






Read this in other languages: English.
ZVT是对fooltrader重新思考后编写的量化项目,其包含可扩展的交易标的,数据recorder,api,因子计算,选股,回测,交易,以及统一的可视化,定位为中低频 多级别 多因子 多标的 全市场分析和交易框架。
相比其他的量化系统,其不依赖任何中间件,非常轻,可测试,可推断,可扩展。
编写该系统的初心:
- 构造统一可扩展的数据schema
- 能够容易地把各provider的数据适配到系统
- 相同的算法,只写一次,可以应用到任何市场
- 适用于低耗能的人脑+个人电脑
详细文档有部分已经落后代码,其实认真看完README并结合代码理解下面的几句话,基本上不需要什么文档了
整个架构如图:

扩展应用例子:
策略例子:
市场全景图,后面可能会基于此扩展相关的数据:

zvt旨在帮你更好的理解市场,理清交易思路,验证想法,实盘交易接口可以通过插件的方式来连接交易信号,并不是zvt核心的东西。

策略展示目前只做最重要的事:
- 策略的净值曲线
- 策略交易标的的买卖信号
这里是入口脚本,可直接源码运行;或者pip安装后直接在命令行下输入zvt
然后打开http://127.0.0.1:8050/即可
一个系统,如果5分钟用不起来,那肯定是设计软件的人本身就没想清楚,并且其压根就没打算自己用。
要求python版本>=3.6(建议新建一个干净的virtual env环境)
pip install zvt -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip show zvt
如果不是最新版本
pip install --upgrade zvt -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
请根据需要决定是否使用豆瓣镜像源
In [1]: import os
#这一句会进入测试环境,使用自带的测试数据
In [2]: os.environ["TESTING_ZVT"] = "1"
In [3]: from zvt.api import *
In [4]: df = get_kdata(entity_id='stock_sz_000338',provider='joinquant')
In [5]: df.tail()
Out[5]:
id entity_id timestamp provider code name level open close high low volume turnover change_pct turnover_rate
timestamp
2019-10-29 stock_sz_000338_2019-10-29 stock_sz_000338 2019-10-29 joinquant 000338 潍柴动力 1d 12.00 11.78 12.02 11.76 28533132.0 3.381845e+08 None None
2019-10-30 stock_sz_000338_2019-10-30 stock_sz_000338 2019-10-30 joinquant 000338 潍柴动力 1d 11.74 12.05 12.08 11.61 42652561.0 5.066013e+08 None None
2019-10-31 stock_sz_000338_2019-10-31 stock_sz_000338 2019-10-31 joinquant 000338 潍柴动力 1d 12.05 11.56 12.08 11.50 77329380.0 9.010439e+08 None None
2019-11-01 stock_sz_000338_2019-11-01 stock_sz_000338 2019-11-01 joinquant 000338 潍柴动力 1d 11.55 12.69 12.70 11.52 160732771.0 1.974125e+09 None None
2019-11-04 stock_sz_000338_2019-11-04 stock_sz_000338 2019-11-04 joinquant 000338 潍柴动力 1d 12.77 13.00 13.11 12.77 126673139.0 1.643788e+09 None None
In [12]: from zvt.domain import *
In [13]: df = FinanceFactor.query_data(entity_id='stock_sz_000338',columns=FinanceFactor.important_cols())
In [14]: df.tail()
Out[14]:
basic_eps total_op_income net_profit op_income_growth_yoy net_profit_growth_yoy roe rota gross_profit_margin net_margin timestamp
timestamp
2018-10-31 0.73 1.182000e+11 6.001000e+09 0.0595 0.3037 0.1647 0.0414 0.2164 0.0681 2018-10-31
2019-03-26 1.08 1.593000e+11 8.658000e+09 0.0507 0.2716 0.2273 0.0589 0.2233 0.0730 2019-03-26
2019-04-29 0.33 4.521000e+10 2.591000e+09 0.1530 0.3499 0.0637 0.0160 0.2166 0.0746 2019-04-29
2019-08-30 0.67 9.086000e+10 5.287000e+09 0.1045 0.2037 0.1249 0.0315 0.2175 0.0759 2019-08-30
2019-10-31 0.89 1.267000e+11 7.058000e+09 0.0721 0.1761 0.1720 0.0435 0.2206 0.0736 2019-10-31
In [15]: from zvt.samples import *
In [16]: t = MyMaTrader(codes=['000338'], level=IntervalLevel.LEVEL_1DAY, start_timestamp='2018-01-01',
...: end_timestamp='2019-06-30', trader_name='000338_ma_trader')
In [17]: t.run()
测试数据里面包含的SAMPLE_STOCK_CODES = ['000001', '000783', '000778', '603220', '601318', '000338', '002572', '300027'],试一下传入其任意组合,即可看多标的的效果。
项目支持多环境切换,默认情况下,不设置环境变量TESTING_ZVT即为正式环境
In [1]: from zvt import *
{'data_path': '/Users/xuanqi/zvt-home/data',
'domain_module': 'zvt.domain',
'email_password': '',
'email_username': '',
'http_proxy': '127.0.0.1:1087',
'https_proxy': '127.0.0.1:1087',
'jq_password': '',
'jq_username': '',
'log_path': '/Users/xuanqi/zvt-home/logs',
'smtp_host': 'smtpdm.aliyun.com',
'smtp_port': '80',
'ui_path': '/Users/xuanqi/zvt-home/ui',
'wechat_app_id': '',
'wechat_app_secrect': '',
'zvt_home': '/Users/xuanqi/zvt-home'}
如果你不想使用使用默认的zvt_home目录,请设置环境变量ZVT_HOME再运行。
所有操作跟测试环境是一致的,只是操作的目录不同。
在zvt_home目录中找到config.json进行配置:
- jq_username 聚宽数据用户名
- jq_password 聚宽数据密码
- smtp_host 邮件服务器host
- smtp_port 邮件服务器端口
- email_username smtp邮箱账户
- email_password smtp邮箱密码
- wechat_app_id
- wechat_app_secrect
链接: https://pan.baidu.com/s/16BZOkEY2PBTkixJgzls66w 提取码: gfxc
里面包含joinquant的日/周线前/后复权数据,eastmoney的财务,分红,大股东,高管持仓等数据。
把下载的数据解压到正式环境的data_path(所有db文件放到该目录下,没有层级结构)
数据的更新是增量的,下载历史数据只是为了节省时间,全部自己更新也是可以的。
项目数据支持多provider,在数据schema一致性的基础上,可根据需要进行选择和扩展,目前支持新浪,东财,交易所等免费数据。
但免费数据的缺点是显而易见的:不稳定,爬取清洗数据耗时耗力,维护代价巨大,且随时可能不可用。
个人建议:如果只是学习研究,可以使用免费数据;如果是真正有意投身量化,还是选一家可靠的数据提供商。
项目支持聚宽的数据,可戳以下链接申请使用(目前可免费使用一年)
https://www.joinquant.com/default/index/sdk?channelId=953cbf5d1b8683f81f0c40c9d4265c0d
项目中大部分的免费数据目前都是比较稳定的,且做过严格测试,特别是东财的数据,可放心使用
添加其他数据提供商�,请参考数据扩展教程
下面介绍如何用一种统一的方式来回答三个问题:有什么数据?如何更新数据?如何查询数据?
In [1]: from zvt.contract import zvt_context
In [2]: from zvt.domain import *
In [3]: zvt_context.schemas
[zvt.domain.dividend_financing.DividendFinancing,
zvt.domain.dividend_financing.DividendDetail,
zvt.domain.dividend_financing.SpoDetail...]
zvt_context.schemas为系统支持的schema,schema即表结构,即数据,其字段含义的查看方式如下:
- 源码
domain里的文件为schema的定义,查看相应字段的注释即可。
- help
输入schema.按tab提示其包含的字段,或者.help()
In [4]: FinanceFactor.help()
#股票列表
In [2]: Stock.record_data(provider='eastmoney')
#财务指标
In [3]: FinanceFactor.record_data(codes=['000338'])
#资产负债表
In [4]: BalanceSheet.record_data(codes=['000338'])
#利润表
In [5]: IncomeStatement.record_data(codes=['000338'])
#现金流量表
In [5]: CashFlowStatement.record_data(codes=['000338'])
其他�数据依样画葫芦即可。
注意可选参数provider,其代表数据提供商,一个schema可以有多个provider,这是系统稳定的基石。
查看已实现的provider
In [12]: Stock.provider_map_recorder
Out[12]:
{'joinquant': zvt.recorders.joinquant.meta.china_stock_meta_recorder.JqChinaStockRecorder,
'exchange': zvt.recorders.exchange.china_stock_list_spider.ExchangeChinaStockListRecorder,
'eastmoney': zvt.recorders.eastmoney.meta.china_stock_meta_recorder.EastmoneyChinaStockListRecorder}
你可以使用任意一个provider来获取数据,默认使用第一个。
再举个例子,股票板块数据获取:
In [13]: Block.provider_map_recorder
Out[13]:
{'eastmoney': zvt.recorders.eastmoney.meta.china_stock_category_recorder.EastmoneyChinaBlockRecorder,
'sina': zvt.recorders.sina.meta.sina_china_stock_category_recorder.SinaChinaBlockRecorder}
In [14]: Block.record_data(provider='sina')
Block registered recorders:{'eastmoney': <class 'zvt.recorders.eastmoney.meta.china_stock_category_recorder.EastmoneyChinaBlockRecorder'>, 'sina': <class 'zvt.recorders.sina.meta.sina_china_stock_category_recorder.SinaChinaBlockRecorder'>}
2020-03-04 23:56:48,931 INFO MainThread finish record sina blocks:industry
2020-03-04 23:56:49,450 INFO MainThread finish record sina blocks:concept
再多了解一点record_data:
- 参数codes代表需要抓取的股票代码
- 不传入codes则是全市场抓取
- 该方法会把数据存储到本地并只做增量更新
定时任务的方式更新可参考东财数据定时更新
2018年年报 roe>8% 营收增长>8% 的前20个股
In [38]: df=FinanceFactor.query_data(filters=[FinanceFactor.roe>0.08,FinanceFactor.report_period=='year',FinanceFactor.op_income_growth_yoy>0.08],start_timestamp='2019-01-01',order=FinanceFactor.roe.desc(),limit=20,columns=[FinanceFactor.code]+FinanceFactor.important_cols(),index='code')
In [39]: df
Out[39]:
code basic_eps total_op_income net_profit op_income_growth_yoy net_profit_growth_yoy roe rota gross_profit_margin net_margin timestamp
code
000048 000048 1.1193 3.437000e+09 4.374000e+08 1.2179 3.8122 0.5495 0.0989 0.4286 0.1308 2019-04-15
000629 000629 0.3598 1.516000e+10 3.090000e+09 0.6068 2.5796 0.5281 0.2832 0.2752 0.2086 2019-03-26
000672 000672 1.8100 5.305000e+09 1.472000e+09 0.1563 0.8596 0.5047 0.2289 0.4670 0.2803 2019-04-11
000912 000912 0.3500 4.405000e+09 3.516000e+08 0.1796 1.2363 4.7847 0.0539 0.2175 0.0795 2019-03-20
000932 000932 2.2483 9.137000e+10 6.780000e+09 0.1911 0.6453 0.4866 0.1137 0.1743 0.0944 2019-03-28
002607 002607 0.2200 6.237000e+09 1.153000e+09 0.5472 1.1967 0.7189 0.2209 0.5908 0.1848 2019-04-09
002959 002959 2.0611 2.041000e+09 1.855000e+08 0.2396 0.2657 0.5055 0.2075 0.3251 0.0909 2019-07-15
300107 300107 1.1996 1.418000e+09 6.560000e+08 1.6467 6.5338 0.5202 0.4661 0.6379 0.4625 2019-03-15
300618 300618 3.6900 2.782000e+09 7.076000e+08 0.8994 0.5746 0.4965 0.2504 0.4530 0.2531 2019-04-26
300776 300776 3.3900 3.649000e+08 1.679000e+08 1.2059 1.5013 0.7122 0.2651 0.6207 0.4602 2019-02-18
300792 300792 2.7100 1.013000e+09 1.626000e+08 0.4378 0.1799 0.4723 0.3797 0.4259 0.1606 2019-09-16
600399 600399 2.0100 5.848000e+09 2.607000e+09 0.1732 2.9493 9.6467 0.2979 0.1453 0.4459 2019-03-29
600408 600408 0.8100 8.816000e+09 8.202000e+08 0.3957 3.9094 0.7501 0.1681 0.1535 0.1020 2019-03-22
600423 600423 0.9000 2.009000e+09 3.903000e+08 0.0975 5.3411 1.6695 0.1264 0.1404 0.1871 2019-03-19
600507 600507 2.0800 1.729000e+10 2.927000e+09 0.2396 0.1526 0.5817 0.3216 0.3287 0.1696 2019-02-22
600678 600678 0.0900 4.240000e+08 3.168000e+07 1.2925 0.0948 0.7213 0.0689 0.2183 0.0742 2019-03-14
600793 600793 1.6568 1.293000e+09 1.745000e+08 0.1164 0.8868 0.7490 0.0486 0.1622 0.1350 2019-04-30
600870 600870 0.0087 3.096000e+07 4.554000e+06 0.7773 1.3702 0.7458 0.0724 0.2688 0.1675 2019-03-30
601003 601003 1.7987 4.735000e+10 4.610000e+09 0.1394 0.7420 0.5264 0.1920 0.1439 0.0974 2019-03-29
603379 603379 2.9400 4.454000e+09 1.108000e+09 0.1423 0.1609 0.5476 0.3547 0.3959 0.2488 2019-03-13
以上,基本上就可以应付大部分日常数据的使用了。
如果你想扩展数据,可以参考详细文档里的数据部分。
在介绍系统设计的二维索引多标的计算模型之前,我们先来介绍一种自由(solo)的策略模式。 所谓策略回测,无非就是,重复以下过程:
因为系统所有的数据都是时间序列数据,有着统一的查询方式,通过query_data可以快速得到符合条件的标的,所以,即使只会query_data,也可以solo一把了。
class MySoloTrader(StockTrader):
def on_time(self, timestamp):
# 增持5000股以上,买买买
long_df = ManagerTrading.query_data(start_timestamp=timestamp, end_timestamp=timestamp,
filters=[ManagerTrading.volume > 5000], columns=[ManagerTrading.entity_id],
order=ManagerTrading.volume.desc(), limit=10)
# 减持5000股以上,闪闪闪
short_df = ManagerTrading.query_data(start_timestamp=timestamp, end_timestamp=timestamp,
filters=[ManagerTrading.volume < -5000],
columns=[ManagerTrading.entity_id],
order=ManagerTrading.volume.asc(), limit=10)
if pd_is_not_null(long_df) or pd_is_not_null(short_df):
try:
self.trade_the_targets(due_timestamp=timestamp, happen_timestamp=timestamp,
long_selected=set(long_df['entity_id'].to_list()),
short_selected=set(short_df['entity_id'].to_list()))
except Exception as e:
self.logger.error(e)
你可以发挥想象力,社保重仓买买买,外资重仓买买买,董事长跟小姨子跑了卖卖卖......
然后,刷新一下http://127.0.0.1:8050/,看你运行策略的performance
更多可参考策略例子
简单的计算可以通过query_data来完成,这里说的是系统设计的二维索引多标的计算模型。
下面以技术因子为例对计算流程进行说明:
In [7]: from zvt.factors.technical_factor import *
In [8]: factor = BullFactor(codes=['000338','601318'],start_timestamp='2019-01-01',end_timestamp='2019-06-10', transformer=MacdTransformer())
data_df为factor的原始数据,即通过query_data从数据库读取到的数据,为一个二维索引DataFrame
In [11]: factor.data_df
Out[11]:
level high id entity_id open low timestamp close
entity_id timestamp
stock_sh_601318 2019-01-02 1d 54.91 stock_sh_601318_2019-01-02 stock_sh_601318 54.78 53.70 2019-01-02 53.94
2019-01-03 1d 55.06 stock_sh_601318_2019-01-03 stock_sh_601318 53.91 53.82 2019-01-03 54.42
2019-01-04 1d 55.71 stock_sh_601318_2019-01-04 stock_sh_601318 54.03 53.98 2019-01-04 55.31
2019-01-07 1d 55.88 stock_sh_601318_2019-01-07 stock_sh_601318 55.80 54.64 2019-01-07 55.03
2019-01-08 1d 54.83 stock_sh_601318_2019-01-08 stock_sh_601318 54.79 53.96 2019-01-08 54.54
... ... ... ... ... ... ... ... ...
stock_sz_000338 2019-06-03 1d 11.04 stock_sz_000338_2019-06-03 stock_sz_000338 10.93 10.74 2019-06-03 10.81
2019-06-04 1d 10.85 stock_sz_000338_2019-06-04 stock_sz_000338 10.84 10.57 2019-06-04 10.73
2019-06-05 1d 10.92 stock_sz_000338_2019-06-05 stock_sz_000338 10.87 10.59 2019-06-05 10.59
2019-06-06 1d 10.71 stock_sz_000338_2019-06-06 stock_sz_000338 10.59 10.49 2019-06-06 10.65
2019-06-10 1d 11.05 stock_sz_000338_2019-06-10 stock_sz_000338 10.73 10.71 2019-06-10 11.02
[208 rows x 8 columns]
factor_df为transformer对data_df进行计算后得到的数据,设计因子即对transformer进行扩展,例子中用的是MacdTransformer()。
In [12]: factor.factor_df
Out[12]:
level high id entity_id open low timestamp close diff dea macd
entity_id timestamp
stock_sh_601318 2019-01-02 1d 54.91 stock_sh_601318_2019-01-02 stock_sh_601318 54.78 53.70 2019-01-02 53.94 NaN NaN NaN
2019-01-03 1d 55.06 stock_sh_601318_2019-01-03 stock_sh_601318 53.91 53.82 2019-01-03 54.42 NaN NaN NaN
2019-01-04 1d 55.71 stock_sh_601318_2019-01-04 stock_sh_601318 54.03 53.98 2019-01-04 55.31 NaN NaN NaN
2019-01-07 1d 55.88 stock_sh_601318_2019-01-07 stock_sh_601318 55.80 54.64 2019-01-07 55.03 NaN NaN NaN
2019-01-08 1d 54.83 stock_sh_601318_2019-01-08 stock_sh_601318 54.79 53.96 2019-01-08 54.54 NaN NaN NaN
... ... ... ... ... ... ... ... ... ... ... ...
stock_sz_000338 2019-06-03 1d 11.04 stock_sz_000338_2019-06-03 stock_sz_000338 10.93 10.74 2019-06-03 10.81 -0.121336 -0.145444 0.048215
2019-06-04 1d 10.85 stock_sz_000338_2019-06-04 stock_sz_000338 10.84 10.57 2019-06-04 10.73 -0.133829 -0.143121 0.018583
2019-06-05 1d 10.92 stock_sz_000338_2019-06-05 stock_sz_000338 10.87 10.59 2019-06-05 10.59 -0.153260 -0.145149 -0.016223
2019-06-06 1d 10.71 stock_sz_000338_2019-06-06 stock_sz_000338 10.59 10.49 2019-06-06 10.65 -0.161951 -0.148509 -0.026884
2019-06-10 1d 11.05 stock_sz_000338_2019-06-10 stock_sz_000338 10.73 10.71 2019-06-10 11.02 -0.137399 -0.146287 0.017776
[208 rows x 11 columns]
result_df为可用于选股器的二维索引DataFrame,通过对data_df或factor_df计算来实现。 该例子在计算macd之后,利用factor_df,黄白线在0轴上为True,否则为False,具体代码
In [14]: factor.result_df
Out[14]:
score
entity_id timestamp
stock_sh_601318 2019-01-02 False
2019-01-03 False
2019-01-04 False
2019-01-07 False
2019-01-08 False
... ...
stock_sz_000338 2019-06-03 False
2019-06-04 False
2019-06-05 False
2019-06-06 False
2019-06-10 False
[208 rows x 1 columns]
不同类型Factor的result_df格式如下:
- filter类型

- score类型

结合选股器和回测,整个流程如下:

git clone https://github.com/zvtvz/zvt.git
设置项目的virtual env(python>=3.6),安装依赖
pip3 install -r requirements.txt
pip3 install pytest
pycharm导入工程(推荐,你也可以使用其他ide),然后pytest跑测试案例
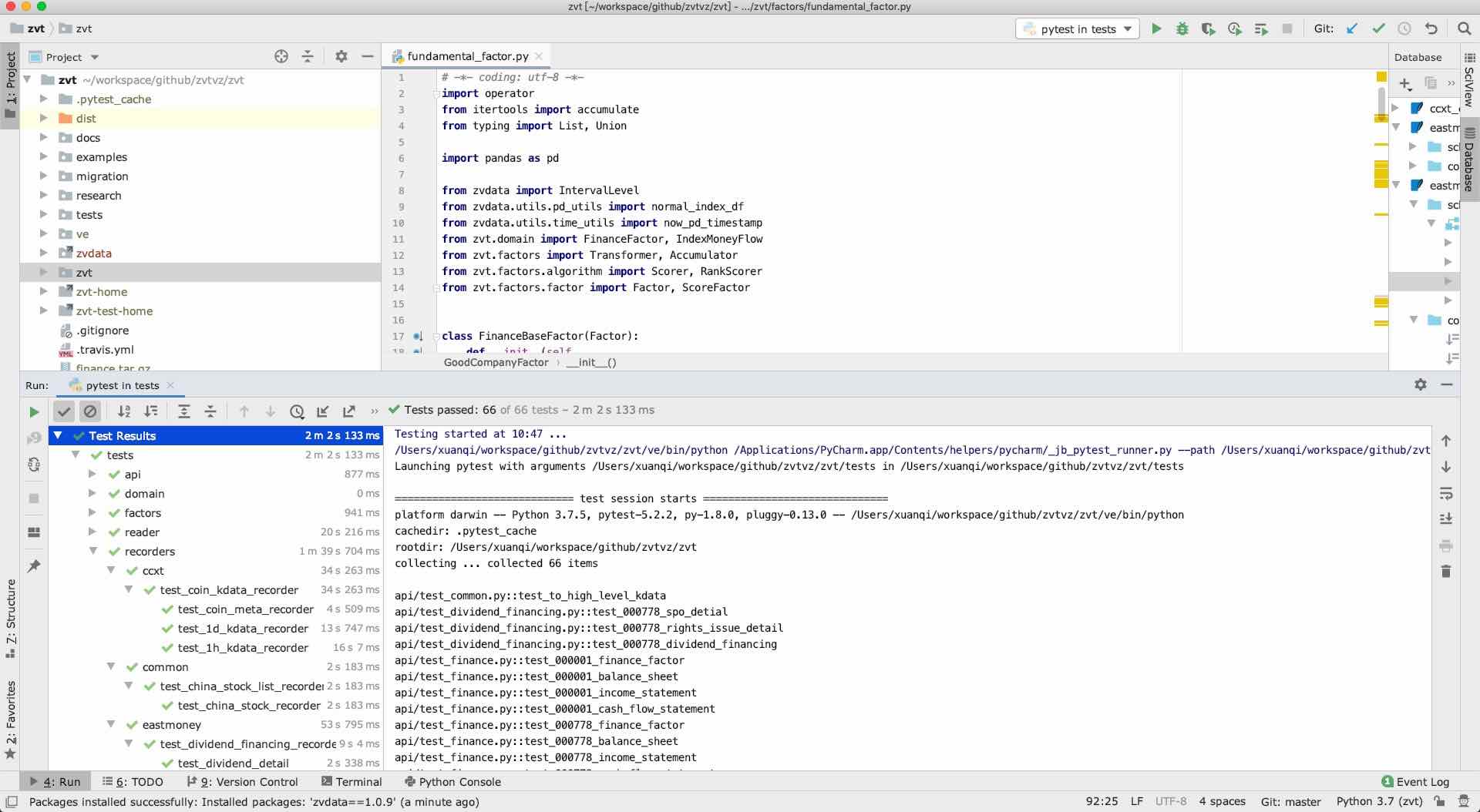
大部分功能使用都可以从tests里面参考
- 丰富全面开箱即用可扩展可持续增量更新的数据
- A股数据:行情,财务报表,大股东行为,高管交易,分红融资详情,个股板块资金流向,融资融券,龙虎榜等数据
- 市场整体pe,pb,资金流,融资融券,外资动向等数据
- 数字货币数据
- 数据的标准化,多数据源(provider)交叉验证,补全
- 简洁可扩展的数据框架
- 统一简洁的API,支持sql查询,支持pandas
- 可扩展的factor,对单标的和多标的的运算抽象了一种统一的计算方式
- 支持多标的,多factor,多级别的回测方式
- 支持交易信号和策略使用到的factor的实时可视化
- 支持多种实盘交易(实现中)
期待能有更多的开发者参与到 zvt 的开发中来,我会保证尽快 Reivew PR 并且及时回复。但提交 PR 请确保
先看一下1分钟代码规范
- 通过所有单元测试,如若是新功能,请为其新增单元测试
- 遵守开发规范
- 如若需要,请更新相对应的文档
也非常欢迎开发者能为 zvt 提供更多的示例,共同来完善文档。
如果你觉得项目对你有帮助,可以请作者喝杯咖啡


加微信进群:foolcage 添加暗号:zvt

微信公众号:

知乎专栏:
https://zhuanlan.zhihu.com/automoney
