很小的情况下,4个角落都会成为漏网之鱼。
譬如上图的左下角绿色的Tile,4个平面均与球体相交(从效率上考虑,我们只能判定无限大小的平面与球体是否相交),但实际上这个tile与球体并不相交(因为实际上每个面大小是有限的)。
为了优化这个问题,还有一种方案是对tile视锥在xy平面上的投影建立圆形包围盒,示意图如下:

蓝色方块为minZ平面,绿色方块maxZ平面。minZ和maxZ的定义如下:
float minZ = max(tileDepthMin,lightDepthMin);
float maxZ = min(tileDepthMax,lightDepthMax);我们将minZ/maxZ对应的两个平面的各自4个顶点,投影到xy平面后建立圆形包围盒。同样点光源的球形包围盒在xy平台上的投影也是一个圆形。这样就沦为两个圆形相交判定。
但是计算圆形包围盒的话,求半径会涉及到开方运算。
所以还有一种更快速的方案是建立AABB包围盒。
这样就沦为AABB与圆形相交判定。
考虑到我们当前情形通常是圆很大,AABB很小,因此相交算法我们可以进一步近似为判定AABB是否有任意一个顶点位于圆形内。
实际上我们并不需要真的对每个顶点做检测,而是首先判定圆心位于AABB 4个象限中的哪个,只与对应象限的顶点做判定就行了。
AABB与圆相交判定代码如下:
//aabb.xy为中心,aabb.zw为extents
bool IntersectAABB(float4 aabb,float4 lightSphere){
float2 p = aabb.xy + aabb.zw * sign(lightSphere.xy - aabb.xy);
float2 d = p - lightSphere.xy;
return dot(d,d) < lightSphere.w * lightSphere.w;
}改进后的tile visible lights debug效果:
随机在场景里生成256盏Point Light,看看效果图。

然后输出每个tile的VisibleLightCount(越白表示这个tile相交的灯光数量越多)进行debug一下
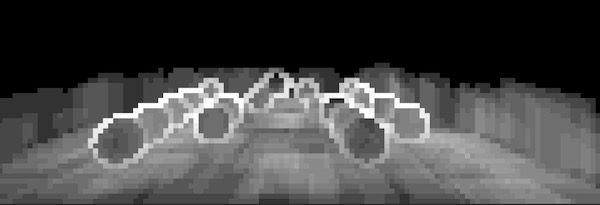
我们会发现物体的边缘特别白。这是因为物体边缘的tile,其min/max depth之差比较大,因此相交的光源更多。
为了更进一步优化这个问题,排除无效的灯光,一种方案是对深度进行分割。
来自 - [4] Takahiro Harada, A 2.5D CULLING FOR FORWARD+, 2012
其原理为,在min/max depth计算结束后,将其切割成32份(示意图只给了8份)。

我们为一个tile定义一个groupshared uint gemoDepthMask,来记录这个tile中像素在32份区间中的分布情况。每个bit代表一个区间,如果是1,就表示有像素落入这个区间,0则表示没有像素落入这个区间。
gemoDepthMask生成代码如下:
float depthSliceInterval = max(0.01,(tileDepthMax - tileDepthMin) / 32.0);
uint depthSliceIndex = floor((linearDepth - tileDepthMin) / depthSliceInterval);
InterlockedOr(gemoDepthMask,1 << depthSliceIndex);
GroupMemoryBarrierWithGroupSync();然后在灯光相交计算阶段,同样为灯光生成一个lightDepthMask:
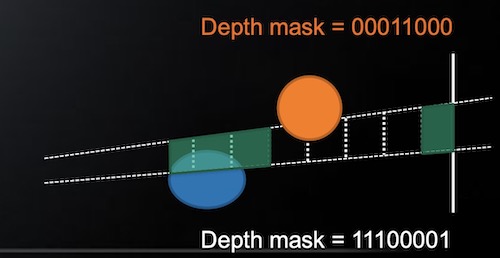
将lightDepthMask与gemoDepthMask按位and,如果是0,则灯光与tile不相交。
这个方案以较小的代价,排除了那些位于两个物体之间,又不与物体交互的灯光。
在加入depth slice功能后,tile visible light count debug效果如下:

很明显,边缘没有那么白了。
接下来说一下实现过程中遇到的一些问题吧。
首先一开始我使用了ComptueShader进行着色。使用CS进行着色的好处是整个流程很顺,无需将保存在groupshared空间的灯光剔除信息写入到Buffer中,再来一次LightPass绘制。
坏处则是在Mobile端可能无法利用On-Chip Memory。根据苹果在[5] Apple, rendering_a_scene_with_deferred_lighting_in_c中所述,其可以利用on-chip memory实现one pass的deferred shading,ComputeShader好像没有这个概念吧?应该只能直接从System Memory读取GBuffer.
另外一个问题是,如果利用ComputeShader进行着色,我们必须为其提供一张Random Write On的RenderTexture。我发现实际渲染出来会有很明显的渐变条纹:

这个可以理解,因为对于一张RGBA32的图,每个分量8bit,只能提供256阶的亮度表现。以上的渐变条纹实际上相当于以下的代码:
_OutTexture[xy] = floor(color * 255) / 255.0;同样的,当我将Graphic Pipeline的RenderTarget设置成Random Write On,也是会出现这样的渐变条纹。但是关闭Random Write后,渐变就很流畅了。

暂不清楚什么原因。。
通常为了避免极端情况,我们需要对每个tile的最大灯光数量进行限制。但是进行限制后,如果一个tile的实际visible lights超过了max被丢弃一部分后,会出现闪烁问题。
这是因为tile与光源求交计算的时候是并行计算的,哪个灯光先完成求交计算,哪个就优先进入到visible lights队列里。因此每次生成的visible lights列表都有一定随机性,就产生了闪烁。
一种解决方案是对每个tile的visible lights进行重要性排序,但这又涉及到GPU并行排序了,比较麻烦。
我看相关的资料都没有提到这个问题,难道是我的实现有什么问题?
Apple在[5]里提到了One Pass Deferred Shading,即将GBuffer保存到OnChipMemory上,这样就解决了Deferred Shading存在的带宽问题。目前暂不知道Unity是否支持这个功能。
Tile based Light Culling同样可以与Forward进行结合,得到Forward+。对于支持HSR的设备(Hidden Surface Removal),首先已经不存在Overdraw的问题了,假如我们使用上一帧的depthTexture来做Tile Light Culing,那么Forward+的优势是否要比Tile based Deferred Shading高很多呢?
unity在2020版本为ComputeShader增加了multi_compile支持,本项目为了做各种方案对比因此加了很多multi_compile选项。在实际产品中应当尽量减少全局的multi_compile,而是使用shader_feature来代替,否则shader变种组合将爆炸式增长。
[1] A Survey of Efficient Representations for Independent Unit Vectors, 2014
[2] Yuriy O'Donnell, Rendering deferred lights using Stencil culling algorithm, 2009
[3] Johan Andersson, DirectX 11 Rendering in BF3, 2012