Description
We're in a process of migration from older hardware under ClickHouse to the newer generation.
Older machines have 12x6T disks, 128GB RAM and 2x10G NICs, newer machines have 12x10T disks, 256GB RAM and 2x25G NICs. Dataset per replica is around 35TiB. Each shard is 3 replicas.
Our process is:
- Stop one replica from shard.
- Clear it from zookeeper.
- Remove it from cluster topology (znode update for
remote_servers). - Add new replica to cluster topology.
- Start new replica and let it replicate all the data from peers.
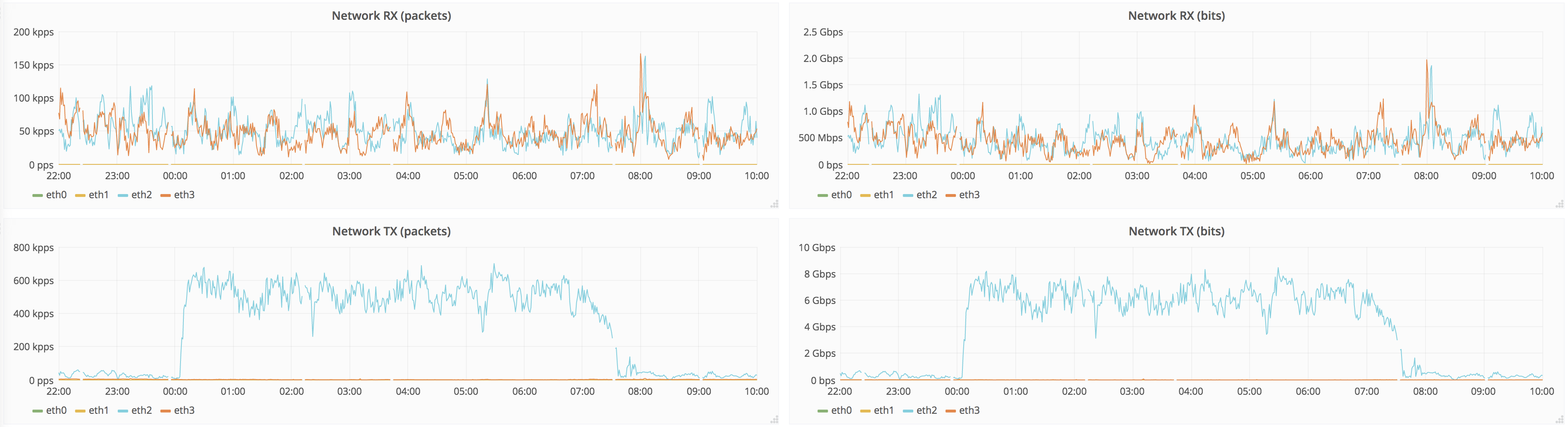
The issue we're seeing is that source replicas saturate disks, starving user queries and merges.
It takes ~7h to replicate full dataset, below are the graphs for 12h around that time:
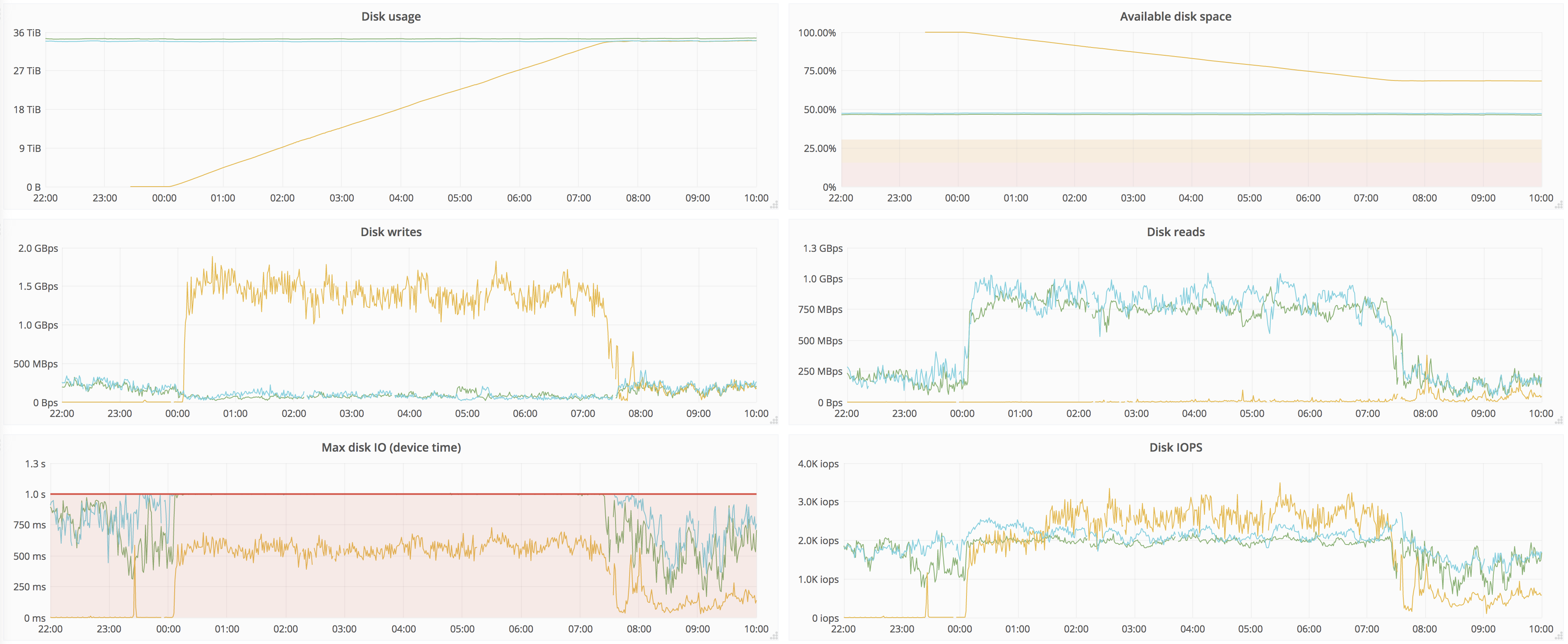


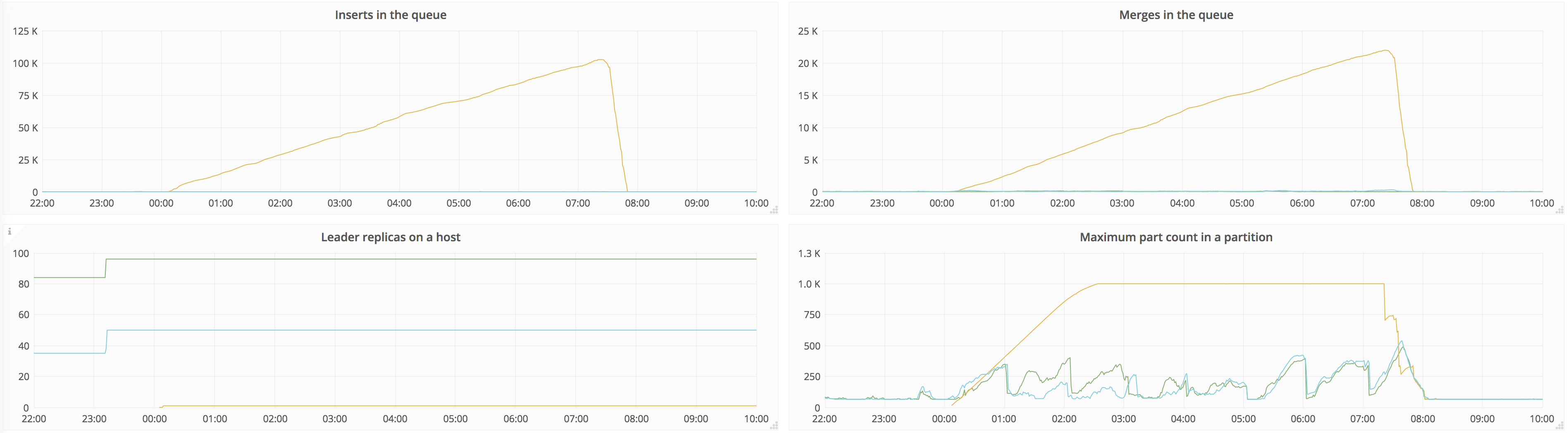

Source peer:
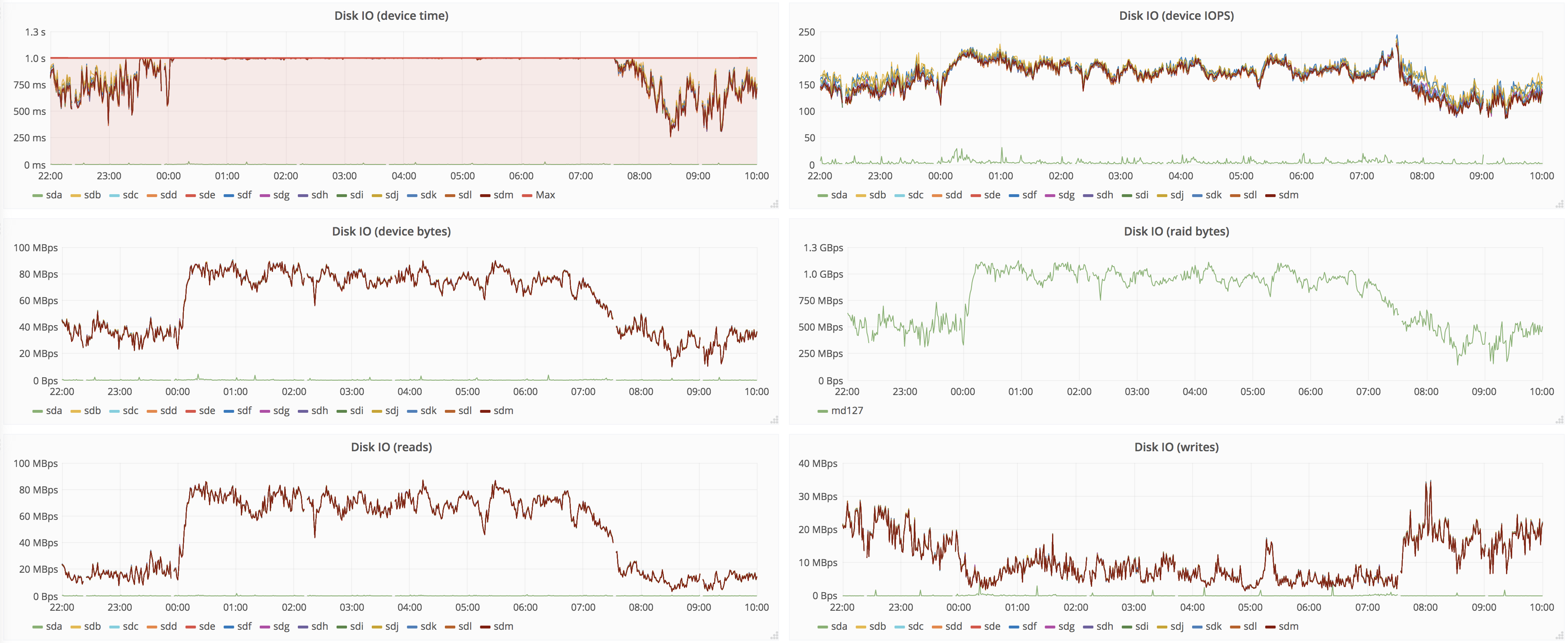
Target peer:
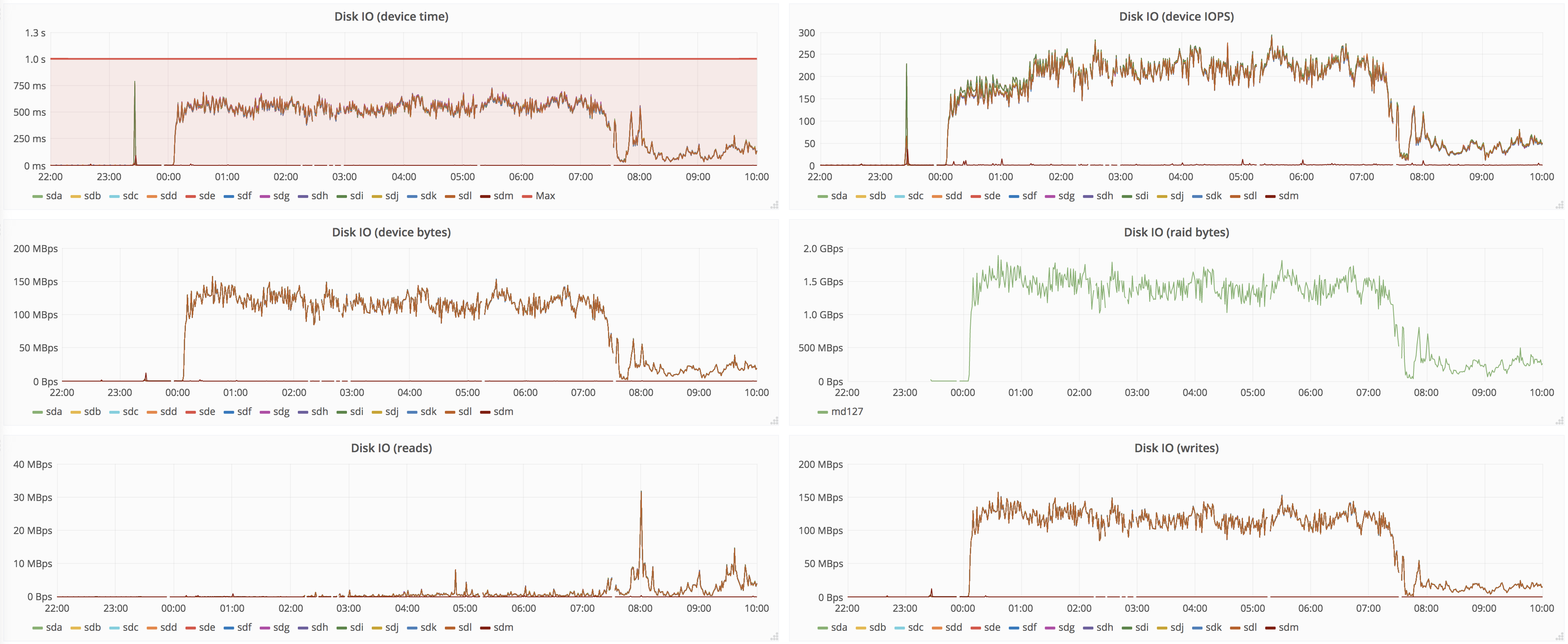
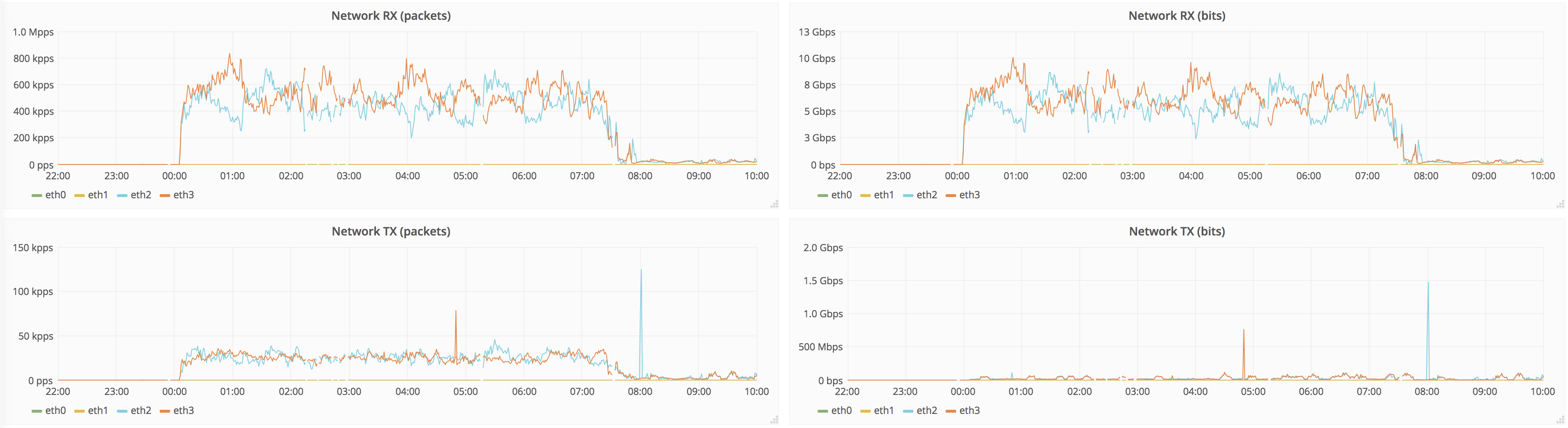
Naturally, source peers are not great at IO in the first place (that's why we're upgrading), but having 7h of degraded service is not great. It'd be nice to be able to set recovery speed, so it doesn't starve other activities like user queries and merges.
Moreover, max number of parts in partition quickly reaches the max (we set to 1000) on the target replica, where inserts are throttled, which doesn't make things any better. With throttled recovery at lower speed but with higher duration, this will probably be even longer period. Maybe we should split threads that do merges and threads that do replication, it seems like whole pool is busy just replicating.
It is also possible that we're just doing it wrong, then it'd be great to have a guide describing the process.