
In this project, I wrote a software pipeline that identifies lane boundaries in a specific video taken from a front facing camera mounted on a vehicle. Frames from the video were taken and used to extract enough information while creating this pipeline. All details in this pipeline can be seen in this depository. The entire code of this pipeline can be found in this Jupyter Notebook.
camera_cal: Compilation of chessboards images for camera calibration purposeoutput_images: Compilation of output images from each step of pipelinetest_images: Compilation of test images taken from video to extract informationvideos: Compilation of test video and output result of pipeline
- Camera lenses are prone to inherent distortions that can affect its perception of the real world.
- Taking account of this problem, as a starting step, camera calibration function will be applied so the car will get an accurate observation of the environment to navigate safely.
- Here, OpenCV's
cv2.findChessboardCorners()andcv2.calibrateCamera()are used to get information for calibration purpose.
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
found, corners = cv2.findChessboardCorners(gray, (nx,ny), None)
objpoints = [] # for 3d points in real world
imgpoints = [] # for 2d points in image world
if found:
objpoints.append(objp)
imgpoints.append(corners)
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
- Corners found during calibration attempt will return a few parameters, including
mtxanddist, which will be useful for the following step.
- This step is crucial to ensure that the geometrical shape of objects are represented consistently, no matter where they appear in the image.
- To achieve this, OpenCV function
cv2.undistort()are applied to compute the calibration of camera and undistortion using Matrix,mtx, value and distortion coefficient,dist, obtained from step one. - Below is the original image(before) and its undistorted image(after), after applying both step 1 and 2 of pipeline.

- Below is the result of calibration done on a test image taken from the video.

- Gradients and color spaces taken off of an image offer great advantages to find pixels that form the lines in the video.
- In this step a gradient threshold using
cv2.Sobeloperator in x the direction are used since it does a cleaner job to pick up the lane lines in the image.
hls = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
satchannel = hls[:,:,2] # saturation channel
# Sobel of x-axis direction using saturation channel
sobelx = cv2.Sobel(satchannel, cv2.CV_64F, 1, 0, 3) # calculate derivative in x direction
absox = np.absolute(sobelx) # magnitude derivative to stand out from horizontal (y-axis)
scaledsobelx = np.uint8(255*absox/np.max(absox)) # convert value image to 8-bit
# Threshold sobel channel
sobelxbinary = np.zeros_like(scaledsobelx)
sobelxbinary[(scaledsobelx >= gradientthres[0]) & (scaledsobelx <= gradientthres[1])] = 1
- In combination of the Sobel operator, a threshold of S channel of HLS color space are also taken to filter out better look of the lines.
# Threshold saturation channel
satbinary = np.zeros_like(satchannel)
satbinary[(satchannel >= satthres[0]) & (satchannel <= satthres[1])] = 1
# COMBINE
combined = np.zeros_like(satchannel)
combined[(sobelxbinary == 1) | (satbinary == 1)] = 1
- Below is the output of a transformed image after step 1, 2, and 3.

- This step maps 4 points(makes Region of Interest) in a test image to a different(desired) angle with a new perspective. The transformation that is beneficial for this project is the birds's-eye view transform. ROI are defined below:
height, width = img.shape[:2]
# 4 points for original image
src = np.float32([
[width//2-76, height*0.625],
[width//2+76, height*0.625],
[-100, height],
[width+100, height]
])
# 4 points for destination image
dst = np.float32([
[100, 0],
[width-100, 0],
[100, height],
[width-100, height]
])
- Here, OpenCV function
cv2.getPerspectiveTransform()andcv2.warpPerspective()are used to transform the area of the ROI to a top-down view.
imgsize = (img.shape[1], img.shape[0])
Matrix = cv2.getPerspectiveTransform(src, dst)
warped = cv2.warpPerspective(img, Matrix, imgsize, flags=cv2.INTER_NEAREST) # keep same size as input image
- Below is the result of a bird's-eye view of one of the ROI of a test image taken from the video.

-
After step 4, the final result of the image will be in binary image(no color channel) where the lane lines stand out very clearly. However, to decide explicitly the exact pixels that make the lines, I used the histogram method to find 2 most prominent peaks and regard them as left and right.
-
An in-depth introduction about this method can be found in the Lesson 8 : Advanced Computer Vision from the Udacity's Self-Driving Car Nanodegree.
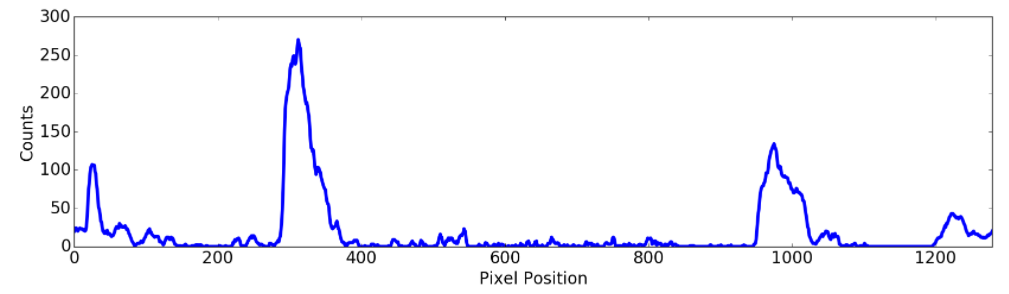
histogram = np.sum(binarywarped[binarywarped.shape[0]//2:,:], axis=0) # histogram of bottom half of image
output = np.dstack((binarywarped, binarywarped, binarywarped))
# Find peak on left and right as starting point of windows creation
midbottom = np.int(histogram.shape[0]//2)
leftbottom = np.argmax(histogram[:midbottom])
rightbottom = np.argmax(histogram[midbottom:]) + midbottom
# Window parameters
winnum, winwidth, minpix = 8, 100, 50 # minpix to recenter windows
winheight = np.int(binarywarped.shape[0]//winnum)
# Find (x,y) of all nonzero(non-black) pixels
nonzero = binarywarped.nonzero()
nonzerox, nonzeroy = nonzero[1], nonzero[0]
# For update when windows going up
newleft = leftbottom
newright = rightbottom
# Create list to store left and right indices
leftlaneinds = []
rightlaneinds = []
- This method will be repeated a number of times, and each time will create a window that specifies the 2 peaks in the particular region of the image.
for win in range(winnum):
# Set (x,y) boundaries for left and right windows
ylow = binarywarped.shape[0] - (win + 1)*winheight
yhigh = binarywarped.shape[0] - win*winheight
xleftlow = newleft - winwidth
xlefthigh = newleft + winwidth
xrightlow = newright - winwidth
xrighthigh = newright + winwidth
# Draw windows
cv2.rectangle(output, (xleftlow, ylow), (xlefthigh, yhigh), (0,255,0), 2)
cv2.rectangle(output, (xrightlow, ylow), (xrighthigh, yhigh), (0,255,0), 2)
# Find nonzeros(nonblack) pixels in windows
goodleft = ((nonzeroy > ylow) & (nonzeroy < yhigh) & (nonzerox > xleftlow) & (nonzerox < xlefthigh)).nonzero()[0]
goodright = ((nonzeroy > ylow) & (nonzeroy < yhigh) & (nonzerox > xrightlow) & (nonzerox < xrighthigh)).nonzero()[0]
# Append indices to lists
leftlaneinds.append(goodleft)
rightlaneinds.append(goodright)
- Below is the result of 8 repeated histogram for 8 windows on a test image.

- The output from the last windows then will be feed into a function that will produce a sliding window by utilizing a numpy function,
np.polyfit, that takes both side's coordinates and fit a second order polynomial for each, demonstrated by image below.

- To avoid keep making unnecessary number of sliding windows for each image(since a video might have thousands of images or even more), the previous polynomial will be used to skip the sliding windows and instead, use it to fit a polynomial to all the relevant pixels found in the sliding windows.
# Generate y coordinate
ploty = np.linspace(0, output.shape[0] - 1, output.shape[0])
# MUST define conversion in x and y from pixel to real world METERS (U.S. highway regulations)
ymperpixel = 30/720 # lane is about 30m long in the projection video
xmperpixel = 3.7/800 # lane width is 3.7m wide, 720 is pixels in y axis
# Create new polynomials to x and y in world space
leftcurve = np.polyfit(ploty*ymperpixel, leftx*xmperpixel, 2)
rightcurve = np.polyfit(ploty*ymperpixel, rightx*xmperpixel, 2)
- Lane curvature, or radius, are calculated to find the lane boundary. In-depth tutorial for finding it can be found here.
- The radius calculated previously will be fed into the this step, which will draw a boundary using OpenCV's
cv2.fillPoly() - This step also will take the final output and unwarp(return to the perspective before bird's-eye view) it to prepare for the following step.
- Result of this step are shown below.

- Curvature radius and vehicle position metrics calculated in the code below will be visualized in the result taken from step 7.
# Calculate radius of curvature
leftradius = ((1 + (2*leftcurve[0]*np.max(ploty)*ymperpixel + leftcurve[1])**2)**1.5)/np.absolute(2*leftcurve[0])
rightradius = ((1 + (2*rightcurve[0]*np.max(ploty)*ymperpixel + rightcurve[1])**2)**1.5)/np.absolute(2*rightcurve[0])
# Average radius
radius = np.average([leftradius, rightradius])
# From center
midimage = output.shape[1]//2
# Car position with respect to camera center
carposition = (leftx[-1] + rightx[-1]/2)
# Car offset
center = (midimage-carposition)*xmperpixel
cv2.putText(finaloutput, 'Radius of curvature: {:.2f} m'.format(radius),
(60,60), cv2.FONT_HERSHEY_DUPLEX, 1.5, (255,255,0), 5)
cv2.putText(finaloutput, 'Car distance from center : {:.2f} m'.format(center),
(60,120), cv2.FONT_HERSHEY_DUPLEX, 1.5, (255,255,0), 5)
- Shown below is the result of this step.

- Finally, all of the functions created from step 1 to 8 above will be put together in the
ProcessVideo()class. - The entire class can be viewed below:
class ProcessVideo:
def __init__(self, images):
images = glob.glob(images) # Create a list of images
# Calibrate camera
self.ret, self.mtx, self.dist, self.rvecs, self.tvecs = calibratecamera(images)
def __call__(self, img):
undist = undistort(img, self.mtx, self.dist)
colortransformed = colortransform(undist)
warpedimg = warp(colortransformed)
output, leftx, lefty, rightx, righty, leftfitx, rightfitx = slidingpoly(warpedimg)
makeboundary = drawboundary(img, warpedimg, leftfitx, rightfitx)
finaloutput = drawtext(leftfitx, rightfitx, makeboundary)
return finaloutput
- To run the pipeline on a video, I used
VideoFileClipfrommoviepy.editoras per shown below.
from moviepy.editor import VideoFileClip
def buildvideo(pathprefix):
outputname = 'videos/{}_result.mp4'.format(pathprefix)
inputname = VideoFileClip('videos/{}.mp4'.format(pathprefix))
processresult = ProcessVideo('./camera_cal/calibration*.jpg')
white_clip = inputname.fl_image(processresult)
%time white_clip.write_videofile(outputname, audio=False)
- A gif version of the result was also created and is shown at the top of this README.
-
The parameters used in this pipeline were highly influenced by the lighting in the environment, road status and especially fainted line paint or even shadows emerged from the environment. This makes it more challenging when there is change in the weather condition in any particular time in a day.
-
In this final result (video can be found here) This video shows that some parts of the road will affect the parameters set in the pipeline thus resulting in inconsistent output boundaries.
-
Most of the time that the model did not perform well were when there was some form of shadows emerging on the road.
-
One improvement that could produce a cleaner and smoother result would be to create a model that could help enhance lane lines apart from emerging shadows.
-
Lastly, thank you for your time taken for viewing this project. I had a nice time writing it! Please share your thoughts or suggestions if/where applicable. Have a nice day!