Spindle is Brandon Amos' 2014 summer internship project with Adobe Research and is not under active development.

Analytics platforms such as Adobe Analytics are growing to process petabytes of data in real-time. Delivering responsive interfaces querying this amount of data is difficult, and there are many distributed data processing technologies such as Hadoop MapReduce, Apache Spark, Apache Drill, and Cloudera Impala to build low-latency query systems.
Spark is part of the Apache Software Foundation and claims speedups up to 100x faster than Hadoop for in-memory processing. Spark is shifting from a research project to a production-ready library, and academic publications and presentations from the 2014 Spark Summit archives several use cases of Spark and related technology. For example, NBC Universal presents their use of Spark to query HBase tables and analyze an international cable TV video distribution here. Telefonica presents their use of Spark with Cassandra for cyber security analytics here. ADAM is an open source data storage format and processing pipeline for genomics data built in Spark and Parquet.
Even though people are publishing use cases of Spark, few people have published experiences of building and tuning production-ready Spark systems. Thorough knowledge of Spark internals and libraries that interoperate well with Spark is necessary to achieve optimal performance from Spark applications.
Spindle is a prototype Spark-based web analytics query engine designed around the requirements of production workloads. Spindle exposes query requests through a multi-threaded HTTP interface implemented with Spray. Queries are processed by loading data from Apache Parquet columnar storage format on the Hadoop distributed filesystem.
This repo contains the Spindle implementation and benchmarking scripts to observe Spindle's performance while exploring Spark's tuning options. Spindle's goal is to process petabytes of data on thousands of nodes, but the current implementation has not yet been tested at this scale. Our current experimental results use six nodes, each with 24 cores and 21g of Spark memory, to query 13.1GB of analytics data. The trends show that further Spark tuning and optimizations should be investigated before attempting larger scale deployments.
We used Spindle to generate static webpages that are hosted statically here. Unfortunately, the demo is only for illustrative purposes and is not running Spindle in real-time.


Grunt is used to deploy demo to Github pages
in the gh-pages branch with the grunt-build-control plugin.
The npm dependencies are managed in package.json
and can be installed with npm install.
The load-sample-data directory contains a Scala program
to load the following sample data into HDFS
modeled after
adobe-research/spark-parquet-thrift-example.
See adobe-research/spark-parquet-thrift-example
for more information on running this application
with adobe-research/spark-cluster-deployment.
| post_pagename | user_agent | visit_referrer | post_visid_high | post_visid_low | visit_num | hit_time_gmt | post_purchaseid | post_product_list | first_hit_referrer |
|---|---|---|---|---|---|---|---|---|---|
| Page A | Chrome | http://facebook.com | 111 | 111 | 1 | 1408007374 | http://google.com | ||
| Page B | Chrome | http://facebook.com | 111 | 111 | 1 | 1408007377 | http://google.com | ||
| Page C | Chrome | http://facebook.com | 111 | 111 | 1 | 1408007380 | purchase1 | ;ProductID1;1;40;,;ProductID2;1;20; | http://google.com |
| Page B | Chrome | http://google.com | 222 | 222 | 1 | 1408007379 | http://google.com | ||
| Page C | Chrome | http://google.com | 222 | 222 | 1 | 1408007381 | http://google.com | ||
| Page A | Firefox | http://google.com | 222 | 222 | 1 | 1408007382 | http://google.com | ||
| Page A | Safari | http://google.com | 333 | 333 | 1 | 1408007383 | http://facebook.com | ||
| Page B | Safari | http://google.com | 333 | 333 | 1 | 1408007386 | http://facebook.com |
| post_pagename | user_agent | visit_referrer | post_visid_high | post_visid_low | visit_num | hit_time_gmt | post_purchaseid | post_product_list | first_hit_referrer |
|---|---|---|---|---|---|---|---|---|---|
| Page A | Chrome | http://facebook.com | 111 | 111 | 1 | 1408097374 | http://google.com | ||
| Page B | Chrome | http://facebook.com | 111 | 111 | 1 | 1408097377 | http://google.com | ||
| Page C | Chrome | http://facebook.com | 111 | 111 | 1 | 1408097380 | purchase1 | ;ProductID1;1;60;,;ProductID2;1;100; | http://google.com |
| Page B | Chrome | http://google.com | 222 | 222 | 1 | 1408097379 | http://google.com | ||
| Page A | Safari | http://google.com | 333 | 333 | 1 | 1408097383 | http://facebook.com | ||
| Page B | Safari | http://google.com | 333 | 333 | 1 | 1408097386 | http://facebook.com |
| post_pagename | user_agent | visit_referrer | post_visid_high | post_visid_low | visit_num | hit_time_gmt | post_purchaseid | post_product_list | first_hit_referrer |
|---|---|---|---|---|---|---|---|---|---|
| Page A | Chrome | http://facebook.com | 111 | 111 | 1 | 1408187380 | purchase1 | ;ProductID1;1;60;,;ProductID2;1;100; | http://google.com |
| Page B | Chrome | http://facebook.com | 111 | 111 | 1 | 1408187380 | purchase1 | ;ProductID1;1;200; | http://google.com |
| Page D | Chrome | http://google.com | 222 | 222 | 1 | 1408187379 | http://google.com | ||
| Page A | Safari | http://google.com | 333 | 333 | 1 | 1408187383 | http://facebook.com | ||
| Page B | Safari | http://google.com | 333 | 333 | 1 | 1408187386 | http://facebook.com | ||
| Page C | Safari | http://google.com | 333 | 333 | 1 | 1408187388 | http://facebook.com |
Spindle includes eight queries that are representative of the data sets and computations of real queries the Adobe Marketing Cloud processes. All collect statements refer to the combined filter and map operation, not the operation to gather an RDD as a local Scala object.
- Q0 (Pageviews) is a breakdown of the number of pages viewed each day in the specified range.
- Q1 (Revenue) is the overall revenue for each day in the specified range.
- Q2 (RevenueFromTopReferringDomains) obtains the top referring
domains for each visit and breaks down the revenue by day.
The
visit_referrerfield is preprocessed into each record in the raw data. - Q3 (RevenueFromTopReferringDomainsFirstVisitGoogle) is
the same as RevenueFromTopReferringDomains, but with the
visitor's absolute first referrer from Google.
The
first_hit_referrerfield is preprocessed into each record in the raw data. - Q4 (TopPages) is a breakdown of the top pages for the entire date range, not per day.
- Q5 (TopPagesByBrowser) is a breakdown of the browsers used for TopPages.
- Q6 (TopPagesByPreviousTopPages) breaks down the top previous pages a visitor was at for TopPages.
- Q7 (TopReferringDomains) is the top referring domains for the entire date range, not per day.
The following table shows the columnar subset each query utilizes.

The following table shows the operations each query performs and is intended as a summary rather than full description of the implementations. The bold text in indicate operations in which the target partition size is specified, which is further described in the "Partitioning" section below.

The query engine provides a request and response interface to interact with the application layer, and Spindle's goal is to benchmark a realistic low latency web analytics query engine.
Spindle provides query requests and reports over HTTP with the Spray library, which is multi-threaded and provides REST/HTTP-based integration layer on Scala for queries and parameters, as illustrated in the figure below.
When a user request to execute a query over HTTP,
Spray allocates a thread to process the HTTP request and converts
it into a Spray request.
The Spray request follows a route defined in the QueryService Actor,
and queries are processed with the QueryProcessor singleton object.
The QueryProcessor interacts with a global Spark context,
which connects the Scala application to the Spark cluster.
The Spark context supports multi-threading and offers a
FIFO and FAIR scheduling options for concurrent queries.
Spindle uses Spark's FAIR scheduling option to minimize overall latency.
Spindle's architecture can likely be improved on larger clusters by utilizing a job server or resource manager to maintain a pool of Spark contexts for query execution. Ooyala's spark-jobserver provides a RESTful interface for submitting Spark jobs that Spindle could interface with instead of interfacing with Spark directly. YARN can also be used to manage Spark's resources on a cluster, as described in this article.
However, allocating resources on the cluster raises additional questions and engineering work that Spindle can address in future work. Spindle's current architecture coincides HDFS and Spark workers on the same nodes, minimizing the network traffic required to load data. How much will the performance degrade if the resource manager allocates some subset of Spark workers that don't coincide with any of the HDFS data being accessed?
Furthermore, how would a production-ready caching policy on a pool of Spark Contexts look? What if many queries are being submitted and executed on different Spark Contexts that use the same data? Scheduling the queries on the same Spark Context and caching the data between query executions would substantially increase the performance, but how should the scheduler be informed of this information?
Adobe Analytics events data have at least 250 columns, and sometimes significantly more than 250 columns. Most queries use less than 7 columns, and loading all of the columns into memory to only use 7 is inefficient. Spindle stores event data in the Parquet columnar store on the Hadoop Distributed File System (HDFS) with Kryo serialization enabled to only load the subsets of columns each query requires.
Cassandra is a NoSQL database that we considered as an alternate to Parquet. However, Spindle also utilizes Spark SQL, which supports Parquet, but not Cassandra.
Parquet can be used with Avro or Thrift schemas. Matt Massie's article provides an example of using Parquet with Avro. adobe-research/spark-parquet-thrift-example is a complete Scala/sbt project using Thrift for data serialization and shows how to only load the specified columnar subset. For a more detailed introduction to Thrift, see Thrift: The Missing Guide.
The entire Adobe Analytics schema cannot be published. The open source release of Spindle uses AnalyticsData.thrift, which contains 10 non-proprietary fields for web analytics.
Columns postprocessed into the data after collection have the post_
prefix along with visit_referrer and first_hit_referrer.
Visitors are categorized by concatenating the strings
post_visid_high and post_visid_low.
A visitor has visits which are numbered by visit_num,
and a visit has hits that occur at hit_time_gmt.
If the hit is a webpage hit from a browser, the post_pagename and
user_agent fields are used, and the revenue from a hit,
is denoted in post_purchaseid and post_product_list.
struct AnalyticsData {
1: string post_pagename;
2: string user_agent;
3: string visit_referrer;
4: string post_visid_high;
5: string post_visid_low;
6: string visit_num;
7: string hit_time_gmt;
8: string post_purchaseid;
9: string post_product_list;
10: string first_hit_referrer;
}This data is separated by day on disk of format YYYY-MM-DD.
Spindle provides a caching option that will cache the loaded Spark data in memory between query requests to show the maximum speedup caching provides. Caching introduces a number of interesting questions when dealing with sparse data. For example, two queries could be submitted on the same date range that request overlapping, but not identical, column subsets. How should these data sets with partially overlapping values be cached in the application? What if one of the queries is called substantially more times than the other? How should the caching policy ensure these columns are not evicted? We will explore these questions in future work.
Spark affords partitioning data across nodes for operations
such as distinct, reduceByKey, and groupByKey to specify the
minimum number of resulting partitions.
Counting the number of records in an RDD expensive, and automatically knowing the optimal number of partitions for operations depends highly on the data and operations. For optimal partitioning, applications should estimate the number of records to process and ensure the partitions contain some minimum value of records.
Spindle puts a target number of records in each partition
by estimating the total number of records to be processed
from Parquet's metadata.
However, most queries filter records before doing operations that
impact the partitioning by approximately 50% in our data.
For example, an empty post_pagename field indicates that the
analytics hit is from an event other than a user visiting a page,
and the first Spark operation in TopPages is to obtain only
the page visit hits by filtering out records with empty post_pagename
fields.
 |
 |
|---|
Spark 1.0.0 can be deployed to traditional cloud and job management services such as EC2, Mesos, or Yarn. Further, Spark's standalone cluster mode enables Spark to run on other servers without installing other job management services.
However, configuring and submitting applications to a Spark 1.0.0 standalone cluster currently requires files to be synchronized across the entire cluster, including the Spark installation directory. These problems have motivated our adobe-research/spark-cluster-deployment project, which utilizes Fabric and Puppet to further automate the Spark standalone cluster.
Ensure you have the following software on the server. Spindle has been developed on CentOS 6.5 with sbt 0.13.5, Spark 1.0.0, Hadoop 2.0.0-cdh4.7.0, and parquet-thrift 1.5.0.
| Command | Output |
|---|---|
cat /etc/centos-release |
CentOS release 6.5 (Final) |
sbt --version |
sbt launcher version 0.13.5 |
thrift --version |
Thrift version 0.9.1 |
hadoop version |
Hadoop 2.0.0-cdh4.7.0 |
cat /usr/lib/spark/RELEASE |
Spark 1.0.0 built for Hadoop 2.0.0-cdh4.7.0 |
Spindle uses sbt and the sbt-assembly plugin
to build Spark into a fat JAR to be deployed to the Spark cluster.
Using adobe-research/spark-cluster-deployment,
modify config.yaml to have your server configurations,
and build the application with ss-a, send the JAR to your cluster
with ss-sy, and start Spindle with ss-st.
All experiments leverage a homogeneous six node production cluster of HP ProLiant DL360p Gen8 blades. Each node has 32GB of DDR3 memory at 1333MHz, (2) 6 core Intel Xeon 0 processors at 2.30GHz and 1066MHz FSB, and (10) 15K SAS 146GB, RAID 5 hard disks. Furthermore, each node has CentOS 6.5, Hadoop 2.0.0-cdh4.7.0, Spark 1.0.0, sbt 0.13.5, and Thrift 0.9.1. The Spark workers each utilizes 21g of memory.
These experiments benchmark Spindle's queries on a week's worth of data consuming 13.1G as serialized Thrift objects in Parquet.
The YAML formatted results, scripts, and resulting figures are in the [benchmark-scripts][benchmark-scripts] directory.
Predicting the optimal resource allocation to minimize query latency for distributed applications is difficult. No production software can accurately predict the optimal number of Spark and HDFS nodes for a given application. This experiment observes the execution time of queries as the number of Spark and HDFS workers is increased. We manually scale and rebalance the HDFS data.
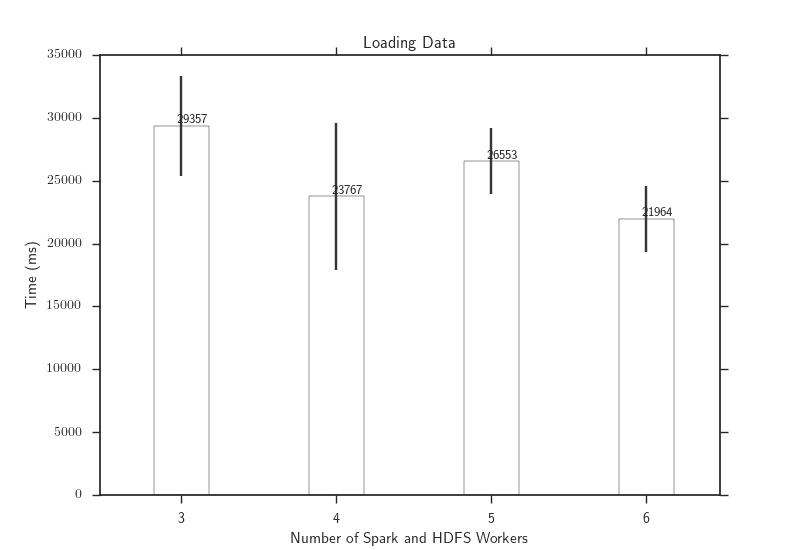
The following figure shows the time to load all columns the queries
use for the week of data as the Spark and HDFS workers are scaled. The data is
loaded by caching the Spark RDD and performing a null operation on them, such
as rdd.cache.foreach{x =>{}}. The downward trend of the data load times
indicate that using more Spark or HDFS workers will decrease the time to load
data.
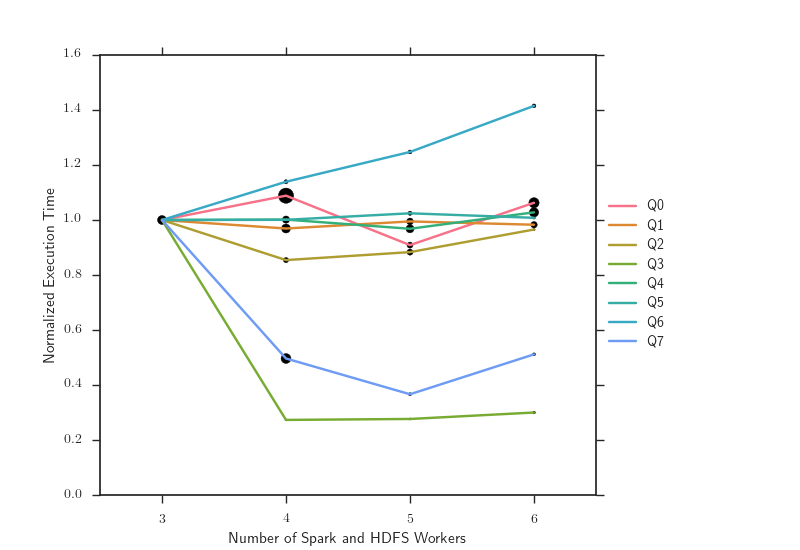
The following table and plot show the execution time of the queries with cached data when scaling the HDFS and Spark workers. The bold data indicates where adding a Spark and HDFS worker hurts performance. The surprising results show that adding a single Spark or HDFS worker commonly hurts query performance, and interestingly, no query experiences minimal execution time when using all 6 workers. Our future work is to further experiment by tuning Spark to understand the performance degradation, which might be caused by network traffic or imbalanced workloads.
Q2 and Q3 are similar queries and consequently have similar performance as scaling the Spark and HDFS workers, but has an anomaly when using 3 workers where Q2 executes in 17.10s and Q3 executes in 55.15s. Q6’s execution time increases by 10.67 seconds between three and six Spark and HDFS workers.

Spark cannot optimize the number of records in the partitions because counting the number of records in the initial and intermediate data sets is expensive, and the Spark application has to provide the number of partitions to use for certain computations. This experiment fully utilizes all six nodes with Spark (144 cores) and HDFS workers.
Averaging four execution times for each point between 10,000 and 1,500,000 target partition sizes for every query results in similar performance to the TopPages query (Q4) shown below.

Targeting 10,000 records per partition results in poor performance, which we suspect is due to the Spark overhead of creating an execution environment for the task, and the performance monotonically decreases and levels off at a target partition size of 1,500,000. This experiment fully utilizes all six nodes with Spark (144 cores) and HDFS workers.
The table below summarizes the results from all queries by showing the best average execution times for all partitions and the execution time at a target partition size of 1,500,000. Q2 and Q3 have nearly identical performance because Q3 only adds a filter to Q2.
| Query | Best Execution Time (s) | Final Execution Time (s) |
|---|---|---|
| TopPages | 3.31 | 3.37 |
| TopPagesByBrowser | 15.41 | 15.58 |
| TopPagesByPreviousTopPages | 34.70 | 36.89 |
| TopReferringDomains | 5.68 | 5.68 |
| RevenueFromTopReferringDomains | 16.66 | 16.661 |
| RevenueFromTopReferringDomainsFirstVisitGoogle | 16.89 | 16.89 |
The remaining experiments use a target partition size of 1,500,000, and the performance is the best observed for the operations with partitioning. We expect the support for specifying partitioning for loading Parquet data from HDFS will yield further performance results.
This experiment shows the ideal speedups from having all the data in memory as RDD's. Furthermore, the performances from caching in this experiment are better than the performances from caching the raw data in memory because the RDD is cached, and the time to load raw data into a RDD is non-negligible.
The figure below shows the average execution times from four trials
of every query with and without caching.
Caching the data substantially improves performance, but
reveals that Spindle has further performance bottlenecks inhibiting
subsecond query execution time.
These bottlenecks can be partially overcome by preprocessing the data
and further analyzing Spark internals.

Spindle's can process concurrent queries with multi-threading, since many users will use the analytics application concurrently. Users will request different queries concurrently, but for simplicity, this experiment shows the performance degradation as the same query is called with an increasing number of threads with in-memory caching.
This experiment will spawn a number of threads which continuously execute the same query. Each thread remains loaded and continues processing queries until all threads have processed four queries, and the average execution time of the first four queries from every thread will be used as a metric to estimate the slowdowns.
The performance of the TopPages query below is indicative of the performance of most queries. TopPages appears to underutilize the Spark system when processing in serial, and the Spark schedule is able to process two queries concurrently and return them as a factor of 1.32 of the original execution time.

The slowdown factors from serial execution are shown in the table below for two and eight concurrent queries.
| Query | Serial Time (ms) | 2 Concurrent Slowdown | 8 Concurrent Slowdown |
|---|---|---|---|
| Pageviews | 2.70 | 1.63 | 5.98 |
| TopPages | 3.37 | 1.32 | 5.66 |
| TopPagesByBrowser | 15.93 | 2.02 | 7.58 |
| TopPagesByPreviousTopPages | 37.49 | 1.24 | 4.15 |
| Revenue | 2.74 | 1.53 | 5.82 |
| TopReferringDomains | 5.75 | 1.19 | 4.45 |
| RevenueFromTopReferringDomains | 17.79 | 1.55 | 5.91 |
| RevenueFromTopReferringDomainsFirstVisitGoogle | 16.35 | 1.68 | 7.29 |
This experiment shows the ability of Spark's scheduler at the small scale of six nodes. The slowdowns for two concurrent queries indicate further query optimizations could better balance the work between all Spark workers and likely result in better query execution time.
Spindle is not currently under active development by Adobe. However, we are happy to review and respond to issues, questions, and pull requests.
Bundled applications are copyright their respective owners. Twitter Bootstrap and dangrossman/bootstrap-daterangepicker are Apache 2.0 licensed and rlamana/Terminus is MIT licensed. Diagrams are available in the public domain from bamos/beamer-snippets.
All other portions are copyright 2014 Adobe Systems Incorporated
under the Apache 2 license, and a copy is provided in LICENSE.